Layer Wise Training #11081
Comments
|
👋 Hello @Enverrrr, thank you for your interest in YOLOv5 🚀! Please visit our ⭐️ Tutorials to get started, where you can find quickstart guides for simple tasks like Custom Data Training all the way to advanced concepts like Hyperparameter Evolution. If this is a 🐛 Bug Report, please provide a minimum reproducible example to help us debug it. If this is a custom training ❓ Question, please provide as much information as possible, including dataset image examples and training logs, and verify you are following our Tips for Best Training Results. RequirementsPython>=3.7.0 with all requirements.txt installed including PyTorch>=1.7. To get started: git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # installEnvironmentsYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
Status
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training, validation, inference, export and benchmarks on MacOS, Windows, and Ubuntu every 24 hours and on every commit. Introducing YOLOv8 🚀We're excited to announce the launch of our latest state-of-the-art (SOTA) object detection model for 2023 - YOLOv8 🚀! Designed to be fast, accurate, and easy to use, YOLOv8 is an ideal choice for a wide range of object detection, image segmentation and image classification tasks. With YOLOv8, you'll be able to quickly and accurately detect objects in real-time, streamline your workflows, and achieve new levels of accuracy in your projects. Check out our YOLOv8 Docs for details and get started with: pip install ultralytics |


I'm sorry I couldn't find solutions |
|
@glenn-jocher could you help me please |
|
👋 Hello! Thanks for asking about CUDA memory issues. YOLOv5 🚀 can be trained on CPU, single-GPU, or multi-GPU. When training on GPU it is important to keep your batch-size small enough that you do not use all of your GPU memory, otherwise you will see a CUDA Out Of Memory (OOM) Error and your training will crash. You can observe your CUDA memory utilization using either the
CUDA Out of Memory SolutionsIf you encounter a CUDA OOM error, the steps you can take to reduce your memory usage are:
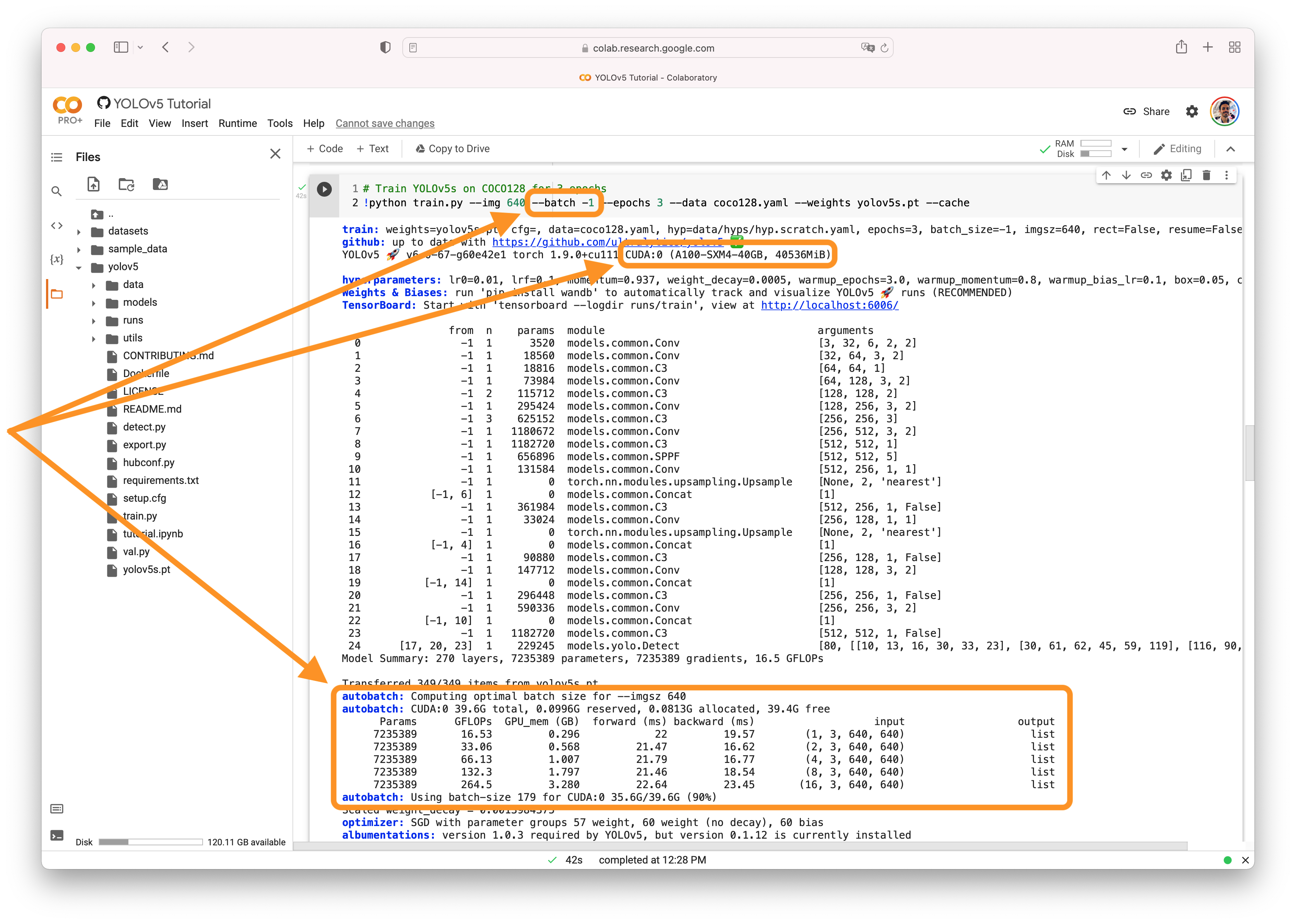
AutoBatchYou can use YOLOv5 AutoBatch (NEW) to find the best batch size for your training by passing
Good luck 🍀 and let us know if you have any other questions! |

|
Thanks for your advice. |
|
@Enverrrr that's an unorthodox approach but yes you can use the --freeze command to freeze the first x layers, i.e. |
I couldn't explain myself I think, I just want to get 1 single weight after training. I mean first of all I need to train backbone and then train other parts of the network with the helps of --freeze command in single run. |
|
@glenn-jocher Hey I've question for you I don't use freeze method and train all the networks gpu memory is 3142MB according to nvidia-smi. When I am freezing 18 layers from 6 to 24 and gpu memory is 3118MB according to nvidia-smi. Could it be smaller than first situation. I mean yes it is smaller but wouldn't the difference be more? |
|
@Enverrrr Yes, freezing layers can indeed result in a smaller memory footprint, but the extent of the reduction depends on various factors such as the size of the frozen layers and the specific operations performed within those layers. It's not uncommon for the reduction to be less than expected. Additionally, other factors such as the size of the model, batch size, and input image size can also influence GPU memory utilization. If your goal is to minimize memory usage, you may need to further experiment with different combinations of frozen layers and training settings to achieve the desired outcome. |
Search before asking
Question
Hello,
I need to train network by split it 'cause I have little free memory. I've tried how to solve it however I couldn't find any solutions.
Are there any documents I missed out?
Additional
No response
The text was updated successfully, but these errors were encountered: