YOLOv5 support model-parallel training with multi gpu? #6523
Comments
|
👋 Hello @p890040, thank you for your interest in YOLOv5 🚀! Please visit our ⭐️ Tutorials to get started, where you can find quickstart guides for simple tasks like Custom Data Training all the way to advanced concepts like Hyperparameter Evolution. If this is a 🐛 Bug Report, please provide screenshots and minimum viable code to reproduce your issue, otherwise we can not help you. If this is a custom training ❓ Question, please provide as much information as possible, including dataset images, training logs, screenshots, and a public link to online W&B logging if available. For business inquiries or professional support requests please visit https://ultralytics.com or email support@ultralytics.com. RequirementsPython>=3.7.0 with all requirements.txt installed including PyTorch>=1.7. To get started: git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # installEnvironmentsYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
Status
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training (train.py), validation (val.py), inference (detect.py) and export (export.py) on MacOS, Windows, and Ubuntu every 24 hours and on every commit. |


|
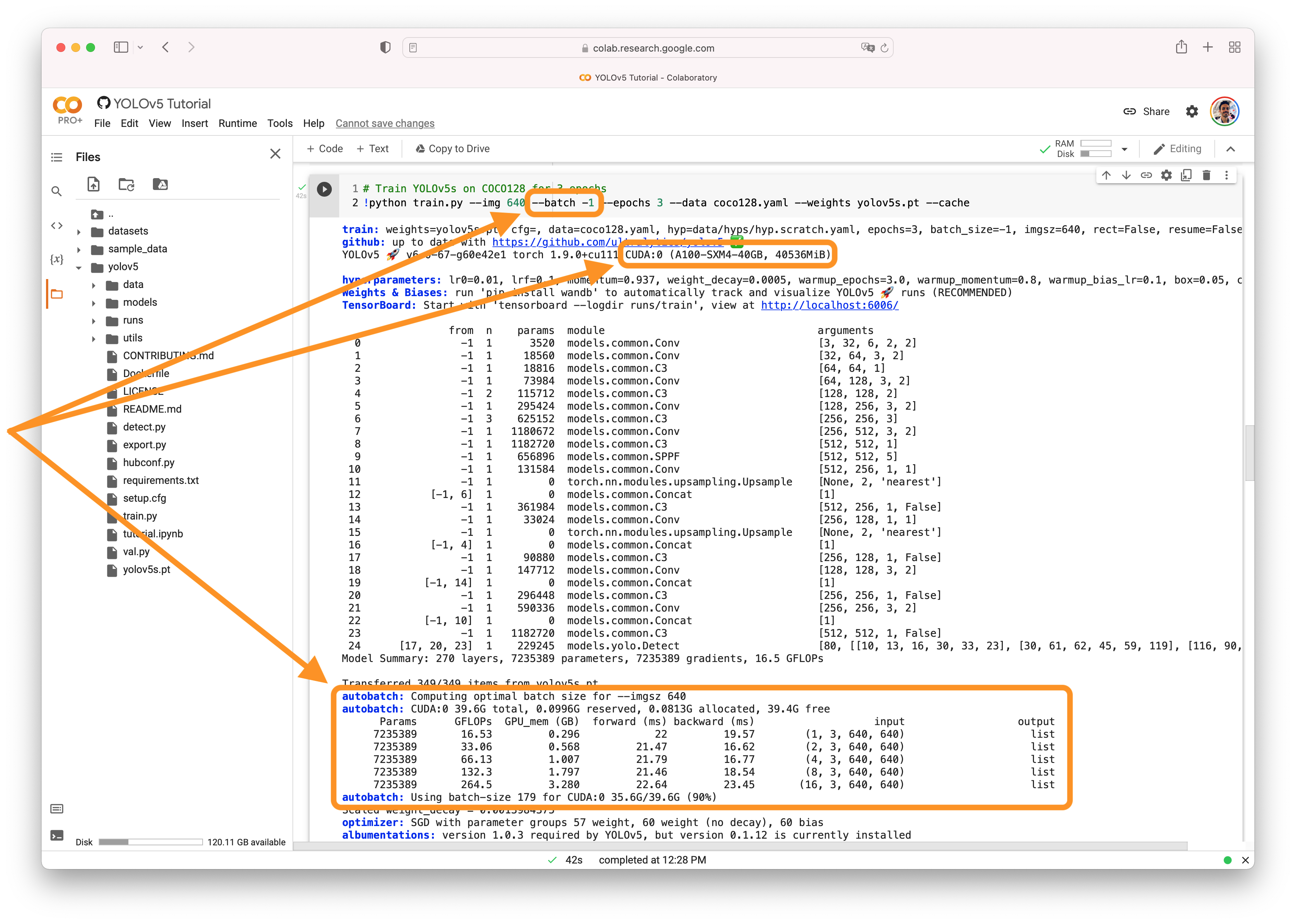
@p890040 👋 Hello! Thanks for asking about CUDA memory issues. YOLOv5 🚀 can be trained on CPU, single-GPU, or multi-GPU. When training on GPU it is important to keep your batch-size small enough that you do not use all of your GPU memory, otherwise you will see a CUDA Out Of Memory (OOM) Error and your training will crash. You can observe your CUDA memory utilization using either the
CUDA Out of Memory SolutionsIf you encounter a CUDA OOM error, the steps you can take to reduce your memory usage are:
AutoBatchYou can use YOLOv5 AutoBatch (NEW) to find the best batch size for your training by passing
Good luck 🍀 and let us know if you have any other questions! |

|
Thanks for your detailed explanation! Let me elaborate more on what my friend @p890040 and I encountered problems, and we will be grateful if you can give us some hints! Recently we got a dataset that the model could get a good performance on it after we adjusted a higher input size. My train of thought is that suppose training a single image with input size 3360 on YOLOv5x6 weight will account for 50GB GPU memory. I want to allocate 25 GB memory for first A100 GPU, and allocate the rest of 25 GB memory for second A100 GPU. As far as I know, PyTorch DDP could combine with Model Parallelism ref. I am wondering does YOLOv5 support this feature? Or is there any tip for us to handle the large input size situation? Thank you in advance! Best regards, |
|
No there is no model parallelism support currently. It looks like on a single device YOLOv5x6 at --img 3840 will use about 53GB of CUDA memory, so you should be fine to train at 3360 on a single 40GB device.
|

|
@glenn-jocher |
|
@p890040 hi, thank you for your feature suggestion on how to improve YOLOv5 🚀! Yes this might be a useful addition, though I think parallelism is typically more used in language models where the parameter count can run into the billions. The fastest and easiest way to incorporate your ideas into the official codebase is to submit a Pull Request (PR) implementing your idea, and if applicable providing before and after profiling/inference/training results to help us understand the improvement your feature provides. This allows us to directly see the changes in the code and to understand how they affect workflows and performance. Please see our ✅ Contributing Guide to get started. |
|
Thanks for your reply and testing! BR, |
Search before asking
Question
Hi guys!
I have a question about this.
Does yolov5 provide model-parallel training with multi gpu?
I have checked Multi-GPU Training tutorial and issues.
I found no one was talking about this function.
Because I have two GPU and wanna set img_size larger, and batch size 1 is still OOM.
So I'm trying some way to achieve it.
Thanks!
Additional
No response
The text was updated successfully, but these errors were encountered: