提示:
此页面包含高级材料。如果您是一名初级 Pine Script™ 程序员,我们建议您在冒险之前熟悉其他更易于使用的 Pine Script™ 功能。
Pine Script™ 数组是可以保存多个值引用的一维集合。将它们视为处理需要显式声明一组相似变量(例如price00,,,, ...)price01的情况的更好方法price02。
数组中的所有元素必须属于同一类型,可以是 内置类型或 用户定义类型,始终限定为“系列”。脚本使用类似于行、标签和其他特殊类型的 ID 的数组 ID 来引用数组。 Pine Script™ 不使用索引运算符来引用各个数组元素。相反,包括array.get() 和array.set()在内的函数读取和写入数组元素的值。我们可以在允许“系列”值的表达式和函数中使用数组值。
脚本使用索引引用数组的元素,索引从 0 开始,扩展到数组中元素的数量减一。 Pine Script™ 中的数组可以具有随条形变化的动态大小,因为可以在脚本的每次迭代中更改数组中的元素数量。脚本可以包含多个数组实例。数组的大小限制为 100,000 个元素。
笔记
我们将使用数组的开头来指定索引 0,使用数组的**结尾来指定具有最高索引值的数组元素。为了简洁起见,我们还将扩展数组的含义以包括数组 ID。
Pine Script™ 使用以下语法来声明数组:
[var/varip ][array<type>/<type[]> ]<identifier> = <expression>其中<type>是数组的类型模板,声明它将包含的值的类型,并且<expression>返回指定类型的数组或na.
将变量声明为数组时,我们可以使用array 关键字,后跟类型模板。或者,我们可以使用type名称后跟[]修饰符(不要与[] 历史引用运算符混淆)。
由于 Pine 总是使用特定于类型的函数来创建数组,因此array<type>/type[]声明部分是多余的,除非声明分配给 的数组变量na。即使不需要,显式声明数组类型也有助于向读者清楚地说明意图。
这行代码声明了一个名为 的数组变量,prices该变量指向na.在这种情况下,我们必须指定类型来声明变量可以引用包含“float”值的数组:
array<float> prices = na我们还可以将上面的例子写成这样的形式:
float[] prices = na声明数组且<expression>is not时na,请使用以下函数之一: array.new(size, initial_value)、 array.from()或array.copy()。对于函数,和参数的参数可以是“系列”,以允许动态调整数组元素的大小和初始化。以下示例创建一个包含零个“float”元素的数组,这次,将array.new() 函数调用返回的数组 ID 分配给:array.new<type>(size, initial_value)``size``initial_value``prices
prices = array.new<float>(0)笔记
命名array.*空间还包含用于创建数组的特定于类型的函数,包括 array.new_int()、 array.new_float()、 array.new_bool()、 array.new_color()、 array.new_string()、 array.new_line()、 array .new_linefill()、 array.new_label()、 array.new_box()和 array.new_table()。 array.new ()函数可以创建任何类型的数组,包括用户定义的类型。
initial_value函数的参数允许array.new*用户将数组中的所有元素设置为指定值。如果没有为 提供参数initial_value,则数组将填充na值。
此行声明一个名为 的数组 ID,该数组 IDprices指向包含两个元素的数组,每个元素都分配给条的 close值:
prices = array.new<float>(2, close)要创建数组并使用不同的值初始化其元素,请使用 array.from()。该函数根据函数调用中的参数推断数组的大小和它将保存的元素类型。与array.new*函数一样,它接受“系列”参数。提供给函数的所有值必须具有相同的类型。
例如,所有这三行代码将创建具有相同两个元素的相同“bool”数组:
statesArray = array.from(close > open, high != close)
bool[] statesArray = array.from(close > open, high != close)
array<bool> statesArray = array.from(close > open, high != close)用户可以利用var和 varip关键字指示脚本在第一个图表条上的脚本的第一次迭代中仅声明一次数组变量。使用这些关键字声明的数组变量指向相同的数组实例,直到显式重新分配为止,从而允许数组及其元素引用跨柱保留。
当使用这些关键字声明数组变量并将新值推入每个柱上引用数组的末尾时,该数组将在每个柱上增长一,并且在脚本执行时其大小(bar_index从零开始 )最后一栏,如以下代码所示:bar_index + 1
//@version=5
indicator("Using `var`")
//@variable An array that expands its size by 1 on each bar.
var a = array.new<float>(0)
array.push(a, close)
if barstate.islast
//@variable A string containing the size of `a` and the current `bar_index` value.
string labelText = "Array size: " + str.tostring(a.size()) + "\nbar_index: " + str.tostring(bar_index)
// Display the `labelText`.
label.new(bar_index, 0, labelText, size = size.large)没有var关键字的相同代码将在每个柱上重新声明数组。在这种情况下,执行array.push()调用后, a.size()调用将返回值 1。
笔记
使用varip声明的数组变量的行为与在历史数据上使用var 的 行为相同,但它们会在每个新的价格变动时更新实时柱(即自脚本上次编译以来的柱)的值。分配给varip 变量的数组只能保存int、 float、 bool、 color或 string类型或 用户定义类型,这些类型在其字段中专门包含这些类型或这些类型的集合(数组、矩阵或映射)。
脚本可以使用array.set(id, index, value)将值写入现有的各个数组元素 ,并使用array.get(id, index)读取值。使用这些函数时,函数调用中的 必须index始终小于或等于数组的大小(因为数组索引从零开始)。要获取数组的大小,请使用 array.size(id)函数。
以下示例使用set()fillColors方法使用不同透明度级别的一种基色实例填充数组。然后,它使用array.get()根据最后一根柱中价格最高的柱的位置从数组中检索一种颜色lookbackInput:
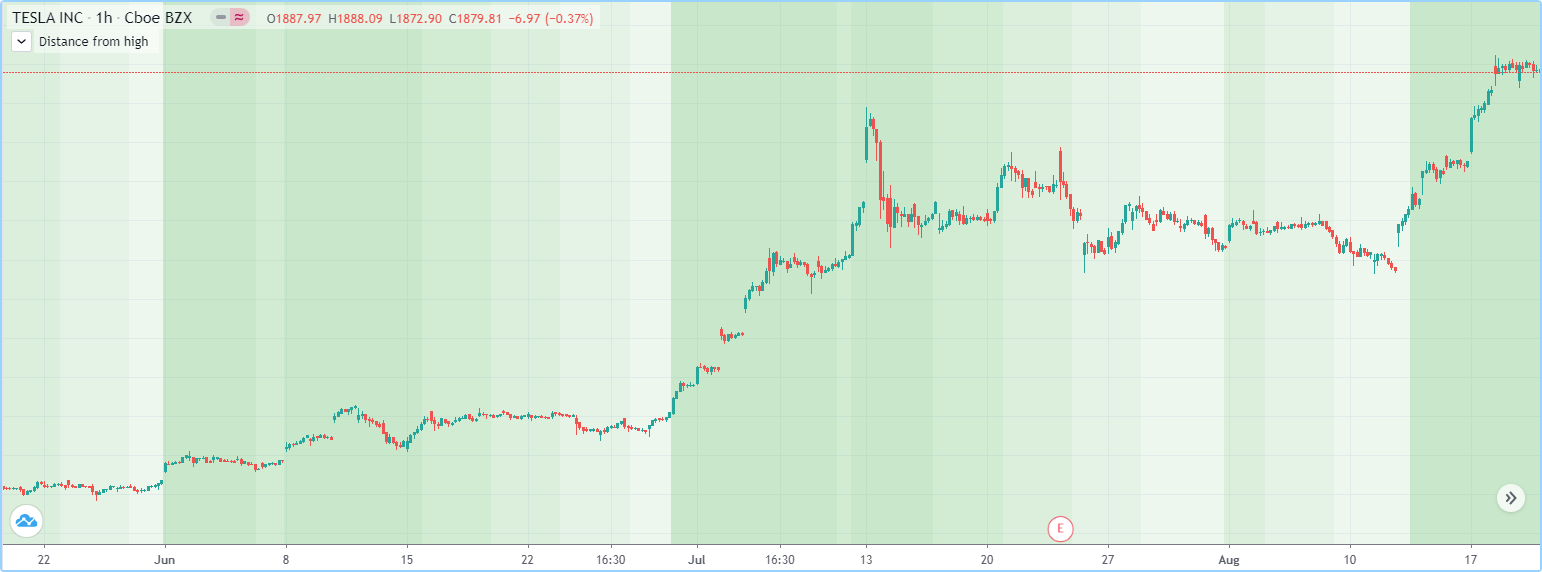
//@version=5
indicator("Distance from high", "", true)
lookbackInput = input.int(100)
FILL_COLOR = color.green
// Declare array and set its values on the first bar only.
var fillColors = array.new<color>(5)
if barstate.isfirst
// Initialize the array elements with progressively lighter shades of the fill color.
fillColors.set(0, color.new(FILL_COLOR, 70))
fillColors.set(1, color.new(FILL_COLOR, 75))
fillColors.set(2, color.new(FILL_COLOR, 80))
fillColors.set(3, color.new(FILL_COLOR, 85))
fillColors.set(4, color.new(FILL_COLOR, 90))
// Find the offset to highest high. Change its sign because the function returns a negative value.
lastHiBar = - ta.highestbars(high, lookbackInput)
// Convert the offset to an array index, capping it to 4 to avoid a runtime error.
// The index used by `array.get()` will be the equivalent of `floor(fillNo)`.
fillNo = math.min(lastHiBar / (lookbackInput / 5), 4)
// Set background to a progressively lighter fill with increasing distance from location of highest high.
bgcolor(array.get(fillColors, fillNo))
// Plot key values to the Data Window for debugging.
plotchar(lastHiBar, "lastHiBar", "", location.top, size = size.tiny)
plotchar(fillNo, "fillNo", "", location.top, size = size.tiny)初始化数组中元素的另一种技术是创建一个空数组(没有元素的数组),然后使用array.push()将新元素追加 到数组末尾,从而将数组的大小增加一每次通话。以下代码在功能上与前面脚本中的初始化部分相同:
// Declare array and set its values on the first bar only.
var fillColors = array.new<color>(0)
if barstate.isfirst
// Initialize the array elements with progressively lighter shades of the fill color.
array.push(fillColors, color.new(FILL_COLOR, 70))
array.push(fillColors, color.new(FILL_COLOR, 75))
array.push(fillColors, color.new(FILL_COLOR, 80))
array.push(fillColors, color.new(FILL_COLOR, 85))
array.push(fillColors, color.new(FILL_COLOR, 90))此代码与上面的代码等效,但它使用array.unshift()在数组的开头 插入新元素fillColors:
// Declare array and set its values on the first bar only.
var fillColors = array.new<color>(0)
if barstate.isfirst
// Initialize the array elements with progressively lighter shades of the fill color.
array.unshift(fillColors, color.new(FILL_COLOR, 90))
array.unshift(fillColors, color.new(FILL_COLOR, 85))
array.unshift(fillColors, color.new(FILL_COLOR, 80))
array.unshift(fillColors, color.new(FILL_COLOR, 75))
array.unshift(fillColors, color.new(FILL_COLOR, 70))我们还可以使用array.from()fillColors通过单个函数调用创建相同的数组:
//@version=5
indicator("Using `var`")
FILL_COLOR = color.green
var array<color> fillColors = array.from(
color.new(FILL_COLOR, 70),
color.new(FILL_COLOR, 75),
color.new(FILL_COLOR, 80),
color.new(FILL_COLOR, 85),
color.new(FILL_COLOR, 90)
)
// Cycle background through the array's colors.
bgcolor(array.get(fillColors, bar_index % (fillColors.size())))array.fill (id, value, index_from, index_to)index_from函数将所有数组元素或to范围 内的元素index_to指向指定的value。如果没有最后两个可选参数,该函数将填充整个数组,因此:
a = array.new<float>(10, close)和:
a = array.new<float>(10)
a.fill(close)是等价的,但是:
a = array.new<float>(10)
a.fill(close, 1, 3)仅用 填充数组的第二个和第三个元素(位于索引 1 和 2 处)close。请注意array.fill()的最后一个参数index_to必须比函数将填充的最后一个索引大 1。其余元素将保存na值,因为 array.new()函数调用不包含initial_value参数。
当循环遍历数组的元素索引并且数组的大小未知时,可以使用 array.size()函数来获取最大索引值。例如:
//@version=5
indicator("Protected `for` loop", overlay = true)
//@variable An array of `close` prices from the 1-minute timeframe.
array<float> a = request.security_lower_tf(syminfo.tickerid, "1", close)
//@variable A string representation of the elements in `a`.
string labelText = ""
for i = 0 to (array.size(a) == 0 ? na : array.size(a) - 1)
labelText += str.tostring(array.get(a, i)) + "\n"
label.new(bar_index, high, text = labelText)-
注意:
我们使用request.security_lower_tf()函数,该函数返回该时间范围内的收盘价数组。
1 minute如果您在小于 的图表时间范围上使用此代码示例,则会引发错误。1 minute``to如果表达式为 na,则不会执行for循环。请注意,该to值仅在输入时评估一次。
循环数组的另一种方法是使用 for...in循环。此方法是标准 for 循环的变体,可以迭代数组中的值引用和索引。下面是我们如何使用循环编写上面的代码示例的示例for...in:
//@version=5
indicator("`for...in` loop", overlay = true)
//@variable An array of `close` prices from the 1-minute timeframe.
array<float> a = request.security_lower_tf(syminfo.tickerid, "1", close)
//@variable A string representation of the elements in `a`.
string labelText = ""
for price in a
labelText += str.tostring(price) + "\n"
label.new(bar_index, high, text = labelText)-
注意:
for…in 循环可以返回一个包含每个索引和相应元素的元组。例如, 返回中每个元素的索引和值。
for [i, price] in a``i``price``a
也可以使用while循环语句:
//@version=5
indicator("`while` loop", overlay = true)
array<float> a = request.security_lower_tf(syminfo.tickerid, "1", close)
string labelText = ""
int i = 0
while i < array.size(a)
labelText += str.tostring(array.get(a, i)) + "\n"
i += 1
label.new(bar_index, high, text = labelText)用户可以在脚本的全局范围内声明数组,也可以在函数、 方法和条件结构的局部范围内声明数组。与其他一些内置类型(即基本类型)不同,脚本可以在本地范围内修改全局分配的数组,从而允许用户实现脚本中的任何函数都可以直接与之交互的全局变量。我们使用此处的功能来计算逐渐降低或升高的价格水平:
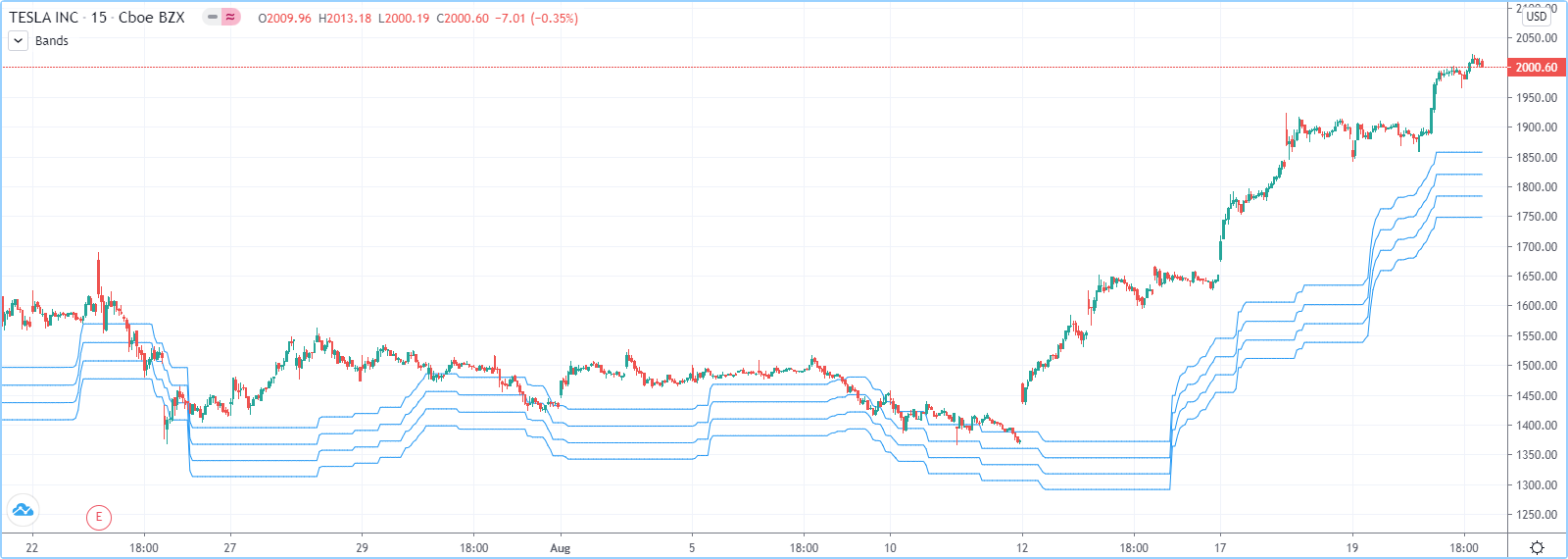
//@version=5
indicator("Bands", "", true)
//@variable The distance ratio between plotted price levels.
factorInput = 1 + (input.float(-2., "Step %") / 100)
//@variable A single-value array holding the lowest `ohlc4` value within a 50 bar window from 10 bars back.
level = array.new<float>(1, ta.lowest(ohlc4, 50)[10])
nextLevel(val) =>
newLevel = level.get(0) * val
// Write new level to the global `level` array so we can use it as the base in the next function call.
level.set(0, newLevel)
newLevel
plot(nextLevel(1))
plot(nextLevel(factorInput))
plot(nextLevel(factorInput))
plot(nextLevel(factorInput))Pine Script™ 的历史引用运算符[ ] 可以访问数组变量的历史记录,从而允许脚本与先前分配给变量的过去数组实例进行交互。
为了说明这一点,让我们创建一个简单的示例来展示如何以close两种等效的方式获取前一柱的值。该脚本使用[ ]运算符获取分配给a前一柱的数组实例,然后使用get() 方法检索第一个元素 ( ) 的值previousClose1。对于previousClose2,我们直接对变量使用历史引用运算符close 来检索值。正如我们从图中看到的,previousClose1两者previousClose2都返回相同的值:

//@version=5
indicator("History referencing")
//@variable A single-value array declared on each bar.
a = array.new<float>(1)
// Set the value of the only element in `a` to `close`.
array.set(a, 0, close)
//@variable The array instance assigned to `a` on the previous bar.
previous = a[1]
previousClose1 = na(previous) ? na : previous.get(0)
previousClose2 = close[1]
plot(previousClose1, "previousClose1", color.gray, 6)
plot(previousClose2, "previousClose2", color.white, 2)以下三个函数可以向数组中插入新元素。
array.unshift() 在数组的开头插入一个新元素(索引 0),并将任何现有元素的索引值加一。
array.insert() 在指定位置插入一个新元素index,并将该位置或之后的现有元素的索引增加index1。

//@version=5
indicator("`array.insert()`")
a = array.new<float>(5, 0)
for i = 0 to 4
array.set(a, i, i + 1)
if barstate.islast
label.new(bar_index, 0, "BEFORE\na: " + str.tostring(a), size = size.large)
array.insert(a, 2, 999)
label.new(bar_index, 0, "AFTER\na: " + str.tostring(a), style = label.style_label_up, size = size.large)array.push() 在数组末尾添加一个新元素。
这四个函数从数组中删除元素。前三个还返回被删除元素的值。
array.remove() 删除指定位置的元素index并返回该元素的值。
array.shift() 从数组中删除第一个元素并返回其值。
array.pop() 删除数组的最后一个元素并返回其值。
array.clear() 从数组中删除所有元素。请注意,清除数组不会删除其元素引用的任何对象。请参阅下面的示例来说明其工作原理:
//@version=5
indicator("`array.clear()` example", overlay = true)
// Create a label array and add a label to the array on each new bar.
var a = array.new<label>()
label lbl = label.new(bar_index, high, "Text", color = color.red)
array.push(a, lbl)
var table t = table.new(position.top_right, 1, 1)
// Clear the array on the last bar. This doesn't remove the labels from the chart.
if barstate.islast
array.clear(a)
table.cell(t, 0, 0, "Array elements count: " + str.tostring(array.size(a)), bgcolor = color.yellow)堆栈是 LIFO(后进先出)结构。它们的行为有点像一堆垂直的书,一次只能添加或删除一本书,而且总是从顶部开始。 Pine Script™ 数组可以用作堆栈,在这种情况下,我们使用 array.push()和 array.pop() 函数在数组末尾添加和删除元素。
array.push(prices, close)将在数组末尾添加一个新元素prices,从而将数组的大小增加一。
array.pop(prices)将从数组中删除末尾元素prices,返回其值并将数组大小减一。
了解此处如何使用这些函数来跟踪反弹中的连续低点:
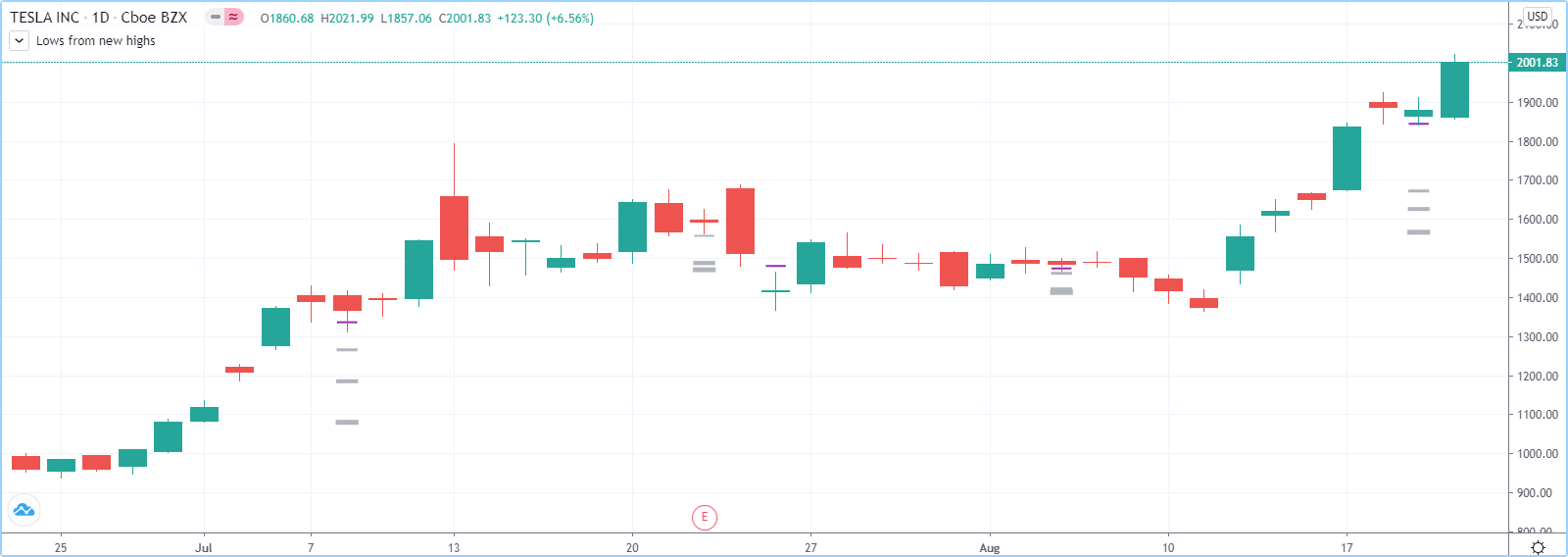
//@version=5
indicator("Lows from new highs", "", true)
var lows = array.new<float>(0)
flushLows = false
// Remove last element from the stack when `_cond` is true.
array_pop(id, cond) => cond and array.size(id) > 0 ? array.pop(id) : float(na)
if ta.rising(high, 1)
// Rising highs; push a new low on the stack.
lows.push(low)
// Force the return type of this `if` block to be the same as that of the next block.
bool(na)
else if lows.size() >= 4 or low < array.min(lows)
// We have at least 4 lows or price has breached the lowest low;
// sort lows and set flag indicating we will plot and flush the levels.
array.sort(lows, order.ascending)
flushLows := true
// If needed, plot and flush lows.
lowLevel = array_pop(lows, flushLows)
plot(lowLevel, "Low 1", low > lowLevel ? color.silver : color.purple, 2, plot.style_linebr)
lowLevel := array_pop(lows, flushLows)
plot(lowLevel, "Low 2", low > lowLevel ? color.silver : color.purple, 3, plot.style_linebr)
lowLevel := array_pop(lows, flushLows)
plot(lowLevel, "Low 3", low > lowLevel ? color.silver : color.purple, 4, plot.style_linebr)
lowLevel := array_pop(lows, flushLows)
plot(lowLevel, "Low 4", low > lowLevel ? color.silver : color.purple, 5, plot.style_linebr)
if flushLows
// Clear remaining levels after the last 4 have been plotted.
lows.clear()队列是 FIFO(先进先出)结构。它们的行为有点像汽车闯红灯。新车在队列末端排队,最先离开的车将是第一个到达红灯的车。
在下面的代码示例中,我们让用户通过脚本的输入决定他们想要在图表上使用多少个标签。我们使用该数量来确定随后创建的标签数组的大小,并将数组的元素初始化为na。
当检测到新的主元时,我们为其创建一个标签,并将标签的 ID 保存在变量中pLabel。然后,我们使用array.push()对该标签的 ID 进行排队 ,将新标签的 ID 附加到数组的末尾,使数组大小比图表上要保留的最大标签数大 1。
最后,我们通过使用array.shift()删除数组的第一个元素 并删除该数组元素的值引用的标签来使最旧的标签出队。由于我们现在已经从队列中出列了一个元素,因此数组pivotCountInput再次包含元素。请注意,在数据集的第一个条上,我们将删除na标签 ID,直到创建了最大数量的标签,但这不会导致运行时错误。让我们看看我们的代码:
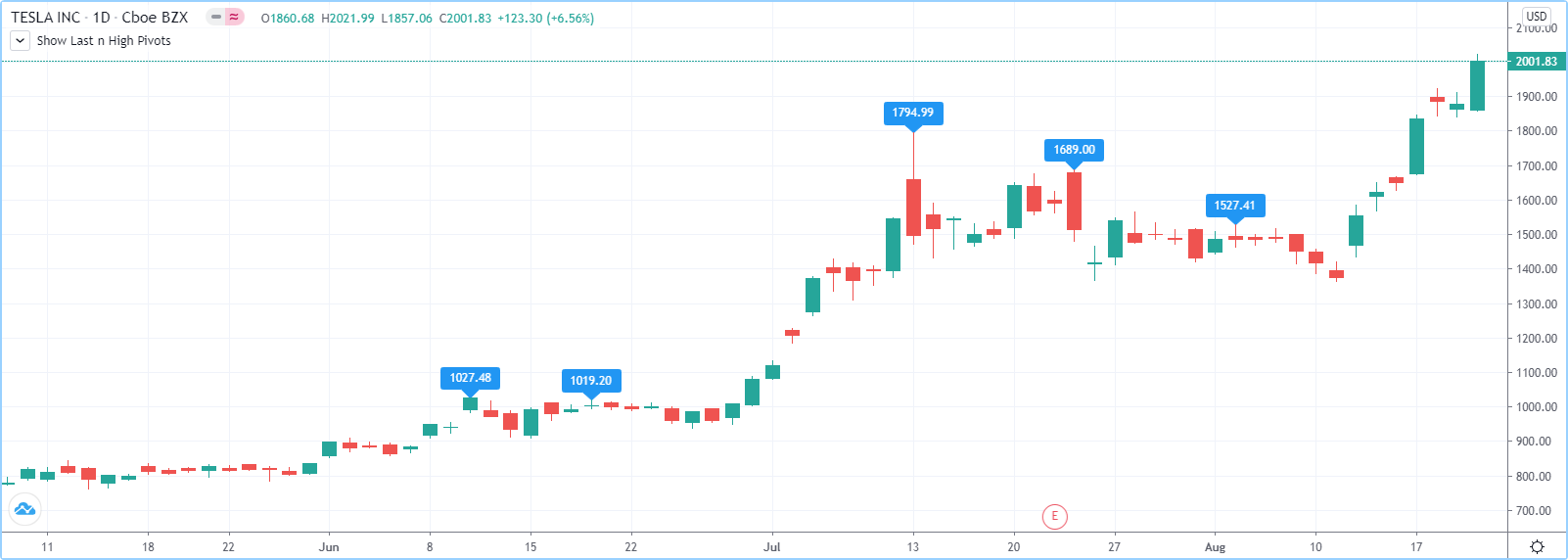
//@version=5
MAX_LABELS = 100
indicator("Show Last n High Pivots", "", true, max_labels_count = MAX_LABELS)
pivotCountInput = input.int(5, "How many pivots to show", minval = 0, maxval = MAX_LABELS)
pivotLegsInput = input.int(3, "Pivot legs", minval = 1, maxval = 5)
// Create an array containing the user-selected max count of label IDs.
var labelIds = array.new<label>(pivotCountInput)
pHi = ta.pivothigh(pivotLegsInput, pivotLegsInput)
if not na(pHi)
// New pivot found; plot its label `i_pivotLegs` bars back.
pLabel = label.new(bar_index[pivotLegsInput], pHi, str.tostring(pHi, format.mintick), textcolor = color.white)
// Queue the new label's ID by appending it to the end of the array.
array.push(labelIds, pLabel)
// De-queue the oldest label ID from the queue and delete the corresponding label.
label.delete(array.shift(labelIds))系列变量可以被视为时间上延伸的一组水平值,而 Pine Script™ 的一维数组可以被视为驻留在每个条形上的垂直结构。由于数组的元素集不是时间序列,因此它们不允许使用 Pine Script™ 通常的数学函数。必须使用专用函数来操作数组的所有值。可用的函数有: array.abs()、 array.avg()、 array.covariance()、 array.min()、 array.max()、 array.median()、 array.mode()、 array.percentile_linear_interpolation ()、 array.percentile_nearest_rank()、 array.percentrank()、 array.range()、 array.standardize()、 array.stdev()、 array.sum()、 array.variance()。
na请注意,与 Pine Script™ 中常见的数学函数相反,当它们计算的某些值具有值时,用于数组的数学函数不会返回na。此规则有一些例外:
- 当所有数组元素都有
na值或数组不包含元素时,na返回。array.standardize()但是,将返回一个空数组。 array.mode()当没有找到模式时将返回na。
可以使用array.concat()合并或连接两个数组。当数组连接时,第二个数组将附加到第一个数组的末尾,因此第一个数组被修改,而第二个数组保持不变。该函数返回第一个数组的数组 ID:

//@version=5
indicator("`array.concat()`")
a = array.new<float>(0)
b = array.new<float>(0)
array.push(a, 0)
array.push(a, 1)
array.push(b, 2)
array.push(b, 3)
if barstate.islast
label.new(bar_index, 0, "BEFORE\na: " + str.tostring(a) + "\nb: " + str.tostring(b), size = size.large)
c = array.concat(a, b)
array.push(c, 4)
label.new(bar_index, 0, "AFTER\na: " + str.tostring(a) + "\nb: " + str.tostring(b) + "\nc: " + str.tostring(c), style = label.style_label_up, size = size.large)您可以使用array.copy()复制数组。这里我们将数组复制a到一个名为 的新数组_b:

//@version=5
indicator("`array.copy()`")
a = array.new<float>(0)
array.push(a, 0)
array.push(a, 1)
if barstate.islast
b = array.copy(a)
array.push(b, 2)
label.new(bar_index, 0, "a: " + str.tostring(a) + "\nb: " + str.tostring(b), size = size.large)请注意,仅在前面的示例中使用不会复制数组,而只会复制其 ID。从那时起,两个变量将指向同一个数组,因此使用任一变量都会影响同一个数组。_b = a
使用array.join()将数组中的所有元素连接成一个字符串,并使用指定的分隔符分隔这些元素:
//@version=5
indicator("")
v1 = array.new<string>(10, "test")
v2 = array.new<string>(10, "test")
array.push(v2, "test1")
v3 = array.new_float(5, 5)
v4 = array.new_int(5, 5)
l1 = label.new(bar_index, close, array.join(v1))
l2 = label.new(bar_index, close, array.join(v2, ","))
l3 = label.new(bar_index, close, array.join(v3, ","))
l4 = label.new(bar_index, close, array.join(v4, ","))包含“int”或“float”元素的数组可以使用array.sort()按升序或降序排序 。该order参数是可选的,默认为order.ascending。与所有array.*()函数参数一样,它被限定为“系列”,因此可以在运行时确定,就像这里所做的那样。请注意,在示例中,对哪个数组进行排序也是在运行时确定的:
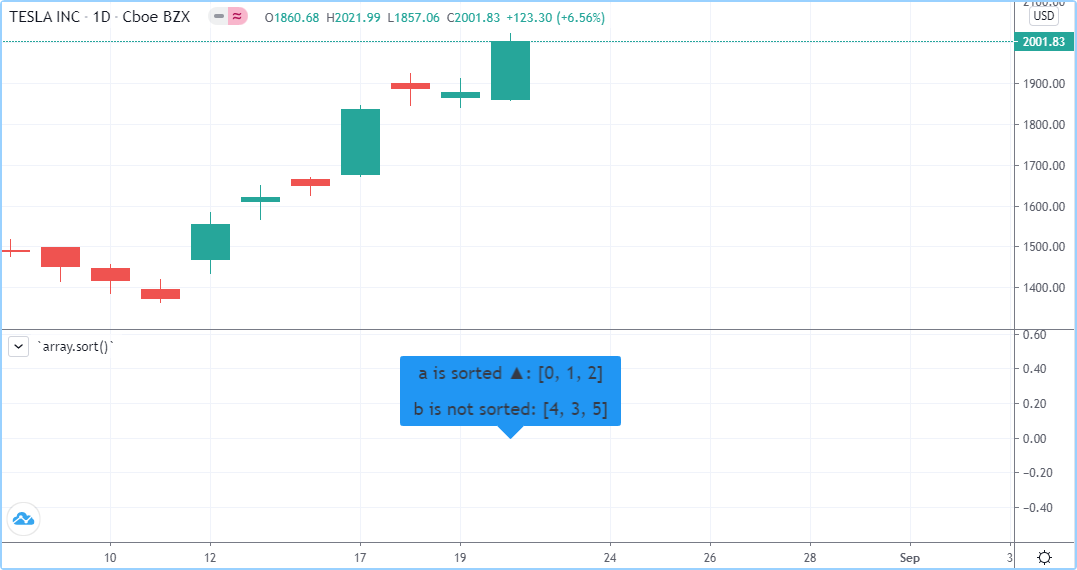
//@version=5
indicator("`array.sort()`")
a = array.new<float>(0)
b = array.new<float>(0)
array.push(a, 2)
array.push(a, 0)
array.push(a, 1)
array.push(b, 4)
array.push(b, 3)
array.push(b, 5)
if barstate.islast
barUp = close > open
array.sort(barUp ? a : b, barUp ? order.ascending : order.descending)
label.new(bar_index, 0,
"a " + (barUp ? "is sorted ▲: " : "is not sorted: ") + str.tostring(a) + "\n\n" +
"b " + (barUp ? "is not sorted: " : "is sorted ▼: ") + str.tostring(b), size = size.large)对数组进行排序的另一个有用选项是使用 array.sort_indices() 函数,该函数获取对原始数组的引用并返回包含原始数组索引的数组。请注意,此函数不会修改原始数组。该order参数是可选的,默认为 order.ascending。
使用array.reverse() 反转数组:
//@version=5
indicator("`array.reverse()`")
a = array.new<float>(0)
array.push(a, 0)
array.push(a, 1)
array.push(a, 2)
if barstate.islast
array.reverse(a)
label.new(bar_index, 0, "a: " + str.tostring(a))使用array.slice()对数组进行切片 会创建父数组子集的浅表副本。您可以使用index_from和参数确定要切片的子集的大小index_to。该index_to参数必须比要切片的子集末尾大 1。
由切片创建的浅表副本就像父数组内容上的窗口一样。用于切片的索引定义窗口在父数组上的位置和大小。如果如下例所示,从数组的前三个元素(索引 0 到 2)创建切片,则无论对父数组进行更改,只要它至少包含三个元素,浅层数组copy 将始终包含父数组的前三个元素。
此外,一旦创建了浅表副本,副本上的操作就会镜像到父数组上。将一个元素添加到浅表副本的末尾(如以下示例所示)会将窗口加宽一个元素,并将该元素插入到父数组中的索引 3 处。在此示例中,从索引 0 开始对子集进行切片对于数组的索引 2 a,我们必须使用:_sliceOfA = array.slice(a, 0, 3)

//@version=5
indicator("`array.slice()`")
a = array.new<float>(0)
array.push(a, 0)
array.push(a, 1)
array.push(a, 2)
array.push(a, 3)
if barstate.islast
// Create a shadow of elements at index 1 and 2 from array `a`.
sliceOfA = array.slice(a, 0, 3)
label.new(bar_index, 0, "BEFORE\na: " + str.tostring(a) + "\nsliceOfA: " + str.tostring(sliceOfA))
// Remove first element of parent array `a`.
array.remove(a, 0)
// Add a new element at the end of the shallow copy, thus also affecting the original array `a`.
array.push(sliceOfA, 4)
label.new(bar_index, 0, "AFTER\na: " + str.tostring(a) + "\nsliceOfA: " + str.tostring(sliceOfA), style = label.style_label_up)我们可以使用array.includes()函数测试某个值是否是数组的一部分 ,如果找到该元素,该函数将返回 true。我们可以使用array.indexof()函数查找数组中某个值的第一次出现 。第一次出现的是索引最低的那个。我们还可以使用array.lastindexof()查找最后一次出现的值 :
//@version=5
indicator("Searching in arrays")
valueInput = input.int(1)
a = array.new<float>(0)
array.push(a, 0)
array.push(a, 1)
array.push(a, 2)
array.push(a, 1)
if barstate.islast
valueFound = array.includes(a, valueInput)
firstIndexFound = array.indexof(a, valueInput)
lastIndexFound = array.lastindexof(a, valueInput)
label.new(bar_index, 0, "a: " + str.tostring(a) +
"\nFirst " + str.tostring(valueInput) + (firstIndexFound != -1 ? " value was found at index: " + str.tostring(firstIndexFound) : " value was not found.") +
"\nLast " + str.tostring(valueInput) + (lastIndexFound != -1 ? " value was found at index: " + str.tostring(lastIndexFound) : " value was not found."))我们还可以对数组执行二分搜索,但请注意,对数组执行二分搜索意味着该数组首先需要仅按升序排序。如果找到该值,则array.binary_search () 函数将返回该值的索引;如果未找到,则返回 -1。如果我们希望始终从数组中返回现有索引,即使未找到我们选择的值,那么我们可以使用其他可用的二分搜索函数之一。 array.binary_search_leftmost () 函数,如果找到该值则返回索引,或者返回找到该值的左侧第一个索引。 array.binary_search_rightmost () 函数几乎相同,如果找到该值,则返回一个索引,或者返回找到该值的右侧的第一个索引。
当您保存脚本时,Pine 脚本中格式错误的array.*()调用语法将导致常见的编译器错误消息出现在 Pine 编辑器的控制台(位于窗口底部)中。 如果对函数调用的确切语法有疑问,请参阅 Pine Script™ v5 参考手册。
使用数组的脚本还可能引发运行时错误,这些错误在图表上的指标名称旁边显示为感叹号。我们在本节中讨论这些运行时错误。
这很可能是您遇到的最常见的错误。当您引用不存在的数组索引时就会发生这种情况。 “xx”值将是您尝试使用的错误索引的值,“yy”将是数组的大小。回想一下,数组索引从零开始,而不是从一开始,到数组大小减一结束。因此,大小为 3 的数组的最后一个有效索引是2。
为了避免此错误,您必须在代码逻辑中做出规定,以防止使用位于数组索引边界之外的索引。此代码将生成错误,因为我们在循环中使用的最后一个索引超出了数组的有效索引范围:
//@version=5
indicator("Out of bounds index")
a = array.new<float>(3)
for i = 1 to 3
array.set(a, i, i)
plot(array.pop(a))正确的for说法是:
for i = 0 to 2要循环未知大小数组中的所有数组元素,请使用:
//@version=5
indicator("Protected `for` loop")
sizeInput = input.int(0, "Array size", minval = 0, maxval = 100000)
a = array.new<float>(sizeInput)
for i = 0 to (array.size(a) == 0 ? na : array.size(a) - 1)
array.set(a, i, i)
plot(array.pop(a))*当您使用脚本的“设置/输入”*选项卡中的字段动态调整数组大小时,请使用input.int()minval和参数保护该值的边界 maxval:
//@version=5
indicator("Protected array size")
sizeInput = input.int(10, "Array size", minval = 1, maxval = 100000)
a = array.new<float>(sizeInput)
for i = 0 to sizeInput - 1
array.set(a, i, i)
plot(array.size(a))有关详细信息,请参阅本页的循环部分。
当数组 ID 初始化为 时na,不允许对其进行操作,因为不存在数组。此时存在的只是一个包含该na值的数组变量,而不是指向现有数组的有效数组 ID。请注意,创建的数组中没有任何元素(就像使用 时所做的那样),但仍然具有有效的 ID。这段代码将抛出我们正在讨论的错误:a = array.new_int(0)
//@version=5
indicator("Out of bounds index")
array<int> a = na
array.push(a, 111)
label.new(bar_index, 0, "a: " + str.tostring(a))为了避免这种情况,请使用以下命令创建一个大小为零的数组:
array<int> a = array.new_int(0)或者:
a = array.new_int(0)如果您的代码尝试声明大小大于 100,000 的数组,则会出现此错误。如果在动态追加元素到数组时,新元素将数组的大小增加到超过最大值,也会发生这种情况。
我们还没有发现负大小数组的任何用途,但如果您发现了,我们可能会允许它们:)
如果调用array.shift()来删除空数组的第一个元素,则会发生此错误。
如果调用array.pop()来删除空数组的最后一个元素,则会发生此错误。
当在array.slice()等函数中使用两个索引时,第一个索引必须始终小于第二个索引。
每当父数组的大小被修改而导致由切片点创建的浅表副本位于父数组边界之外时,就会出现此消息。此代码将重现它,因为在创建从索引 3 到 4(我们的五元素父数组的最后两个元素)的切片后,我们删除父元素的第一个元素,使其大小为 4,最后一个索引为 3。从那一刻起,仍然指向父数组索引 3 到 4 处的“窗口”的浅拷贝,指向父数组的边界之外:
//@version=5
indicator("Slice out of bounds")
a = array.new<float>(5, 0)
b = array.slice(a, 3, 5)
array.remove(a, 0)
c = array.indexof(b, 2)
plot(c)