[Model][Speculative Decoding] Integrate PARD into vLLM #18541
Conversation
|
👋 Hi! Thank you for contributing to the vLLM project. 💬 Join our developer Slack at https://slack.vllm.ai to discuss your PR in #pr-reviews, coordinate on features in #feat- channels, or join special interest groups in #sig- channels. Just a reminder: PRs would not trigger full CI run by default. Instead, it would only run Once the PR is approved and ready to go, your PR reviewer(s) can run CI to test the changes comprehensively before merging. To run CI, PR reviewers can either: Add 🚀 |
|
Hi @LiuXiaoxuanPKU @njhill , I’d really appreciate it if you could help review this PR when you have some time. Let me know if anything needs clarification. Thanks a lot! |
Signed-off-by: root <anzihao_hh@126.com>
Signed-off-by: root <anzihao_hh@126.com>
Signed-off-by: root <anzihao_hh@126.com> Signed-off-by: <anzihao_hh@126.com>
Signed-off-by: root <anzihao_hh@126.com> Signed-off-by: <anzihao_hh@126.com>
5ee0c1f to
487e344
Compare
Signed-off-by: root <zihaoan2@amd.com> Signed-off-by: <zihaoan2@amd.com>
|
Hi @zihaoanllm, thanks for making this PR. The code path you have here is v0. as of 0.9.x, all v0 codepath should be frozen and will only be merged for bugfix only. I would suggest implementing this under |
Hi @aarnphm , thanks for your response. Currently, we’ve implemented a basic version under v0. The speculative decoding feature and multi-model KV cache support in v1 are still under development. I do plan to integrate this into v1 in the future. In the meantime, merging this method into v0 would be helpful for our current usage and would also facilitate the future integration into v1. |
Update Test ResultTest codedetailsimport argparse
import json
import os
from vllm import LLM, SamplingParams
import requests
from transformers import AutoTokenizer
from vllm.inputs import TokensPrompt
import numpy as np
os.environ.update({
"VLLM_USE_V1": "0"
})
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("--model", type=str, default="unsloth/Meta-Llama-3.1-8B-Instruct")
parser.add_argument("--draft", type=str, default="amd/PARD-Llama-3.2-1B")
parser.add_argument("--benchmark", type=str, default="humaneval")
parser.add_argument("--max_num_seqs", type=int, default=1)
parser.add_argument("--num_prompts", type=int, default=80)
parser.add_argument("--num_spec_tokens", type=int, default=8)
parser.add_argument("--tp", type=int, default=1)
parser.add_argument("-t", "--token", type=int, default=512)
parser.add_argument("--temp", type=float, default=0)
parser.add_argument("--ar", action='store_true')
parser.add_argument("-r", "--reasoning", action='store_true')
parser.add_argument("--disable-warmup", action='store_true')
return parser.parse_args()
def main():
args = parse_args()
prompts = []
for line in requests.get(f'https://raw.githubusercontent.com/AMD-AIG-AIMA/PARD/master/datas/bmk/{args.benchmark}.jsonl').text.splitlines():
if line:
prompts.append(json.loads(line)['data'])
prompts = prompts[:args.num_prompts]
datas = [[{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": prompt}] for prompt in prompts]
tokenizer = AutoTokenizer.from_pretrained(args.model, use_fast=True)
texts = []
for data in datas:
text = tokenizer.apply_chat_template(
data,
tokenize=False,
add_generation_prompt=True,
enable_thinking=args.reasoning,
)
texts.append(text)
batch_input_ids = tokenizer(texts, return_attention_mask=False)['input_ids']
batch_input_ids = [TokensPrompt(prompt_token_ids=ids) for ids in batch_input_ids]
llm = LLM(
model=args.model,
enable_prefix_caching=False,
tensor_parallel_size=args.tp,
max_model_len=8192,
max_num_seqs=args.max_num_seqs,
gpu_memory_utilization=0.8,
speculative_config=None if args.ar else {
"model": args.draft,
"num_speculative_tokens": args.num_spec_tokens
},
compilation_config={
"splitting_ops": [],
"compile_sizes": [],
"cudagraph_capture_sizes": [
256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,
120,112,104,96,88,80,72,64,56,48,40,34,33,32,3130,29,28,27,26,25,24,23,22,21,20,19,18,17,16,15,14,13,12,11,10,9,8,7,6,5,4,3,2,1
],
"max_capture_size": 256
},
)
sampling_params = SamplingParams(temperature=args.temp, max_tokens=args.token)
## warmup
if not args.disable_warmup:
print("warmup...")
outputs = llm.generate(batch_input_ids, sampling_params=sampling_params)
# inference
print("inference...")
outputs = llm.generate(batch_input_ids, sampling_params=sampling_params)
# speed
speed = []
for output in outputs:
speed.append([len(output.outputs[0].token_ids), (output.metrics.finished_time - output.metrics.first_token_time)])
print(f"[anwer]:\n {output.outputs[0].text}")
print(f"\n\n{'='*100}\n\n")
print(f'[speed]: {np.array(speed)[:,0].sum() / np.array(speed)[:,1].sum()}\n')
# accepted
if not args.ar:
acceptance_counts = [0] * (args.num_spec_tokens + 1)
for output in outputs:
for step, count in enumerate(
output.metrics.spec_token_acceptance_counts):
acceptance_counts[step] += count
print(f"[acceptance length]: {(sum(acceptance_counts) / acceptance_counts[0])}")
print(f"\n\n{'='*100}\n\n")
print(args.__dict__)
print(f"\n\n{'='*100}\n\n")
if __name__ == "__main__":
main()Test Result
|
|
I want @WoosukKwon opinion on this as well! I not too familiar with v0 spec decode, hence I don't have a strong opinion here. Given that the general concensus is that v0 is going to be removed soon, I'm not sure if we would want to accept new features at this point. Spec Decode in V1 should be supported, at least with eagle3 and medusa (limited support), but iiuc the multi-model KV cache is a requirements for this spec decode method? |
While trying to integrate this into v1, I found that it currently seems to only support KV caches with a single shape (code link)? Both PARD and vanilla SpecDec rely on using both a small draft model and large target model, and their attention structures are often different, which makes v1 incompatible for now. The eagle series works because the head structure matches the target model, and Medusa's draft model doesn't use a KV cache. I'm still getting familiar with vLLM, but I’d be happy to help with integrating this method into v1 in the future. Please feel free to correct me if I’ve misunderstood anything. Thanks! |
|
@zihaoanllm - the result on humaneval look good. Could you please also share AL on MTBench which will make it easier to compare with EAGLE-1/3 which we already have? |
Ah I think we yet to have plan to support draft models that has diff architecture than the target models atm in v1 (sorry about this, should have read through the blogpost more thoroughly 😃) |
I found that the previous test script overcounted one bonus token (it seems a recent PR changed the calculation method). The accepted length on HumanEval should be corrected from 6.6 to 5.6 and 7.2 to 6.2. Throughput is unaffected. I’ve already updated the earlier post accordingly. Below are the evaluation code and results on MT-Bench, where I’ve also included the earlier results from Eagle for comparison. evaluation code# pard.py
import argparse
import json
import os
from vllm import LLM, SamplingParams
import requests
from transformers import AutoTokenizer
from vllm.inputs import TokensPrompt
import numpy as np
os.environ.update({
"VLLM_USE_V1": "0"
})
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("--model", type=str, default="unsloth/Meta-Llama-3.1-8B-Instruct")
parser.add_argument("--draft", type=str, default="amd/PARD-Llama-3.2-1B")
parser.add_argument("--benchmark", type=str, default="humaneval")
parser.add_argument("--max_num_seqs", type=int, default=1)
parser.add_argument("--num_prompts", type=int, default=80)
parser.add_argument("--num_spec_tokens", type=int, default=8)
parser.add_argument("--tp", type=int, default=1)
parser.add_argument("-t", "--token", type=int, default=512)
parser.add_argument("--temp", type=float, default=0)
parser.add_argument("--ar", action='store_true')
parser.add_argument("-r", "--reasoning", action='store_true')
parser.add_argument("--disable-warmup", action='store_true')
return parser.parse_args()
def main():
args = parse_args()
prompts = []
if args.benchmark == 'mt_bench':
for line in requests.get(f'https://raw.githubusercontent.com/SafeAILab/EAGLE/refs/heads/main/eagle/data/mt_bench/question.jsonl').text.splitlines():
if line:
prompts.append(json.loads(line)['turns'][0])
else:
for line in requests.get(f'https://raw.githubusercontent.com/AMD-AIG-AIMA/PARD/master/datas/bmk/{args.benchmark}.jsonl').text.splitlines():
if line:
prompts.append(json.loads(line)['data'])
prompts = prompts[:args.num_prompts]
datas = [[{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": prompt}] for prompt in prompts]
tokenizer = AutoTokenizer.from_pretrained(args.model, use_fast=True)
texts = []
for data in datas:
text = tokenizer.apply_chat_template(
data,
tokenize=False,
add_generation_prompt=True,
enable_thinking=args.reasoning,
)
texts.append(text)
batch_input_ids = tokenizer(texts, return_attention_mask=False)['input_ids']
batch_input_ids = [TokensPrompt(prompt_token_ids=ids) for ids in batch_input_ids]
llm = LLM(
model=args.model,
enable_prefix_caching=False,
tensor_parallel_size=args.tp,
max_model_len=8192,
max_num_seqs=args.max_num_seqs,
gpu_memory_utilization=0.8,
speculative_config=None if args.ar else {
"model": args.draft,
"num_speculative_tokens": args.num_spec_tokens
},
compilation_config={
"splitting_ops": [],
"compile_sizes": [],
"cudagraph_capture_sizes": [
256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,
120,112,104,96,88,80,72,64,56,48,40,34,33,32,3130,29,28,27,26,25,24,23,22,21,20,19,18,17,16,15,14,13,12,11,10,9,8,7,6,5,4,3,2,1
],
"max_capture_size": 256
},
)
sampling_params = SamplingParams(temperature=args.temp, max_tokens=args.token)
## warmup
if not args.disable_warmup:
print("warmup...")
outputs = llm.generate(batch_input_ids, sampling_params=sampling_params)
# inference
print("inference...")
outputs = llm.generate(batch_input_ids, sampling_params=sampling_params)
# speed
speed = []
for output in outputs:
speed.append([len(output.outputs[0].token_ids), (output.metrics.finished_time - output.metrics.first_token_time)])
print(f"[anwer]:\n {output.outputs[0].text}")
print(f"\n\n{'='*100}\n\n")
print(f'[speed]: {np.array(speed)[:,0].sum() / np.array(speed)[:,1].sum()}\n')
# accepted
if not args.ar:
acceptance_counts = [0] * (args.num_spec_tokens + 1)
for output in outputs:
for step, count in enumerate(
output.metrics.spec_token_acceptance_counts):
acceptance_counts[step] += count
print(f"[acceptance length]: {(sum(acceptance_counts) / acceptance_counts[0])}")
print(f"\n\n{'='*100}\n\n")
print(args.__dict__)
print(f"\n\n{'='*100}\n\n")
if __name__ == "__main__":
main()
|
|
@zihaoanllm - you are using vLLM V0 metrics when you are computing AL for PARD, right? V0 metric incorrectly counts AL which leads to higher reported AL as per this doc. Relevant paragraph in the doc
Basically, if 3 tokens were proposed and 1st and 3rd token matched then the accepted mask is [1, 0, 1]. |
|
@ekagra-ranjan Yes, we're using vLLM v0 for inference. Thanks for pointing out the issue with the AL metric calculation. To add some context, I’ve also measured AL using other inference methods, and while v0 does tend to report slightly higher AL, the overall impact seems to be minor. Here's a quick comparison:
|
@aarnphm @WoosukKwon Just wondering, do you have a rough plan or timeline for when v1 might support using a draft model with a different architecture from the target model? We're quite interested in adopting v1 for our speculative decoding setup, and support for mismatched architectures would be a key enabler for us. |
I did talk with Woosuk about supporting separate draft models, and it seems like this would complicates the matter a lot in v1. The main problem with standalone draft model is that it is pretty difficult to maintain the KV cache when the target and the draft models have different KV cache shape. There isn't a guarantee/easy solution for this. Another problem is that will using smaller/similar generations of draft models, you migth want different TP/DP degrees (or implement something like PARD), which in turns is pretty tricky. V0 circumvented this problem by having a separate "draft" workers, but it is pretty brittle and have a lot more problems. So I'm not entirely sure if we can support draft model, yet, unless we have a better way to manage KV/address said problems. |
Thanks a lot for the detailed explanation! |
Signed-off-by: root <zihaoan2@amd.com> Signed-off-by: <zihaoan2@amd.com>
|
Hi @zihaoanllm - could you share if vllm V0 has any existing script to measure the AL OR there arent't any so you had to write your own here? |
The current version of vLLM has removed the v0 SPD test script. I am using the test code from an older version. |
|
@zihaoanllm - could you pls point me to the old code for computing AL on V0? I tried but couldnt find it. |
|
Hi @zihaoanllm any insights on why we close this PR? |
|
Since v0 is deprecated and v1 currently does not support heterogeneous draft models, a new PR will be opened when the time is right. If you need to use v0, please refer to: model/integrate-pard-0521. |
Description:
This PR integrates PARD into vLLM. PARD (PARallel Draft model) is a speculative decoding method that enables low-cost adaptation of autoregressive draft models into parallel draft models. It improves inference efficiency by allowing the draft model to predict multiple future tokens in a single forward pass, significantly reducing decoding latency. For detailed technical information, please refer to the technical report, github and blog.
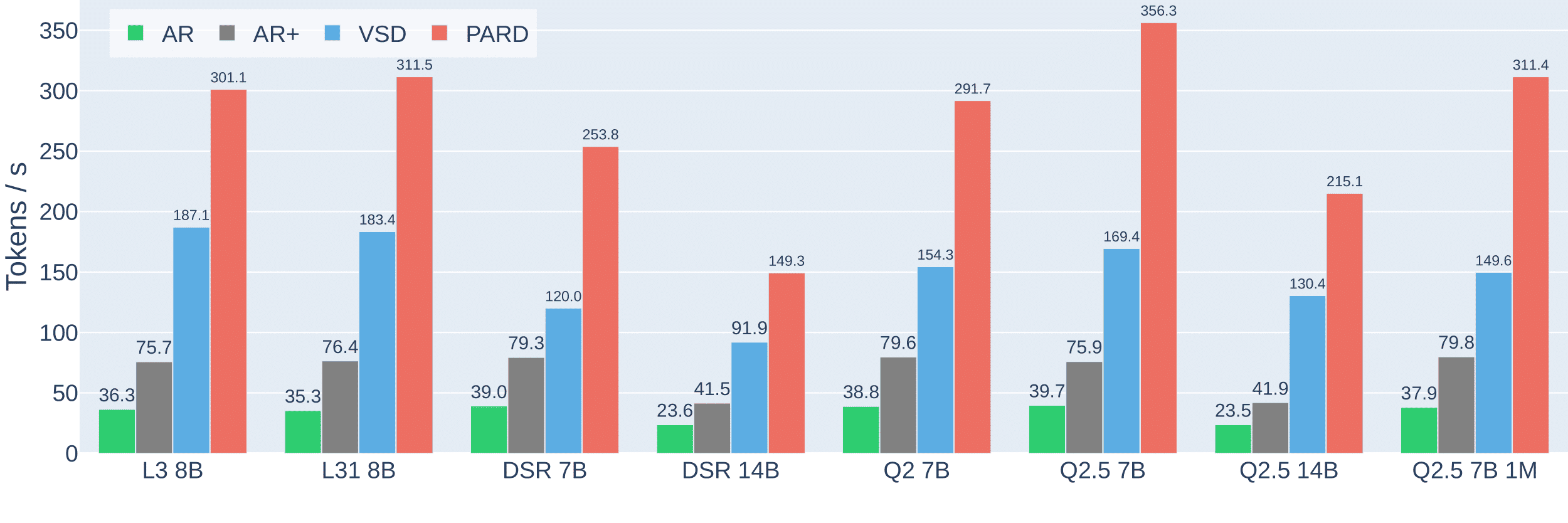
AR and AR+ represent baseline auto-regressive generation using Transformers and Transformers+, respectively. VSD denotes vanilla speculative decoding. PARD refers to the proposed method in this work.Support Model Series
Supports acceleration for models across various sizes in the following series: Llama3, Deepseek-R1-distilled-Qwen, and Qwen1.5/2/2.5.
Summary of changes:
1. vllm/spec_decode/multi_step_worker.py:
Added the pard_infer function to support PARD-based speculative decoding. Key logic includes:
KV cache recomputation & seq_group_metadata_list update: Some of PARD's KV cache is derived from mask_token and needs to be recomputed. New mask tokens are introduced accordingly.
Proposal generation: Uses the SpeculativeProposals function to obtain token proposals.
Draft model forward: Only a single forward pass is needed for the draft model to generate multiple tokens.
Logits shape alignment: Aligns the logits shapes of the target and draft models when they differ.
Output conversion: Converts intermediate results into the standard output format.
2. vllm/spec_decode/batch_expansion.py:
Modified score_proposal to support:
keep_index: If not None, only returns results for specified indices. Recomputed KV cache outputs will be excluded.
return_output: If True, returns the full target_sampler_output.
3. vllm/spec_decode/spec_decode_worker.py:
Added a new interface to enable PARD inference.
Test
Test Code
Test Result