Serialization of natural language in data formats such as JSON [I18N] #178
Comments
|
Please add the i18n-discuss label so that our tracking mechanism picks this up. |
|
This seems related to the discussion currently happening in whatwg/webidl#358, where we're attempting to add a shared primitive to Web IDL that all specs can use, and getting stuck. The point of contention is basically whether the pattern should be someAPI({
lang: "...",
dir: "...",
label: "a string governed by the lang/dir"
name: "another string, governed by the same lang/dir"
});(the " or someAPI({
label: {
lang: "...",
dir: "...",
value: "a string governed by the lang/dir"
},
name: "another string, using the default lang/dir"
});(the " The former makes it easier to say that all strings have the same lang/dir. The latter allows more granular decision making, at the cost of verbosity. I suppose you could even have both. |
|
@aphillips it seems that this repo is not under the w3c/ domain, so i'm unable to set up the normal notifications and labels, and we won't get notifications to our list. |
|
One question we're thinking about is to what extent this can be solved by using only dir="auto" (plus LRM and RLM or similar) and language tags. The ergonomics of both options aren't great. I also wonder whether there's an alternative that could be plain text much of the time but could also be more markup-like when needed. |
|
Discussed on call 06-06 suggestion that I18N group should work with WebIDL group. |
There are quite a few parser implementations out in the wild already for this approach to be feasible - and since parsers which do not support this feature will not function against data with these tags present, this does not seem like a way forward. We did briefly touch on http://unicode.org/faq/languagetagging.html during the call, in case that would be an option. |
|
dir="auto" is not a panacea. The first strong characters in a string may be left-to-right and fool the algorithm. My concern here is that this requires the addition of LRM/RLM markers to data---data that may not be owned by the process assembling the wire format or that may have a field length restriction expressed in characters, code units, or bytes, etc. Adopting auto semantics and requiring the markers introduces (possibly cascading) data change. It also requires, in some cases, developers to introduce more markers into text, as when assembling messages. |
|
All, wrt using Unicode formatting characters to establish direction, please read the other docs that Addison links – in particular http://w3c.github.io/i18n-discuss/notes/string-base-direction.html – where we try to enumerate the pros and cons of various approaches. (@aphilips we should probably make it a bit clearer that folks should read those docs to get a better basis for discussion) @domenic it's useful to be able to apply the same lang/dir metadata to multiple strings without repeating the metadata, if that's possible; however, it's certainly easy to imagine situations where different assignments are needed for particular strings (eg. in the case of a set of alternative translations for an error message, where one string is in english, and another in hebrew). hth |
Understood. It was just a note that the topic came up during the call. |
|
So let me present what I'm concerned about here in a little more detail. My basic concern is that there really don't seem to be any good options:
One of the pieces of advice from i18n in the past was that text that should be presented to users should be markup rather than attribute values, so that when needed it could allow elements within it (for things like language and direction, ruby, etc.). I also wonder whether this sort of advice could be extended here, i.e., whether we should be encouraging the use of HTML rather than text. |
|
(And if we wanted to encourage HTML, would it be a subset of HTML, or arbitrary HTML?) |
|
Thanks @dbaron. While, in general, markup is a Good Thing for this, at the same time the point of using JSON and other data languages is the transmission of "unrendered" data. Let me give a concrete use case. Suppose that in my day job I am building a Web page to show a customer's library of e-books. The e-books exist in a catalog of data and consist of the usual data values. It might looks something like: Each of the above is a data field in a database somewhere. Now, because I know I need it, I have language and direction information for each of the textual fields also in my database. I even have stuff like a pronunciation field for title and author (for sorting Chinese and Japanese). Those are just data fields. Do I really want to serialize them as HTML: After all, I may not end up displaying the I'd also argue that:
... is probably wrong. The common case where you don't want language or direction information is for non-language-bearing fields ( |
|
Not to be a pedant, but if you separate the language tag from the other fields, don't you introduce ambiguity or risk of error? { The title is indeed in Latin. The book was originally written in Polish. But maybe this edition is in some other language. This becomes particularly problematic if two fields need different tagging (here, the author's name might be tagged as "pl" -- Polish). |
|
@dswinger Exactly so. The book language(s) (the language(s) of the intended audience) might be (often are) different from the language of the title or the author. The |
|
Solution 1 that would require changes to JSON itself isn't practical, because it would be too much of ocean boiling effort to change all JSON parsers. I think Solution 2 potentially with bidi control characters within string values is workable.
I would expect the former to face less resistance, because it just adds some key-value pairs without forcing a reorganization of a given JSON-based format compared to its lang/dir-unaware version. Moreover, considering JSON from the perspective of developers trying to escape XML, the added nesting/complexity of the latter would probably not be well received. Therefore, I think pushing the latter as the only option wouldn't be productive. A third option would be:
I think using HTML in JSON makes sense for strings that carry multi-paragraph text with inline formatting (i.e. something that would make sense inside HTML Even though HTML parsers are now widely available, a plain-text string is a significantly simpler thing for the consumer's data model to deal with than a tree rooted at DOM People use JSON instead of XML to avoid various complexities of XML and to use a format that maps nicely to and from basic programming language data structures. Making shortish plainish strings (not just ones representing multi-paragraph text with inline formatting) in JSON potentially carry markup would defeat both avoiding XML mixed content complexity and having a format that maps nicely to and from basic programming language data structures. When a JSON-based format wouldn't use markup in strings for non-bidi reasons, to the extent a base direction taken from an adjacent key-value pair isn't enough, I think finer-grained bidi control should use the bidi control characters instead of importing the full data model complexity of markup for every (human-readable) string. (Whereas bidi is intrinsic to whole scripts, ruby is a sometimes-used (relatively rarely-used even) typographical device for the scripts with which it is used, so I think it cases where bidi doesn't justify the complexity of markup, ruby doesn't, either.) |
|
A lot of great points have been made in this thread. I'm personally not convinced that there is any single "right" solution. It seems that if we want to create a compact data representation for strings, associating lang, direction, and other meta-data about the string, then this encoding has to be as maximally-portable across systems as possible, which leads me to think it must be some new representation of a string literal. That of course, is asking for a huge change across all programming environments and applications--not likely to happen, but neat to dream about--or even start some activity there, perhaps in Unicode. For a serialization memory layout that associates lang, direction, etc., metadata about strings, I don't offer a strong opinion, though I have a weak opinion: keep it simple, or it will likely be too much of a burden to get much traction. For example, I think a simple dictionary with fields at parallel depths would work fine for most applications, e.g., { lang: .., dir: .., stringvalue: ... }. |
|
@travisleithead I tend to agree. It would have been nice to address this in the past, but we're here now. However, building recommended patterns and best practices would allow specs to be consistent and interoperate well. |
Watch out though, apparently harmless data may not actually be so. The isbn field will only display correctly if it is isolated when displayed in a RTL target context and treated as LTR inside that isolated area. For example, if i just drop the text into a field on a RTL page without any precautions, i get:
rather than what i really want, which is:
However, if the value were a range, such as 100-300, the first arrangement would actually be what's wanted in Arabic (though not Hebrew, and i'm not sure about N'Ko), otherwise the range would appear to be decreasing instead of increasing. So it may actually be useful to have some direction information for isbn numbers, MAC addresses, telephone numbers, etc. |
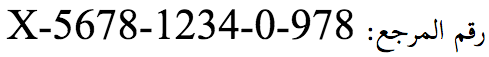
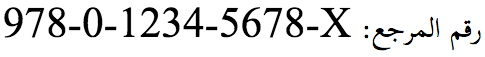
|
Though in those cases there's a tradeoff between having the direction data in the text data, versus having the application have knowledge of the correct way to present the particular field, since there is a correct and simple per-field algorithm (although it's not particularly simple to have tens or hundreds of them). One is easier for the producer of the data and the other is easier for the consumer. This is different from cases where you basically have to have the direction data stored in the text because you can't trivially derive it from the text. |
|
@dbaron I recently added a section about use of script subtags for guessing bidi info. In addition to that, we noticed that some people were reading this document and not catching some of the key messages, so i have a plan to summary and simplify the text which is currently in progress, and waiting for some time to become available so that i can complete it. That might be a good time for review (?) |
|
Related: w3c/manifest#676 |
|
We agreed to put this on the agenda for the next f2f and close it off somehow. |
|
@torgo Thanks. Would you like to invite my/Richard's participation? We can have an updated version of our doc ready, if the date is 2019-02-05. Is that the target date? |
|
Note that the I18N WG resolved to publish our document of best practice recommendations as FPWD in our last teleconference. The current editor's copy is here: https://w3c.github.io/string-meta/ I suggest that TAG either adopt our best practices or provide feedback on changes (that we can incorporate). I did not receive a reply to my previous question about TAG f2f participation, btw. |
|
I just took a look at the document and filed two issues (above); I'm more concerned about the second one. Regarding discussion at the meeting; I think the chairs would like us to just stop cycling back to this issue as a group, and I think I agree that it doesn't need attention from the whole TAG, but probably @cynthia and I can continue to provide feedback on the document if needed. |
|
I believe we discussed this in a previous call and was happy to close it off; and follow up on the issues in the group's tracker. I'll close this for now; thanks a lot for the long discussion and we hope to hear more from i18n in the future. (Please re-open if I got the summary of our last discussion wrong). |
Hello TAG!
I'm requesting a TAG review of:
Further details (optional):
You should also know that...
The Internationalization WG has been commenting on data format specifications with increasing frequency over the past couple years in which we have noted the lack of natural language string types in formats such as JSON. We are concerned that there are internationalization gaps or, in an attempt to address our comments, non-interoperable and divergent implementation choices being made.
This issue is the result of an I18N WG action.
We would like the TAG's opinion on the problem and mooted solutions. The I18N WG chair (@aphillips) and Team contact (@r12a) can be available for consultation as needed.
We'd prefer the TAG provide feedback as (please select one):
The text was updated successfully, but these errors were encountered: