똑같은 기능의 객체를 매번 생성하기보다는 객체 하나를 재사용하는 편이 나을 때가 많습니다. 특히 불변 객체는 언제든 재사용할 수 있습니다.
다음 코드는 하지 말아야 할 극단적인 예이니 유심히 한번 살펴보겠습니다.
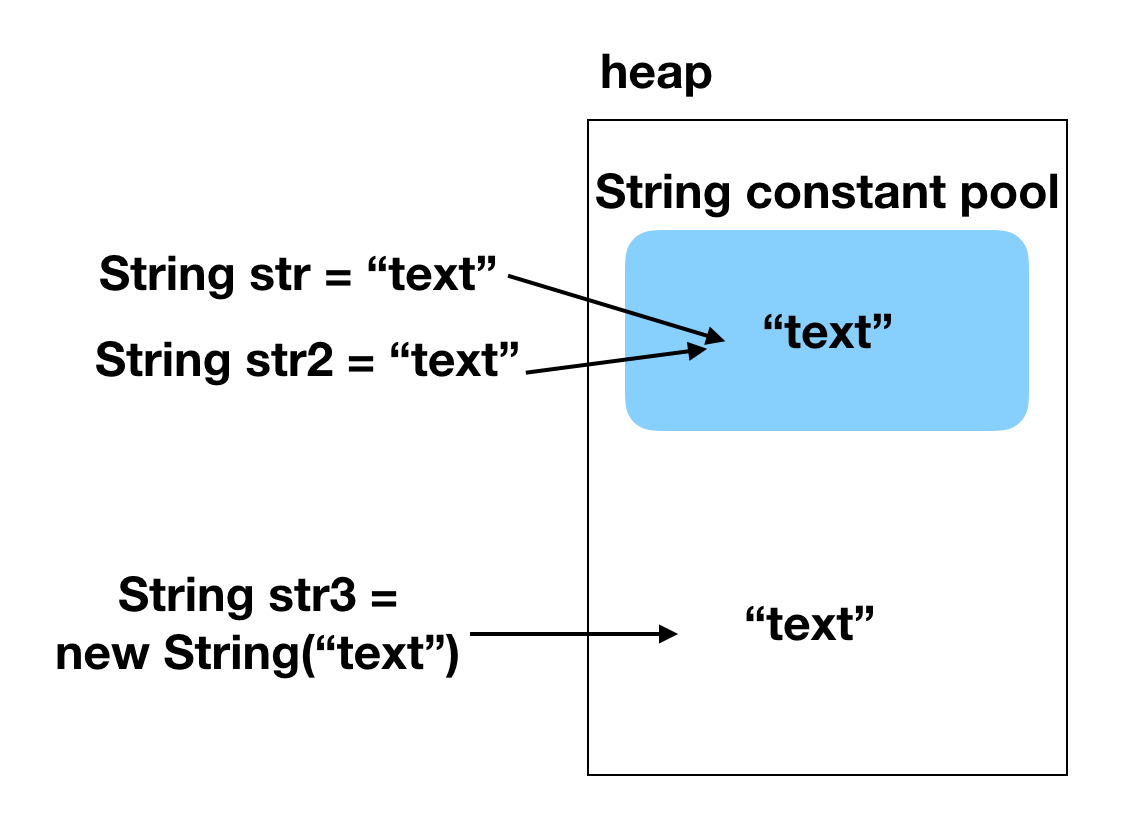
String s = new String("Gyunny");
위의 문장은 실행될 때마다 Heap 영역에 새로운 String 인스턴스를 만듭니다. 하나만 만들고 그것을 재사용해도 하면 되는데 반복문이나 빈번히 호출되는 메소드에서 위의 코드가 실행된다면 쓸데 없이 같은 String 인스턴스가
계속 생기기 때문에 엄청난 메모리 낭비를 가져올 수 있습니다.
String s = "Gyunny";
지금 보는 코드는 new 연산자를 이용해서 인스턴스를 만들 때와 다르게 string contant pool 영역에 있는지 검색 한 후에 String 인스턴스를 재사용합니다.
public class Test {
public static void main(String[] args) {
String name1 = new String("Gyunny");
String name2 = new String("Gyunny");
System.out.println(System.identityHashCode(name1));
System.out.println(System.identityHashCode(name2));
System.out.println(name1 == name2);
System.out.println("===================");
String name3 = "Gyunny";
String name4 = "Gyunny";
System.out.println(System.identityHashCode(name3));
System.out.println(System.identityHashCode(name4));
System.out.println(name3 == name4);
}
}1846274136
1639705018
false
===================
1627674070
1627674070
true
그러면 이렇게 new 연산자를 이용해서 Heap 영역에 객체를 생성하게 되면 메모리 위치가 다르기 때문에 ==이 아니라 equals를 이용해야 합니다. 반면에 string constant pool은 같은 곳에서
가져오기 때문에 ==으로 비교했을 때 true가 나오는 것을 볼 수 있습니다.
아이템1에서 생성자 대신 정적 팩토리 메소드를 제공하는 불변 클래스에서는 정적 팩토리 메소드를 사용해 불필요한 객체 생성을 피할 수 있는 것을 정리했었습니다.
예를들면, Boolean 클래스는 생성자 대신 Boolean.valusOf(String) 팩토리 메소드를 사용하는 것이 좋습니다. 왜냐하면 생성자를 호출할 때마다 매번 새로운 객체를 만들지만,
팩토리 메소드는 하나의 객체를 재사용하기 때문입니다.
public final class Boolean implements java.io.Serializable,
Comparable<Boolean>
{
public static final Boolean TRUE = new Boolean(true);
public static final Boolean FALSE = new Boolean(false);
public Boolean(boolean value) {
this.value = value;
}
public Boolean(String s) {
this(parseBoolean(s));
}
public static boolean parseBoolean(String s) {
return ((s != null) && s.equalsIgnoreCase("true"));
}
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}
}Boolean 클래스의 내부 코드 중 일부를 가져왔습니다. 보면 생성자는 매번 새로운 객체를 만들고 정적 팩토리 메소드인 valueOf는 static final 필드 객체를
사용하는 것을 볼 수 있습니다.
public class Test {
public static void main(String[] args) {
// 생성자 이용
Boolean b1 = new Boolean("true");
Boolean b2 = new Boolean("true");
System.out.println(b1 == b2); // false
// 정적 팩토리 메소드를 이용
Boolean b3 = Boolean.valueOf("true");
Boolean b4 = Boolean.valueOf("true");
System.out.println(b3 == b4); // true
}
}그러면 위와 같이 == 연산자를 사용해 비교했을 때, 생성자를 이용했을 때는 false가 나오고, 정적 팩토리 메소드를 이용했을 때는 true가 나오는 것을 볼 수 있습니다.
그래서 자바9 부터는 Boolean 클래스 생성자 API는 deprecated로 지정되었습니다. 그리고 valueOf() 메소드를 이용했을 때는 재사용할 수 있다는 것입니다.
생성 비용이 비싼 객체들이 있습니다. 생성할 때 오래 걸린다던지, 메모리를 많이 사용하는 객체를 생성 비용이 비싼 객체라고 합니다. 예를들어 주어진 문자열이 유효한 로마 숫자인지를 확인하는 메소드가 있다고 가정해보겠습니다.
public class Roman {
static boolean isRomanNumeral(String s) {
return s.matches("^(?=.)M*(C[MD] |D?C{0,3})(X[CL] |L?X{0,3}) (I[XV] |V?I{0,3})$");
}
}이 방식의 문제는 String.matches 메소드를 사용한다는 데 있습니다. String.matches는 정규표현식으로 문자열 형태를 확인하는 가장 쉬운 방법이지만, 성능이 중요한 상황에서 반복해 사용하기엔 적합하지 않습니다.
public final class String {
public boolean matches(String regex) {
return Pattern.matches(regex, this);
}
}왜냐하면 위와 같이 내부적으로 Pattern.matches() 메소드를 사용하게 됩니다. Pattern.matches() 메소드의 코드도 보겠습니다.
public final class Pattern {
public static boolean matches(String regex, CharSequence input) {
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(input);
return m.matches();
}
public static Pattern compile(String regex, int flags) {
return new Pattern(regex, flags);
}
}그러면 위와 같이 Pattern.compile() 메소드를 통해 새로운 객체를 만들게 되고 이러한 과정이 시간이 오래걸리게 됩니다.
그런데 정규표현식 용 Pattern 인스턴스는, 한 번 쓰고 버려져서 곧바로 가비지 콜렉션 대상이 되기 때문에 빈번히 호출되는 상황에서는 성능 개선이 필요합니다.
import java.util.regex.Pattern;
public class Roman {
private static final Pattern ROMAN = Pattern.compile("^(?=.)M*(C[MD] |D?C{0,3})(X[CL] |L?X{0,3}) (I[XV] |V?I{0,3})$");
static boolean isRomanNumeral(String s) {
return ROMAN.matcher(s).matches();
}
}위와 같이 개선하면 isRomanNumeral() 메소드가 빈번히 호출되는 상황에서 객체를 재사용하기 때문에 성능을 상당히 끌어올릴 수 있습니다.
객체가 불변이라면 재사용해도 큰 문제가 없습니다. 하지만 직관에 반대되는 상황도 있습니다. 바로 어댑터입니다.
어댑터(뷰): 실제 작업은 뒷단 객체에 위임하고, 자신의 제2의 인터페이스 역할을 해주는 뒷단 객체만 관리합니다.
어댑터는 뒷단 객체만 관리하면 됩니다. 즉, 뒷단 객체 외에는 관리하지 않아도 되기 때문에 뒷단 객체 하나당 어탭터 하나씩만 만들어지면 충분합니다.
예를들어, Map 인터페이스의 keySet 메소드는 Map 객체 안의 키 전부를 담은 Set 뷰(어댑터)를 반환합니다.
뷰 객체를 여러 개 만들거라 생각할 수 있지만, 사실은 매번 같은 인스턴스를 반환합니다.
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class Test {
public static void main(String[] args) {
Map<String, Integer> menu = new HashMap<>();
menu.put("Burger", 8);
menu.put("Pizza", 9);
Set<String> names1 = menu.keySet();
Set<String> names2 = menu.keySet();
names1.remove("Burger");
System.out.println(names1.size()); // 1
System.out.println(names2.size()); // 1
System.out.println(names1 == names2); // true
}
}위의 코드를 보면 keySet() 메소드를 통해서 names1, names2 2개의 Set 인터페이스를 반환받았습니다. 그리고 names1의 키를 하나 삭제한 후에
사이즈를 체크해보니 둘 다 사이즈가 1로 바뀐 것을 볼 수 있습니다.
이러한 개념(재사용)을 같이 협업하는 팀원이 모르는데 같이 사용하다 보면 문제가 발생할 수도 있습니다.
기본형 값을 래퍼 클래스의 객체로 자동 변환해주는 것을 오토박싱(autoboxing)이라 합니다.
import java.util.ArrayList;
import java.util.List;
public class Test {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(10); // autoboxing. 10 -> new Integer(10);
int value = list.get(0); // unboxing. new Integer(10) -> 10
}
}예를 들어, ArrayList에 add를 통해 하나씩 값을 추가하는 상황을 보겠습니다. 우리는 list.add(10)이라고 사용을 하지만
컴파일 할 때의 코드는 list.add(new Integer(10));가 됩니다.
그러면 이제 책에 있는 예제 코드를 보겠습니다.
public class Test {
private static long sum() {
Long sum = 0L;
for (long i = 0; i <= Integer.MAX_VALUE; i++) {
sum += i;
}
return sum;
}
}먼저 레퍼런스 타입인 Long 타입의 sum 변수가 있고, for 문을 통해 sum에다 기본형의 long 변수 i를 더하고 있습니다.
Long sum = 0; -> Long sum = new Long(0);
Long sum = 1; -> Long sum = new Long(1);
그러면 위와 같은 상황이 반복되어 객체가 2의 31승개나 만들어지게 됩니다. 자원낭비, 시간 오래걸림 등등 여러가지 문제가 많이 생길 것 같습니다.
한번 시간 테스트를 해보겠습니다.
public class Test {
public static void main(String[] args) {
long start = System.currentTimeMillis();
Long sum = 0L;
for (long i = 0; i <= Integer.MAX_VALUE; i++) {
sum += i;
}
System.out.println(System.currentTimeMillis() - start); // 5382
}
}public class Test {
public static void main(String[] args) {
long start = System.currentTimeMillis();
long sum = 0L;
for (long i = 0; i <= Integer.MAX_VALUE; i++) {
sum += i;
}
System.out.println(System.currentTimeMillis() - start); // 551
}
}첫 번째 코드는 Long 타입으로 했을 때 시간을 측정했고, 두 번째 코드는 long 타입으로 했을 때 시간을 측정했는데 저의 컴퓨터에서는
거의 9배 10배정도의 시간 차이가 나는 것을 볼 수 있습니다.
따라서 불필요한 오토박싱을 피하려면 박스 타입 보다는 기본 타입을 사용해야 합니다.
이번 아이템 주제를 객체 생성은 비싸서 피해야 한다로 오해하지 않아야 합니다. 특히나 요즘의 JVM에서는 별다른 일을 하지 않는 작은 객체를 생성하고 회수하는
일이 크게 부담되지 않습니다.
아주 무거운 객체가 아닌 다음에야 단순히 객체 생성을 피하고자 우리만의 객체 풀(pool)을 만들지 않는 것이 좋습니다.
하지만 데이터베이스 연결 같은 경우 생성 비용이 워낙 비싸니 재사용하는 편이 낫습니다. 하지만 일반적으로는 자체 객체 풀은 코드를 헷갈리게 만들고 메모리 사용량을 늘려 성능을 떨어뜨립니다.
요즘 JVM의 가비지 컬렉터는 상당히 잘 최적화되어서 가벼운 객체용을 다룰 때는 직접 만든 객체 풀보다 훨씬 빠릅니다.
-
아이템 50:
새로운 객체를 만들어야 한다면 기존 객체를 재사용하지 마라- 방어적 복사가 필요한 상황에서 객체를 재사용했을 때의 피해가, 필요 없는 객체를 반복 생성했을 때의 피해보다 훨씬 크다는 사실을 기억해야 합니다.
- 방어적 복사에 실패하면 언제 터져 나올지 모르는 버그와 보안 구멍으로 이어지지만, 불필요한 객체 생성은 그저 코드 형태와 성능에만 영향을 줍니다.
-
아이템6 :
기존 객체를 재사용해야 한다면 새로운 객체를 만들지 마라