This is an accompaying report for the project-1 submission. Below we list some key details we will cover in our submission:
This report is a brief adaptation (for the purposes of the submission review) of the overview we gave in this blog post. If you have some time, I'd recommend checking the post (part-1, part-2, part-3), which discusses the following:
- Part-1: Description of the environment, code setup and Deep Q-learning overview.
- Part-2: Implementation details, testing tips and hyperparameters chosen, and an overview of the results.
- Part-3: Improvements overview (Double DQN and Prioritized Experience replay), implementation details, preliminary results, and final remarks.
In this section we give a brief description of the Deep Q-learning algorithm from [2], as our banana collector agent is based on the DQN agent from that paper. This description is a brief adaptation from the overview we gave in this post (part 1, section 3). We gave an intro and various details in that post so please, for further info about the algorithm refer to that post for a more detailed explanation.
TL;DR
Deep Q-learning is an algorithm that builds on top of Action-value function approximation to recover the optimal Action-value function Q*(s,a;θ), which is parametrized using a Deep Neural Network as function approximator for this Q-function. The changes introduced in [2], namely Experience Replay and Fixed Targets help break correlations and stabilize learning, which are problems that vanilla Action-value function approximation has.
Q-learning is an off-policy model-free value-based RL method that solves for the optimal policy Q*(s,a) via samples obtained from interactions with the environment. The Q-learning update rule used to update the q-value for a state-action pair (s,a) is shown in the following equation, and it tries to improve our estimates of the q-values for that pair by using another bootstrapped estimate (one-step look ahead) of the q-value.

This update rule is used in the Tabular Q-learning algorithm, which is used when dealing with small discrete state and action spaces. In this setup we can easily store the values for each possible state-action pair (s,a) in a table called Q-table, and update them separately with the previous update rule as we get information from the environment. Below we show the Tabular Q-learning algorithm (adapted from [1]).

Unfortunately, this tabular setup falls short when trying to scale up to more complicated environments, e.g. continuous state. We could discretize and use the tabular approach, but still we would have problems:
- Our Q-table would explode exponentially as we select a smaller discretization (curse of dimensionality).
- Our q-values would be updated separately, which is not that efficient nor "proper" as state-action pairs that are close in state-action space should have similar q-values. For example, updating the (s,a) entry (1.001 m, 0.001 N.m), where s is x-distance and a is torque, would not propagate to entry (1.002 m, 0.002 N.m) at all (would leave it untouch).
So we can alleviate these issues using function approximation. In this setup we parametrize our Q(s,a) with some function approximator and update this function approximator appropriately. The idea is that we would pass a representation of the state s and the action to take (still in discrete action-space land) to this function and it will evaluate the q-value for us. The representation we pass as input to our Q-function is usually some set of features created from the state s which our function can use. To avoid feature engineering we make use of deep neural networks as function approximators with the hope that these networks will lean the appropriate internal representation required for the task at hand, and we would only need to pass the raw state (and still discrete action) to evaluate the q-values.
Let's derive the semi-gradient method for action-value function approximation using neural networks. We start by defining our Q-function as a parametrized function of a neural networks of weights θ, which we write using the notation Q(s,a;θ). We then have to tweak the weights of the network appropriately. So, suppose we had access to the actual true q-values from Q*. We then just have to update our weights to fit these values, like in supervised learning. This can be written as an optimization problem, as shown in the following equation.

We could just then, as in supervised learning, update our weights using the gradient of the loss defined previously, as shown below.

If we use SGD we would end up with the following update rule:

We don't have access to these true q-values. Instead, we can make use the TD-target from Q-learning as estimates of these true q-values. This would give us the following update rule.

Putting it all together, we would end up with the following algorithm for Action-value function approximation.

Unfortunately, there are no convergence guarantees, and just using function approximation often leads to bad results due to unstable learning. In this context, Deep Q-learning, introduced in [2] helps to solve some of these issues by introducing two mechanisms that break some specific type correlations during learning, which help stabilize the learning process. These are explained below.
This mechanism consists of Learning from past stored experiences during replay sessions. Basically, we remember our experiences in memory (called a replay buffer) and learn from them later. This allows us to make more efficient use of past experiences by not throwing away samples right away, and it also helps to break one type of correlations: sequential correlations between experiences tuples. In the image below we try to depict this type of correlation by showing 3 consecutive experience tuples along a trajectory. Assuming we are doing one gradient update with each tuple using SGD we are then pushing our learned weights according to the reward obtained (recall the td-target is used as a true estimate for our algorithm). So, we are effectively pushing our weights using each sample, which in turn depended on the previous one (both reward and next state) because of the same process happening a time step before (the weights were pushed a bit using previous rewards).
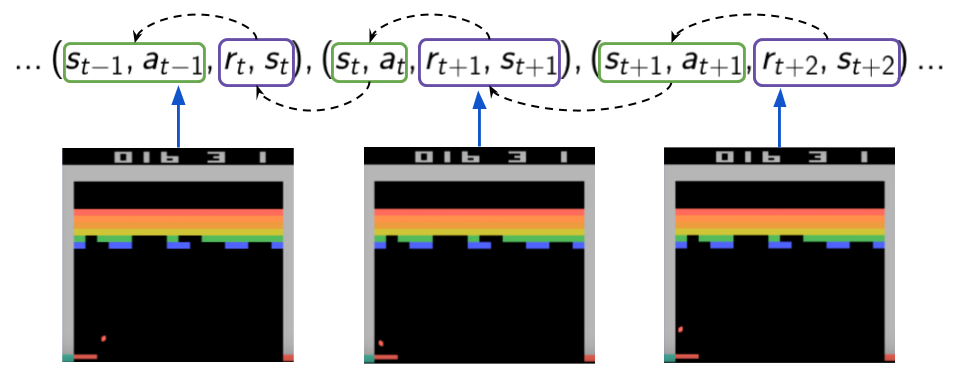
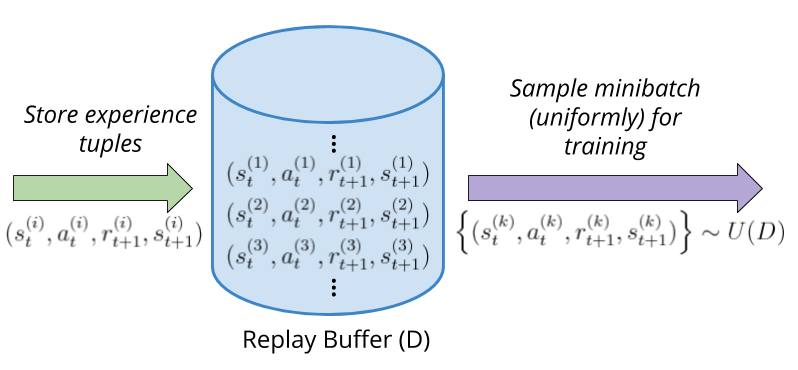
To solve these issues, the Experience Replay mechanism makes the agent learn from minibatches of past stored experience during training steps. We basically put all our experience in memory and then sample uniformly at random from it, which helps break the correlations between samples in the minibatch as they might not come from consequent steps (or even come from different episodes). This is depicted in the image below.
During training we are using the TD-target as the estimate of the true q-values that our Q-network should output for a specific pair (s,a) (as shown in the equation below). Unfortunately, this estimate is being computed using the current parameters of the Q-network which effectively is forcing us to follow a moving target. Besides, this is not mathematically correct, as we assumed these "true q-values" were not dependent on θ (recall we did not take the gradient of this term).

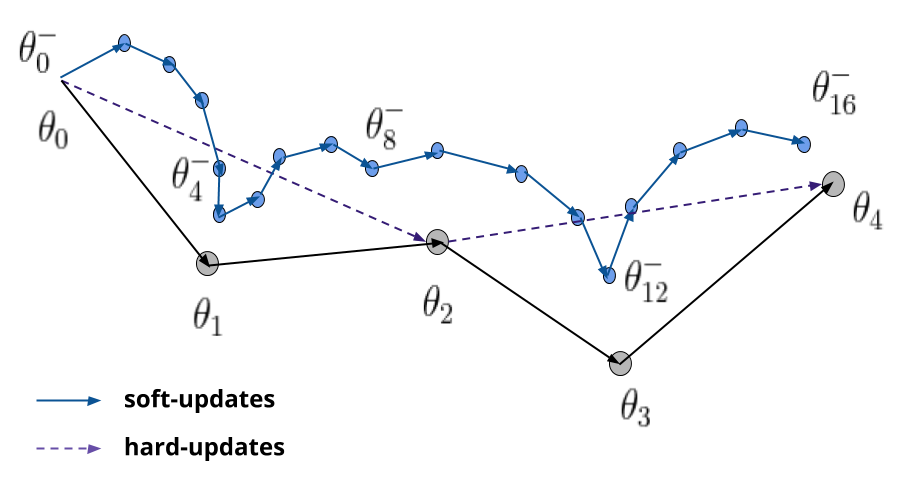
To help training stability the authors of [2] introduced the use of a separate network to compute these targets called a Target Network, which is almost the same as the network used for taking actions. The key difference is that the weights of this network are only copied from the weights of the other network after some specific number of steps. Therefore, the update rule can be modified as follows :

A slight variation to this update at constant intervals is to do updates every time step using interpolations, as shown in the following equation :

This are called soft-updates, and by adjusting the factor τ (to some small values) we get a similar effect of copying the weights of the networks after a fixed number of steps. The difference is that, as the name suggests, these updates are less jumpy than the hard-updates made by copying entirely the weights of the network. At convergence, this update is very similar to a hard-update as the network weights do not change too much.
By putting it all together we get the Deep Q-learning algorithm, which is show below:

Some key considerations to take into account are listed below:
This step consists in converting the states|observations s(t) received from the simulator into an appropriate state representation that can be used by our action-value network Q(φ,a;θ). We usually receive observations from the environment which in some cases (if we are lucky) consist of the actual internal state representation of the world. Unfortunately, in most cases we only receive observations that do not permit to fully recover the internal state of the environment. To avoid this issue we can design a state representation from these observations that would push us a bit more into the MDP setting and not the POMDP setting (Partially Observable MDP). In [2] the authors designed a state representation from the raw frame observations from the simulator by stacking a group of 4 consecutive frames, which tries to help encode a bit of temporal information (like speed and movement in the scene). This step is problem specific, and in our Banana collector case we chose to use the direct observations as state representation, although we could have made modifications to add more temporal information which could help with the problem of state aliasing. For further information on this topic you can watch part of this lecture from [7].
Grounding the estimates for terminal states is important because we don't want to make an estimate to the value for a terminal state bigger than what it could actually be. If we are just one step away of a terminal state, then our trajectories have length one and the return we obtain is actually only that reward. All previous algorithms do a check of whether or not a state is terminal in order to compute the appropriate TD-target. However, in tabular Q-learning you will find that in some implementations (unlike the one we presented earlier) there is no check similar to this one, but instead the entries of the Q-table are set to zeros for the terminal states, which is effectively the same as doing this check, as shown in the equation below:

Unfortunaly, because we are dealing with function approximation, the estimates for a terminal states if evaluated will not return always zero, even if we initialize the function approximator to output zeros everywhere (like initializing the weights of a neural network to all zeros). This is caused by the fact that changes in the approximator parameters will affect the values of nearby states-action pairs in state-action space as well even in the slightest. For further information, you could check this lecture by Volodymyr Mnih from [9]. So, keep this in mind when implementing your own version of DQN, as you might run into subtle bugs in your implementations.
Another important detail to keep in mind is the amount of exploration allowed by our ε-greedy mechanism, and how we reduce it as learning progresses. This aspect is not only important in this context of function approximation, but in general as it's a key tradeoff to take into account (exploration v.s. exploitation dilemma). They idea is to give the agent a big enough number of steps to explore and get experiences that actually land some diverse good and bad returns, and then start reducing this ammount of exploration as learning progresses towards convergence. The mechanism used in [2] is to linearly decay ε = 1.0 -> 0.1. Another method would be to decay it exponentially by multiplying ε with a constant decay factor every episode. For further information you could check this lecture by David Silver from [6].
The last detail is related to the actual choice we make how to model our Q-network. We have two choices: either treat both inputs s, a as a single input (s,a) to the network, which would allows us to compute one q-value for a given state-action pair, or use s as only input to the network and grab all the q-values for all actions a ∈ A. Both of these options are shown in the figure below.
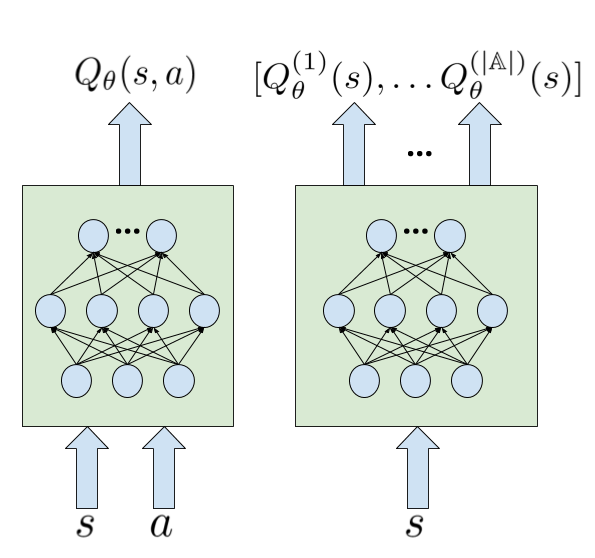
The first option would cost more as we need to compute all q-values in order to grab the maximum of them for both the TD-target calculation and the ε-greedy action selection. The second option was the one used in [2], and it's the one will use for our implementation.
As network architecture for our Q-network we chose to use 3 hidden fully connected layers (with ReLU activations) and 1 output layer (with no activation). The input to our network would be the state representation for our agent (output of the preprocess step φ). For our case we simply used the raw state as input to our network. This input (as explained in the README) consists of a rank-1 tensor of size 37. The output layer outputs 4 q-values for each possible action in the environment (as explained in the README). The image below shows this architecture.

In this section we give a brief description of our implementation of DQN, which is based in the original source code provided in [2] (link here), and also in the DQN solution provided by Udacity in the Lunar Lander mini-project. This description is a brief adaptation from the implementation overview we gave in this post (part 2, section 4).
Our DQN-Agent implementation consists of an abstract class that implements the Deep Q-learning with Soft-Updates algorithm presented previously, and various classes that inherit from this abstract class to work in the specific environments we will be dealing with (gridworld, gym environments, and the banana environment, as we will see later). Each one of these specific classes that inherit from the interface have to implement the preprocess method, which is the only virtual method left for each specific agent to handle each specific environment.
Below we show this interface (only the methods, to give a sense of how this interface works), which can be found in the agent.py file in the dqn/core folder of the navigation package. The key methods to be considered are the __init__, act, step, _preprocess and _learn methods, which implement most of the required steps of the DQN algorithm. We will discuss some of their details in snippets below, and we encourage the reader to look at the full implementation using the hyperlinks provided. Some might have some details removed (like dev. changes during testing), so they might look a bit different than the originals from the repo.
class IDqnAgent( object ) :
def __init__( self, agentConfig, modelConfig, modelBuilder, backendInitializer ) :
"""Constructs a generic Dqn agent, given configuration information
Args:
agentConfig (DqnAgentConfig) : config object with agent parameters
modelConfig (DqnModelConfig) : config object with model parameters
modelBuilder (function) : factory function to instantiate the model
backendInitializer (function) : function to be called to intialize specifics of each DL library
"""
###############################################
## IMPLEMENTATION HERE
###############################################
def save( self, filename ) :
"""Saves learned models into disk
Args:
filename (str) : filepath where we want to save the our model
"""
###############################################
## IMPLEMENTATION HERE
###############################################
def load( self, filename ) :
"""Loads a trained model from disk
Args:
filename (str) : filepath where we want to load our model from
"""
###############################################
## IMPLEMENTATION HERE
###############################################
def act( self, state, inference = False ) :
"""Returns an action to take from the given state
Args:
state (object) : state|observation coming from the simulator
inference (bool) : whether or not we are in inference mode
Returns:
int : action to take (assuming discrete actions space)
"""
###############################################
## IMPLEMENTATION HERE
###############################################
def step( self, transition ) :
"""Does one step of the learning algorithm, from Mnih et. al.
https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf
"""
###############################################
## IMPLEMENTATION HERE
###############################################
def _preprocess( self, rawState ) :
"""Preprocess a raw state into an appropriate state representation
Args:
rawState (np.ndarray) : raw state to be transformed
Returns:
np.ndarray : preprocess state into the approrpiate representation
"""
raise NotImplementedError( 'IDqnAgent::_preprocess> virtual method' )
def _learn( self ) :
"""Makes a learning step using the DQN algorithm from Mnih et. al.
https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf
"""
###############################################
## IMPLEMENTATION HERE
###############################################
@property
def epsilon( self ) :
return self._epsilon
@property
def seed( self ) :
return self._seed
@property
def learningMaxSteps( self ) :
return self._learningMaxSteps
@property
def actorModel( self ) :
return self._qmodel_actor
@property
def targetModel( self ) :
return self._qmodel_target
@property
def replayBuffer( self ) :
return self._rbuffer- First we have the __init__ method, whose implementation is shown briefly in the snippet below. This is the constructor of our agent and is in charge of copying the hyperparameters from the passed configuration objects, create the models (action-value and target action-value networks), create the replay buffer (or a priority-based replay buffer if requested) and some other initialization stuff. We get around having to decouple the specific model creation code by passing a factory method that takes care of this.
def __init__( self, agentConfig, modelConfig, modelBuilder, backendInitializer ) :
"""Constructs a generic Dqn agent, given configuration information
Args:
agentConfig (DqnAgentConfig) : config object with agent parameters
modelConfig (DqnModelConfig) : config object with model parameters
modelBuilder (function) : factory function to instantiate the model
backendInitializer (function) : function to be called to intialize specifics of each DL library
"""
##################################
## COPY HYPERPARAMETERS ##
##################################
# seed numpy's random number generator
np.random.seed( self._seed )
# create the model accordingly
self._qmodel_actor = modelBuilder( 'actor_model', modelConfig, True )
self._qmodel_target = modelBuilder( 'target_model', modelConfig, False )
##################################
## INITIALIZE MODELS ##
##################################
# start the target model from the actor model
self._qmodel_target.clone( self._qmodel_actor, tau = 1.0 )
# create the replay buffer
if self._usePrioritizedExpReplay :
self._rbuffer = prioritybuffer.PriorityBuffer( self._replayBufferSize,
self._seed )
else :
self._rbuffer = replaybuffer.DqnReplayBuffer( self._replayBufferSize,
self._seed )- The act method is in charge of deciding which action to take in a given state. This takes care of both the case of doing ε-greedy during training, and taking only the greedy action during inference. Note that in order to take the greedy actions we query the action-value network with the appropriate state representation in order to get the Q-values required to apply the argmax function
def act( self, state, inference = False ) :
"""Returns an action to take from the given state
Args:
state (object) : state|observation coming from the simulator
inference (bool) : whether or not we are in inference mode
Returns:
int : action to take (assuming discrete actions space)
"""
if inference or np.random.rand() > self._epsilon :
return np.argmax( self._qmodel_actor.eval( self._preprocess( state ) ) )
else :
return np.random.choice( self._nActions )- The step method implements most of the control flow of the DQN algorithm like adding experience tuples to the replay buffer, doing training every few steps (given by a frequency hyperparameter), doing copies of weights (or soft-updates) to the target network every few steps, doing some book keeping of the states, and applying the schedule to ε to control the ammount of exploration.
def step( self, transition ) :
"""Does one step of the learning algorithm, from Mnih et. al.
https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf
"""
# grab information from this transition
_s, _a, _snext, _r, _done = transition
# preprocess the raw state
self._nextState = self._preprocess( _snext )
if self._currState is None :
self._currState = self._preprocess( _s ) # for first step
# store in replay buffer
self._rbuffer.add( self._currState, _a, self._nextState, _r, _done )
# check if can do a training step
if self._istep > self._learningStartsAt and \
self._istep % self._learningUpdateFreq == 0 and \
len( self._rbuffer ) >= self._minibatchSize :
self._learn()
# update the parameters of the target model (every update_target steps)
if self._istep > self._learningStartsAt and \
self._istep % self._learningUpdateTargetFreq == 0 :
self._qmodel_target.clone( self._qmodel_actor, tau = self._tau )
# save next state (where we currently are in the environment) as current
self._currState = self._nextState
# update the agent's step counter
self._istep += 1
# and the episode counter if we finished an episode, and ...
# the states as well (I had a bug here, becasue I didn't ...
# reset the states).
if _done :
self._iepisode += 1
self._currState = None
self._nextState = None
# check epsilon update schedule and update accordingly
if self._epsSchedule == 'linear' :
# update epsilon using linear schedule
_epsFactor = 1. - ( max( 0, self._istep - self._learningStartsAt ) / self._epsSteps )
_epsDelta = max( 0, ( self._epsStart - self._epsEnd ) * _epsFactor )
self._epsilon = self._epsEnd + _epsDelta
elif self._epsSchedule == 'geometric' :
if _done :
# update epsilon with a geometric decay given by a decay factor
_epsFactor = self._epsDecay if self._istep >= self._learningStartsAt else 1.0
self._epsilon = max( self._epsEnd, self._epsilon * _epsFactor )- The _preprocess (as mentioned earlier) is a virtual method that has to be implemented by the actual concretions. It receives the observations from the simulator and returns the appropriate state representation to use. Some sample implementations for the BananaSimple-agent, BananaVisual-agent and Gridworld-agent are shown in the snippets that follow.
def _preprocess( self, rawState ) :
"""Preprocess a raw state into an appropriate state representation
Args:
rawState (np.ndarray) : raw state to be transformed
Returns:
np.ndarray : preprocess state into the approrpiate representation
"""
""" OVERRIDE this method with your specific preprocessing """
raise NotImplementedError( 'IDqnAgent::_preprocess> virtual method' ) ###############################################
## Simple (just copy) preprocessing ##
###############################################
def _preprocess( self, rawState ) :
# rawState is a vector-observation, so just copy it
return rawState.copy() ###############################################
## One-hot encoding preprocessing ##
###############################################
def _preprocess( self, rawState ) :
# rawState is an index, so convert it to a one-hot representation
_stateOneHot = np.zeros( self._stateDim )
_stateOneHot[rawState] = 1.0
return _stateOneHot ################################################
## Stack 4 frames into vol. preprocessing ##
################################################
def _preprocess( self, rawState ) :
# if queue is empty, just repeat this rawState -------------------------
if len( self._frames ) < 1 :
for _ in range( 4 ) :
self._frames.append( rawState )
# ----------------------------------------------------------------------
# send this rawState to the queue
self._frames.append( rawState )
# grab the states to be preprocessed
_frames = list( self._frames )
if USE_GRAYSCALE :
# convert each frame into grayscale
_frames = [ 0.299 * rgb[0,...] + 0.587 * rgb[1,...] + 0.114 * rgb[2,...] \
for rgb in _frames ]
_frames = np.stack( _frames )
else :
_frames = np.concatenate( _frames )
return _frames- The _learn method is the one in charge of doing the actual training. As explained in the algorithm we first sample a minibatch from the replay buffer, compute the TD-targets (in a vectorized way) and request a step of SGD using the just computed TD-targets and the experiences in the minibatch.
def _learn( self ) :
"""Makes a learning step using the DQN algorithm from Mnih et. al.
https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf
"""
# get a minibatch from the replay buffer
_minibatch = self._rbuffer.sample( self._minibatchSize )
_states, _actions, _nextStates, _rewards, _dones = _minibatch
# compute targets using the target network in a "vectorized" way
_qtargets = _rewards + ( 1 - _dones ) * self._gamma * \
np.max( self._qmodel_target.eval( _nextStates ), 1 )
# casting to float32 (to avoid errors due different tensor types)
_qtargets = _qtargets.astype( np.float32 )
# make the learning call to the model (kind of like supervised setting)
self._qmodel_actor.train( _states, _actions, _qtargets )- Finally, there are some specific concretions of this interface (as we mentioned earlier). We already showed the required implementation of the _preprocess method but, for completeness, you can find these concretions in the agent_raycast.py, agent_gridworld.py, and agent_visual.py.
We implemented a common interface for the model, as we wanted to decouple it from any Deep Learning library that we could use (like tensorflow or pytorch). The idea is that each specific model implements this interface accordingly, and adds its own library-specific functionality. The descriptions of all virtual methods that the backend-specific models have to implement are :
- build : build the architecture of the model (either using keras or torch.nn).
- eval : computes all q-values for a given state doing a forward pass.
- train : performs SGD (or some other optimizer) with the TD-targets as true q-values to fit.
- clone : implements soft-updates from another IDqnModel
Below we show the IDqnModel interface, which you can find in this file.
class IDqnModel( object ) :
def __init__( self, name, modelConfig, trainable ) :
super( IDqnModel, self ).__init__()
##################################
## COPY CONFIGURATION DATA ##
##################################
def build( self ) :
raise NotImplementedError( 'IDqnModel::build> virtual method' )
def eval( self, state ) :
raise NotImplementedError( 'IDqnModel::eval> virtual method' )
def train( self, states, actions, targets ) :
raise NotImplementedError( 'IDqnModel::train> virtual method' )
def clone( self, other, tau = 1.0 ) :
raise NotImplementedError( 'IDqnModel::clone> virtual method' )
def save( self, filename ) :
raise NotImplementedError( 'IDqnModel::save> virtual method' )
def load( self, filename ) :
raise NotImplementedError( 'IDqnModel::load> virtual method' )
def initialize( self, args ) :
raise NotImplementedError( 'IDqnModel::initialize> virtual method' )
@property
def losses( self ) :
return self._losses
@property
def name( self ) :
return self._name
@property
def trainable( self ) :
return self._trainable
@property
def useImpSampling( self ) :
return self._useImpSampling
@property
def gradients( self ) :
return self._gradients
@property
def bellmanErrors( self ) :
return self._bellmanErrors- The model_pytorch.py file contains a concrete implementation of the model interface using Pytorch as Deep Learning library. Below there is a snippet with most of the contents of this file. The DqnModelPytorch class serves as a proxy for the actual network implemented in a standard way using the torch.nn module and the torch.nn.Module class. Recall that the eval method is used for two purposes: computing the q-values for the action decision, and computing the q-targets for learning. We have to make sure this evaluation is not considered for gradients computations. We make use of torch.no_grad to ensure this requirement.We only have to compute gradients w.r.t. the weights of the action-value network Q(.;θ) during the training step, which is done automatically when the computation graph includes it for gradients computation when calling the network on the inputs { (s,a) } from the minibatch (see train method).
class NetworkPytorchCustom( nn.Module ) :
def __init__( self, inputShape, outputShape, layersDefs ) :
super( NetworkPytorchCustom, self ).__init__()
# banana-raycast has a 37-vector as an observation (rank-1 tensor)
assert len( inputShape ) == 1, 'ERROR> input should be a rank-1 tensor'
# and also has a discrete set of actions, with a 4-vector for its qvalues
assert len( outputShape ) == 1, 'ERROR> output should be rank-1 tensor'
self._inputShape = inputShape
self._outputShape = outputShape
# define layers for this network
self.fc1 = nn.Linear( self._inputShape[0], 128 )
self.fc2 = nn.Linear( 128, 64 )
self.fc3 = nn.Linear( 64, 16 )
self.fc4 = nn.Linear( 16, self._outputShape[0] )
self.h1 = None
self.h2 = None
self.h3 = None
self.out = None
def forward( self, X ) :
self.h1 = F.relu( self.fc1( X ) )
self.h2 = F.relu( self.fc2( self.h1 ) )
self.h3 = F.relu( self.fc3( self.h2 ) )
self.out = self.fc4( self.h3 )
return self.out
def clone( self, other, tau ) :
for _thisParams, _otherParams in zip( self.parameters(), other.parameters() ) :
_thisParams.data.copy_( ( 1. - tau ) * _thisParams.data + ( tau ) * _otherParams.data )
class DqnModelPytorch( model.IDqnModel ) :
def __init__( self, name, modelConfig, trainable ) :
super( DqnModelPytorch, self ).__init__( name, modelConfig, trainable )
def build( self ) :
self._nnetwork = NetworkPytorchCustom( self._inputShape,
self._outputShape,
self._layersDefs )
def initialize( self, args ) :
# grab current pytorch device
self._device = args['device']
# send network to device
self._nnetwork.to( self._device )
# create train functionality if necessary
if self._trainable :
self._lossFcn = nn.MSELoss()
self._optimizer = optim.Adam( self._nnetwork.parameters(), lr = self._lr )
def eval( self, state, inference = False ) :
_xx = torch.from_numpy( state ).float().to( self._device )
self._nnetwork.eval()
with torch.no_grad() :
_qvalues = self._nnetwork( _xx ).cpu().data.numpy()
self._nnetwork.train()
return _qvalues
def train( self, states, actions, targets, impSampWeights = None ) :
if not self._trainable :
print( 'WARNING> tried training a non-trainable model' )
return None
_aa = torch.from_numpy( actions ).unsqueeze( 1 ).to( self._device )
_xx = torch.from_numpy( states ).float().to( self._device )
_yy = torch.from_numpy( targets ).float().unsqueeze( 1 ).to( self._device )
# reset the gradients buffer
self._optimizer.zero_grad()
# do forward pass to compute q-target predictions
_yyhat = self._nnetwork( _xx ).gather( 1, _aa )
# and compute loss and gradients
_loss = self._lossFcn( _yyhat, _yy )
_loss.backward()
# compute bellman errors (either for saving or for prioritized exp. replay)
with torch.no_grad() :
_absBellmanErrors = torch.abs( _yy - _yyhat ).cpu().numpy()
# run optimizer to update the weights
self._optimizer.step()
# grab loss for later saving
self._losses.append( _loss.item() )
return _absBellmanErrors
def clone( self, other, tau = 1.0 ) :
self._nnetwork.clone( other._nnetwork, tau )
def save( self, filename ) :
if self._nnetwork :
torch.save( self._nnetwork.state_dict(), filename )
def load( self, filename ) :
if self._nnetwork :
self._nnetwork.load_state_dict( torch.load( filename ) )- The model_tensorflow.py file contains a concrete implementation of the model interface using Tensorflow as Deep Learning library. Below there is a snippet with most of the contents of this file. The DqnModelTensorflow class serves a container for the Tensorflow Ops created for the computation graph that implements the required evaluation and training steps. For the architecture, instead of creating tf ops for each layer, we decided to just use keras to create the required ops of the q-networks internally (see the createNetworkCustom function), and then build on top of them by creating other ops required for training and evaluation (see the build method). Because we are creating a static graph beforehand it makes it easier to see where we are going to have gradients being computed and used. If our model has its _trainable flag set to false we then just create the required ops for evaluation only (used for computing the TD-targets), whereas, if our model is trainable, we create the full computation graph which goes from inputs (minibatch { (s,a) }) to the MSE loss using the estimates from the network and the TD-targets passed for training.
def createNetworkCustom( inputShape, outputShape, layersDefs ) :
# vector as an observation (rank-1 tensor)
assert len( inputShape ) == 1, 'ERROR> input should be a rank-1 tensor'
# and also discrete actions , with a 4-vector for its qvalues
assert len( outputShape ) == 1, 'ERROR> output should be rank-1 tensor'
# keep things simple (use keras for core model definition)
_networkOps = keras.Sequential()
# define initializers
_kernelInitializer = keras.initializers.glorot_normal( seed = 0 )
_biasInitializer = keras.initializers.Zeros()
# add the layers for our test-case
_networkOps.add( keras.layers.Dense( 128, activation = 'relu', input_shape = inputShape, kernel_initializer = _kernelInitializer, bias_initializer = _biasInitializer ) )
_networkOps.add( keras.layers.Dense( 64, activation = 'relu', kernel_initializer = _kernelInitializer, bias_initializer = _biasInitializer ) )
_networkOps.add( keras.layers.Dense( 16, activation = 'relu', kernel_initializer = _kernelInitializer, bias_initializer = _biasInitializer ) )
_networkOps.add( keras.layers.Dense( outputShape[0], kernel_initializer = _kernelInitializer, bias_initializer = _biasInitializer ) )
return _networkOps
class DqnModelTensorflow( model.IDqnModel ) :
def __init__( self, name, modelConfig, trainable ) :
super( DqnModelTensorflow, self ).__init__( name, modelConfig, trainable )
def build( self ) :
# placeholder for state inputs
self._tfStates = tf.placeholder( tf.float32, (None,) + self._inputShape )
# create the nnetwork model architecture
self._nnetwork = createNetworkCustom( self._inputShape,
self._outputShape,
self._layersDefs )
# create the ops for evaluating the output of the model (Q(s,:))
self._opQhat_s = self._nnetwork( self._tfStates )
# if trainable (action network), create the full resources
if self._trainable :
# placeholders: actions, act-indices (gather), and computed q-targets
self._tfActions = tf.placeholder( tf.int32, (None,) )
self._tfActionsIndices = tf.placeholder( tf.int32, (None,) )
self._tfQTargets = tf.placeholder( tf.float32, (None,) )
# @TODO|CHECK: Change the gather call by multiply + one-hot.
# Create the ops for getting the Q(s,a) for each batch of (states) + (actions) ...
# using tf.gather_nd, and expanding action indices with batch indices
self._opActionsWithIndices = tf.stack( [self._tfActionsIndices, self._tfActions], axis = 1 )
self._opQhat_sa = tf.gather_nd( self._opQhat_s, self._opActionsWithIndices )
# create ops for the loss function
self._opLoss = tf.losses.mean_squared_error( self._tfQTargets, self._opQhat_sa )
# create ops for the loss and optimizer
self._optimizer = tf.train.AdamOptimizer( learning_rate = self._lr )
self._opOptim = self._optimizer.minimize( self._opLoss, var_list = self._nnetwork.trainable_weights )
# tf.Session, passed by the backend-initializer
self._sess = None
def initialize( self, args ) :
# grab session and initialize
self._sess = args['session']
def eval( self, state, inference = False ) :
# unsqueeze if it's not a batch
_batchStates = [state] if state.ndim == 1 else state
_qvalues = self._sess.run( self._opQhat_s, feed_dict = { self._tfStates : _batchStates } )
return _qvalues
def train( self, states, actions, targets, impSampWeights = None ) :
if not self._trainable :
print( 'WARNING> tried training a non-trainable model' )
return None
# for gather functionality
_actionsIndices = np.arange( actions.shape[0] )
# dictionary to feed to placeholders
_feedDict = { self._tfStates : states,
self._tfActions : actions,
self._tfActionsIndices : _actionsIndices,
self._tfQTargets : targets }
# run the session
_, _loss = self._sess.run( [ self._opOptim, self._opLoss ], _feedDict )
# grab loss for later statistics
self._losses.append( _loss )
def clone( self, other, tau = 1.0 ) :
_srcWeights = self._nnetwork.get_weights()
_dstWeights = other._nnetwork.get_weights()
_weights = []
for i in range( len( _srcWeights ) ) :
_weights.append( ( 1. - tau ) * _srcWeights[i] + ( tau ) * _dstWeights[i] )
self._nnetwork.set_weights( _weights )
def save( self, filename ) :
self._nnetwork.save_weights( filename )
def load( self, filename ) :
self._nnetwork.load_weights( filename )We also implemented the replay buffer in an abstract way in order to just swap the implementations of a simple replay buffer and a prioritized replay buffer once we had both implementations. This interface (which you can find in the buffer.py file) is simpler than the others. Basically, we just need a data structure where to store experience tuples, and a way to sample a small batch of experience tuples. Below we show the implementation of this interface.
class IBuffer( object ) :
def __init__( self, bufferSize, randomSeed ) :
super( IBuffer, self ).__init__()
# capacity of the buffer
self._bufferSize = bufferSize
# seed for random number generator (either numpy's or python's)
self._randomSeed = randomSeed
def add( self, state, action, nextState, reward, endFlag ) :
"""Adds a transition tuple into memory
Args:
state (object) : state at timestep t
action (int) : action taken at timestep t
nextState (object) : state from timestep t+1
reward (float) : reward obtained from (state,action)
endFlag (bool) : whether or not nextState is terminal
"""
raise NotImplementedError( 'IBuffer::add> virtual method' )
def sample( self, batchSize ) :
"""Adds a transition tuple into memory
Args:
batchSize (int) : number of experience tuples to grab from memory
Returns:
list : a list of experience tuples
"""
raise NotImplementedError( 'IBuffer::sample> virtual method' )
def __len__( self ) :
raise NotImplementedError( 'IBuffer::__len__> virtual method' )The non-prioritized replay buffer (as in [2]) is implemented (snippet shown below) using a double ended queue (deque from python's collections module). We also implemented a prioritized replay buffer for Prioritized Experience Replay. This will be discussed in an improvements section later.
class DqnReplayBuffer( buffer.IBuffer ) :
def __init__( self, bufferSize, randomSeed ) :
super( DqnReplayBuffer, self ).__init__( bufferSize, randomSeed )
self._experience = namedtuple( 'Step',
field_names = [ 'state',
'action',
'reward',
'nextState',
'endFlag' ] )
self._memory = deque( maxlen = bufferSize )
# seed random generator (@TODO: What is the behav. with multi-agents?)
random.seed( randomSeed )
def add( self, state, action, nextState, reward, endFlag ) :
# create a experience object from the arguments
_expObj = self._experience( state, action, reward, nextState, endFlag )
# and add it to the deque memory
self._memory.append( _expObj )
def sample( self, batchSize ) :
# grab a batch from the deque memory
_expBatch = random.sample( self._memory, batchSize )
# stack each experience component along batch axis
_states = np.stack( [ _exp.state for _exp in _expBatch if _exp is not None ] )
_actions = np.stack( [ _exp.action for _exp in _expBatch if _exp is not None ] )
_rewards = np.stack( [ _exp.reward for _exp in _expBatch if _exp is not None ] )
_nextStates = np.stack( [ _exp.nextState for _exp in _expBatch if _exp is not None ] )
_endFlags = np.stack( [ _exp.endFlag for _exp in _expBatch if _exp is not None ] ).astype( np.uint8 )
return _states, _actions, _nextStates, _rewards, _endFlags
def __len__( self ) :
return len( self._memory )All the previously mentioned components are used via a single trainer, which is in charge of all functionality used for training and evaluation, like:
- Creating the environment to be studied.
- Implementing the RL loops for either training or testing.
- Loading and saving configuration files for different tests.
- Saving statistics from training for later analysis.
Below there's a full snippet of the trainer.py file that implements this functionality:
import os
import numpy as np
import argparse
import time
from tqdm import tqdm
from collections import deque
from collections import defaultdict
# imports from navigation package
from navigation import agent_raycast # agent for the raycast-based environment
from navigation import model_pytorch # pytorch-based model
from navigation import model_tensorflow # tensorflow-based model
from navigation.envs import mlagents # simple environment wrapper
from navigation.dqn.utils import config # config. functionality (load-save)
# logging functionality
import logger
from IPython.core.debugger import set_trace
TEST = True # global variable, set by the argparser
TIME_START = 0 # global variable, set in __main__
RESULTS_FOLDER = 'results' # global variable, where to place the results of training
SEED = 0 # global variable, set by argparser
CONFIG_AGENT = '' # global variable, set by argparser
CONFIG_MODEL = '' # global variable, set by argparser
USE_DOUBLE_DQN = False # global variable, set by argparser
USE_PRIORITIZED_EXPERIENCE_REPLAY = False # global variable, set by argparser
USE_DUELING_DQN = False # global variable, set by argparser
def train( env, agent, sessionId, savefile, resultsFilename, replayFilename ) :
MAX_EPISODES = agent.learningMaxSteps
MAX_STEPS_EPISODE = 1000
LOG_WINDOW_SIZE = 100
_progressbar = tqdm( range( 1, MAX_EPISODES + 1 ), desc = 'Training>', leave = True )
_maxAvgScore = -np.inf
_scores = []
_scoresAvgs = []
_scoresWindow = deque( maxlen = LOG_WINDOW_SIZE )
_stepsWindow = deque( maxlen = LOG_WINDOW_SIZE )
_timeStart = TIME_START
for iepisode in _progressbar :
_state = env.reset( training = True )
_score = 0
_nsteps = 0
while True :
# grab action from dqn agent: runs through model, e-greedy, etc.
_action = agent.act( _state, inference = False )
# apply action in simulator to get the transition
_snext, _reward, _done, _ = env.step( _action )
## env.render()
_transition = ( _state, _action, _snext, _reward, _done )
# send this transition back to the agent (to learn when he pleases)
## set_trace()
agent.step( _transition )
# prepare for next iteration
_state = _snext
_score += _reward
_nsteps += 1
if _done :
break
_scores.append( _score )
_scoresWindow.append( _score )
_stepsWindow.append( _nsteps )
if iepisode >= LOG_WINDOW_SIZE :
_avgScore = np.mean( _scoresWindow )
_avgSteps = np.mean( _stepsWindow )
_scoresAvgs.append( _avgScore )
if _avgScore > _maxAvgScore :
_maxAvgScore = _avgScore
# log resultss
if agent._usePrioritizedExpReplay :
_progressbar.set_description( 'Training> Max-Avg=%.2f, Curr-Avg=%.2f, Curr=%.2f, Eps=%.2f, Beta=%.2f' % (_maxAvgScore, _avgScore, _score, agent.epsilon, agent._rbuffer.beta ) )
else :
_progressbar.set_description( 'Training> Max-Avg=%.2f, Curr-Avg=%.2f, Curr=%.2f, Eps=%.2f' % (_maxAvgScore, _avgScore, _score, agent.epsilon ) )
_progressbar.refresh()
# save trained model
agent.save( savefile )
_timeStop = int( time.time() )
_trainingTime = _timeStop - _timeStart
# save training results for later visualization and analysis
logger.saveTrainingResults( resultsFilename,
sessionId,
_timeStart,
_scores,
_scoresAvgs,
agent.actorModel.losses,
agent.actorModel.bellmanErrors,
agent.actorModel.gradients )
# save replay batch for later visualization and analysis
_minibatch = agent.replayBuffer.sample( 100 )
_ss, _aa, _rr, _ssnext = _minibatch[0], _minibatch[1], _minibatch[2], _minibatch[3]
_q_s_batch = [ agent.actorModel.eval( agent._preprocess( state ) ) \
for state in _ss ]
_replayBatch = { 'states' : _ss, 'actions' : _aa, 'rewards' : _rr, 'nextStates' : _ssnext }
logger.saveReplayBatch( replayFilename,
sessionId,
TIME_START,
_replayBatch,
_q_s_batch )
def test( env, agent ) :
_progressbar = tqdm( range( 1, 10 + 1 ), desc = 'Testing>', leave = True )
for _ in _progressbar :
_state = env.reset( training = False )
_score = 0.0
_goodBananas = 0
_badBananas = 0
while True :
_action = agent.act( _state, inference = True )
_state, _reward, _done, _ = env.step( _action )
if _reward > 0 :
_goodBananas += 1
_progressbar.write( 'Got banana! :D. So far: %d' % _goodBananas )
elif _reward < 0 :
_badBananas += 1
_progressbar.write( 'Got bad banana :/. So far: %d' % _badBananas )
_score += _reward
if _done :
break
_progressbar.set_description( 'Testing> Score=%.2f' % ( _score ) )
_progressbar.refresh()
def experiment( sessionId,
library,
savefile,
resultsFilename,
replayFilename,
agentConfigFilename,
modelConfigFilename ) :
# grab factory-method for the model according to the library requested
_modelBuilder = model_pytorch.DqnModelBuilder if library == 'pytorch' \
else model_tensorflow.DqnModelBuilder
# grab initialization-method for the model according to the library requested
_backendInitializer = model_pytorch.BackendInitializer if library == 'pytorch' \
else model_tensorflow.BackendInitializer
# paths to the environment executables
_bananaExecPath = os.path.join( os.getcwd(), 'executables/Banana_Linux/Banana.x86_64' )
_bananaHeadlessExecPath = os.path.join( os.getcwd(), 'executables/Banana_Linux_NoVis/Banana.x86_64' )
if CONFIG_AGENT != '' :
agent_raycast.AGENT_CONFIG = config.DqnAgentConfig.load( CONFIG_AGENT )
if CONFIG_MODEL != '' :
agent_raycast.MODEL_CONFIG = config.DqnModelConfig.load( CONFIG_MODEL )
# instantiate the environment
_env = mlagents.createDiscreteActionsEnv( _bananaExecPath, seed = SEED )
# set the seed for the agent
agent_raycast.AGENT_CONFIG.seed = SEED
# set improvement flags
agent_raycast.AGENT_CONFIG.useDoubleDqn = USE_DOUBLE_DQN
agent_raycast.AGENT_CONFIG.usePrioritizedExpReplay = USE_PRIORITIZED_EXPERIENCE_REPLAY
agent_raycast.AGENT_CONFIG.useDuelingDqn = USE_DUELING_DQN
_agent = agent_raycast.CreateAgent( agent_raycast.AGENT_CONFIG,
agent_raycast.MODEL_CONFIG,
_modelBuilder,
_backendInitializer )
# save agent and model configurations
config.DqnAgentConfig.save( agent_raycast.AGENT_CONFIG, agentConfigFilename )
config.DqnModelConfig.save( agent_raycast.MODEL_CONFIG, modelConfigFilename )
if not TEST :
train( _env, _agent, sessionId, savefile, resultsFilename, replayFilename )
else :
_agent.load( _savefile )
test( _env, _agent )
if __name__ == '__main__' :
_parser = argparse.ArgumentParser()
_parser.add_argument( 'mode',
help = 'mode of execution (train|test)',
type = str,
choices = [ 'train', 'test' ] )
_parser.add_argument( '--library',
help = 'deep learning library to use (pytorch|tensorflow)',
type = str,
choices = [ 'pytorch','tensorflow' ],
default = 'pytorch' )
_parser.add_argument( '--sessionId',
help = 'identifier of this training run',
type = str,
default = 'banana_simple' )
_parser.add_argument( '--seed',
help = 'random seed for the environment and generators',
type = int,
default = 0 )
_parser.add_argument( '--visual',
help = 'whether or not use the visual-banana environment',
type = str,
default = 'false' )
_parser.add_argument( '--ddqn',
help = 'whether or not to use double dqn (true|false)',
type = str,
default = 'false' )
_parser.add_argument( '--prioritizedExpReplay',
help = 'whether or not to use prioritized experience replay (true|false)',
type = str,
default = 'false' )
_parser.add_argument( '--duelingDqn',
help = 'whether or not to use dueling dqn (true|false)',
type = str,
default = 'false' )
_parser.add_argument( '--configAgent',
help = 'configuration file for the agent (hyperparameters, etc.)',
type = str,
default = '' )
_parser.add_argument( '--configModel',
help = 'configuration file for the model (architecture, etc.)',
type = str,
default = '' )
_args = _parser.parse_args()
# whether or not we are in test mode
TEST = ( _args.mode == 'test' )
# the actual seed for the environment
SEED = _args.seed
# timestamp of the start of execution
TIME_START = int( time.time() )
_sessionfolder = os.path.join( RESULTS_FOLDER, _args.sessionId )
if not os.path.exists( _sessionfolder ) :
os.makedirs( _sessionfolder )
# file where to save the trained model
_savefile = _args.sessionId
_savefile += '_model_'
_savefile += _args.library
_savefile += ( '.pth' if _args.library == 'pytorch' else '.h5' )
_savefile = os.path.join( _sessionfolder, _savefile )
# file where to save the training results statistics
_resultsFilename = os.path.join( _sessionfolder,
_args.sessionId + '_results.pkl' )
# file where to save the replay information (for further extra analysis)
_replayFilename = os.path.join( _sessionfolder,
_args.sessionId + '_replay.pkl' )
# configuration files for this training session
_agentConfigFilename = os.path.join( _sessionfolder, _args.sessionId + '_agentconfig.json' )
_modelConfigFilename = os.path.join( _sessionfolder, _args.sessionId + '_modelconfig.json' )
# whether or not use the visual-banana environment
VISUAL = ( _args.visual.lower() == 'true' )
# DQN improvements options
USE_DOUBLE_DQN = ( _args.ddqn.lower() == 'true' )
USE_PRIORITIZED_EXPERIENCE_REPLAY = ( _args.prioritizedExpReplay.lower() == 'true' )
USE_DUELING_DQN = ( _args.duelingDqn.lower() == 'true' )
# Configuration files with training information (provided by the user)
CONFIG_AGENT = _args.configAgent
CONFIG_MODEL = _args.configModel
print( '#############################################################' )
print( '# #' )
print( '# Environment and agent setup #' )
print( '# #' )
print( '#############################################################' )
print( 'Mode : ', _args.mode )
print( 'Library : ', _args.library )
print( 'SessionId : ', _args.sessionId )
print( 'Savefile : ', _savefile )
print( 'ResultsFilename : ', _resultsFilename )
print( 'ReplayFilename : ', _replayFilename )
print( 'AgentConfigFilename : ', _agentConfigFilename )
print( 'ModelConfigFilename : ', _modelConfigFilename )
print( 'VisualBanana : ', _args.visual )
print( 'DoubleDqn : ', _args.ddqn )
print( 'PrioritizedExpReplay : ', _args.prioritizedExpReplay )
print( 'DuelingDqn : ', _args.duelingDqn )
print( 'Agent config file : ', 'None' if _args.configAgent == '' else _args.configAgent )
print( 'Model config file : ', 'None' if _args.configModel == '' else _args.configModel )
print( '#############################################################' )
experiment( _args.sessionId,
_args.library,
_savefile,
_resultsFilename,
_replayFilename,
_agentConfigFilename,
_modelConfigFilename )This trainer came in handy when running various training sessions with different configurations for some ablation tests (we did not mention it, but the agent receives configuration objects that can be loaded and saved using .json files).
Finally, note that we developed a small wrapper on top of our ml-agents environment itself, in order to make it follow a more standard (and gym-like) way. Unity ml-agents has also an API for this, but as we are using an older version of the library we might had run into some issues, so we decided just to go with a simple env. wrapper and call it a day. Note that we also wanted to go for a standard gym-like API in order to reuse a simple Gridworld env. for testing purposes.
The hyperparameters were tuned from the starting hyperparameters of the DQN solution provided for the Lunar Lander. We didn't run exhaustive tests (neither grid nor random search) to tune the hyperparameters, but just incrementally increased/decreased some hyperparameters we considered important:
-
Replay Buffer size: too low of a replay buffer size (around 10^4) gave us poor performance even though we made various changes in the other hyperparameters to make it work. We then decided to gradually increase it until it could more or less solve the task, and finally set it at around 10^5 in size.
-
Epsilon schedule: We exponentially decreased exploration via a decay factor applied at every end of episode, and keeping ε fixed thereafter. Low exploration over all training steps led to poor performance, so we gradually increased it until we started getting good performance. The calculations we made to consider how much to increase were based on for how long would the exploration be active (until fixed at a certain value), how many training steps were available and how big was our replay buffer.
All other hyperparameters were kept roughly to the same values as the baseline provided by the DQN solution from Udacity, as based on these values they provided some initial training curves that showed that with their configuration we should be able to get good results.
-
The max. number of steps was kept fixed to the baseline value provided, as they showed that at max. 1800 steps a working solution should be able to already solve the task.
-
The learning rate and soft-updates factor was kept also the same as the baseline, as we consider these values to be small enough to not introduce instabilities during learning. We actually had an issue related to a wrong interpolation which made learning stable for test cases like lunar lander, but unstable for the banana environment. We were using as update rule θ(-) := τ θ(-) + (1-τ) θ, but the correct update rule was θ(-) := (1-τ) θ(-) + τ θ. As we were using a very small τ, we were effectively running our experiements with hard-updates at a very high frequency (1 update per 4 steps) instead of soft-updates. This seemed to be working fine for the Lunar Lander environment (we increased τ to make it work), but didn't work at all in the banana environment.
-
The minibatch size was kept the same (64). As we are not using any big network nor using high dimensional inputs (like images) we don't actually have to worry much about our GPU being able to allocate resources for a bigger batch (so we could have set a bigger batch size), but we decided it to keep it that way. It would be interesting though to see the effect that the batch size has during learning. Of course, it'd take a bit longer to take a SGD step, but perhaps by taking a "smoother" gradient step we could get better/smoother learning.
The hyperparameters chosen for our submission (found in the config_submission.json file) are shown below:
"stateDim" : 37,
"nActions" : 4,
"epsilonStart" : 1.0,
"epsilonEnd" : 0.01,
"epsilonSteps" : -1,
"epsilonDecay" : 0.9975,
"epsilonSchedule" : "geometric",
"lr" : 0.0005,
"minibatchSize" : 64,
"learningStartsAt" : 0,
"learningUpdateFreq" : 4,
"learningUpdateTargetFreq" : 4,
"learningMaxSteps" : 2000,
"replayBufferSize" : 100000,
"discount" : 0.999,
"tau" : 0.001,
"seed" : 0,
"useDoubleDqn" : false,
"usePrioritizedExpReplay" : false,
"useDuelingDqn" : false
We implemented the following improvements to the base DQN implementation:
- Double Q-learning (DDQN)
- Prioritized Experience Replay (PER)
For a detailed explanation of these improvements, and the related implementation, please refer to part-3 of the accompying post we made (section 7).
In this section we show the results of our submission, which were obtained through various runs and with various seeds. The results are presented in the form of time series plots each over a single run, and standard deviation plots over a set of similar runs. We will also show the results of one of three experiments we made with different configurations. This experiment did not include the improvements (DDQN, PER), which are going to be explained in a later section. The results can be found also in the results_analysis.ipynb. However, due to the size of the training sessions, we decided not to upload most of the results (apart from a single run for the submission) due to the file size of the combined training sessions. Still, to reproduce the same experiments just run the provided bash scripts:
- training_submission.sh : to run the base experiments for the submissions
- training_tests_1.sh : to run the first experiment, related to exploration tests
- training_tests_2.sh : to run the second experiment, related to how much the improvements (DDQN and PER) to DQN help.
- training_tests_3.sh : to run the third experiment, to check if our implementations of DDQN and PER actually helps in some setups with little exploration.
We provide a trained agent (trained with the config_submission.json configuration). To use it, just run the following in your terminal:
python trainer.py test --sessionId=banana_submissionThe weights of the trained agent are provided in the results/banana_submission folder, and are stored in the banana_submission_model_pytorch.pth file.
Also, you can check this video of a the pretrained agent collecting bananas.
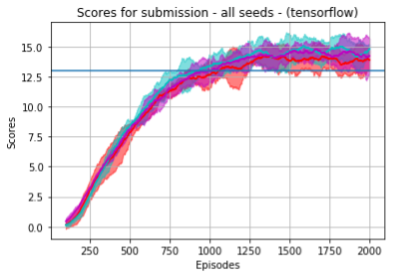
- Single runs: We choose one of the results of the various runs, plotted as time series plots. The x-axis represents episodes (during training) and the y-axis represents the score obtained at that episode. Also, the noisy blue plot is the actual score per episode, whereas the red curve is a smoothed (running average) curve from the previous one with a window of size 100. Below we show one random run from the episode (not cherry-picked) for both our pytorch and tensorflow implementations. As we can see, the agent successfully solves the environment at around episode 900. Note that this submission configuration is not the best configuration (hyperparameters tuned to squeeze the most score out of the environment), but a configuration we considered appropriate (moderate exploration). We found that for more aggressive exploration schedules (fast decay over around 300 episodes) and a moderate sized replay buffer the task could be solved in around 300 steps (see experiment 1 later).
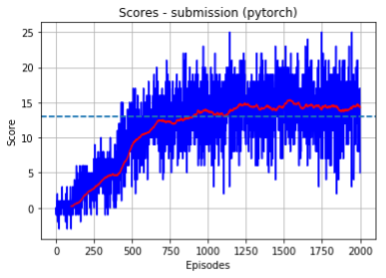
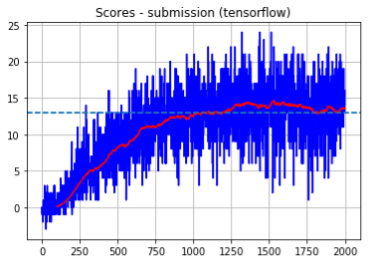
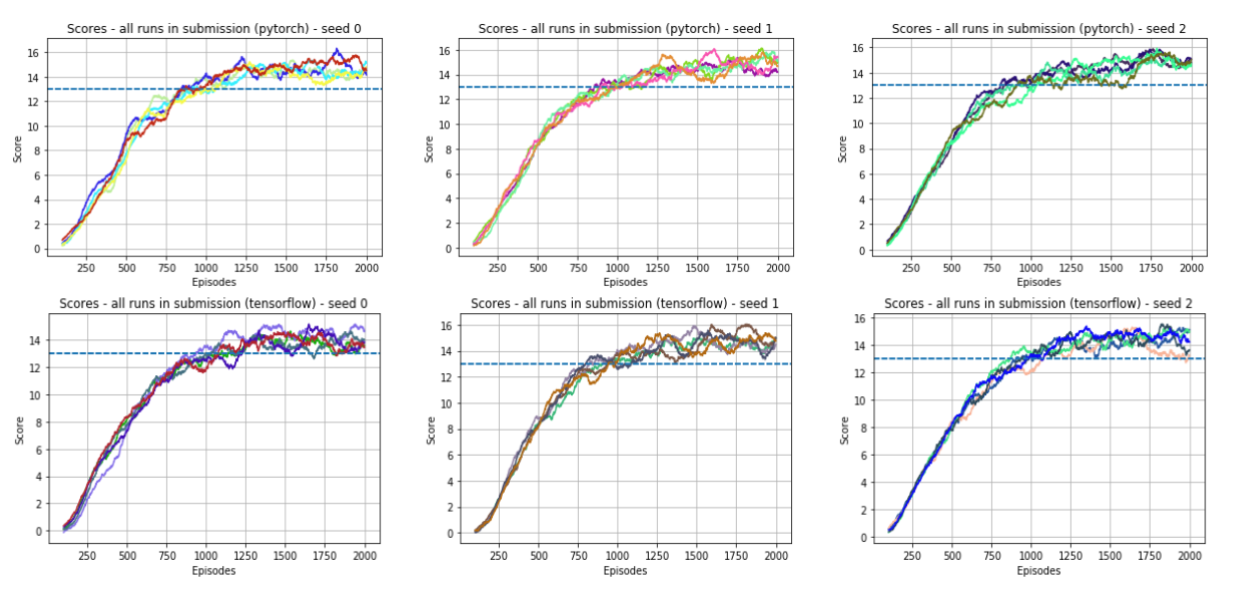
- All runs: Below we shows graphs of all runs in a single plot for three different random seeds. We again present one graph for each backend (pytorch and tensorflow). We recorded 5 training runs per seed. Recall again that all runs correspond to the same set of hyperparameters given by the config_submission.json file.
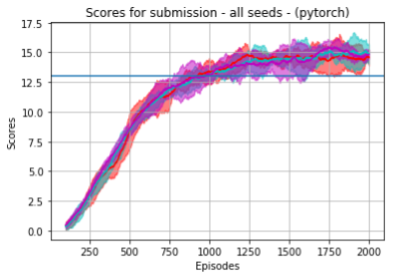
- Std-plots: Finally, we show the previous plots in the form of std-plots, which try to give a sense of the deviation of the various runs. We collected 5 runs per seed, and each std-plot is given for a specific seed. Recall again that all runs correspond to the same set of hyperparameters given by the config_submission.json file.
In this section we show some preleminary results obtained with the improvements. These results come from the following two extra experiments, which we made in order to evaluate if PER and DDQN helped during training:
- Experiment 1 : Test exploration schedules, comparing the use of moderate exploration v.s. the use of little exploration.
- Experiment 2 : Test vanilla DQN against each of the improvements (DDQN only, PER only and DDQN + PER).
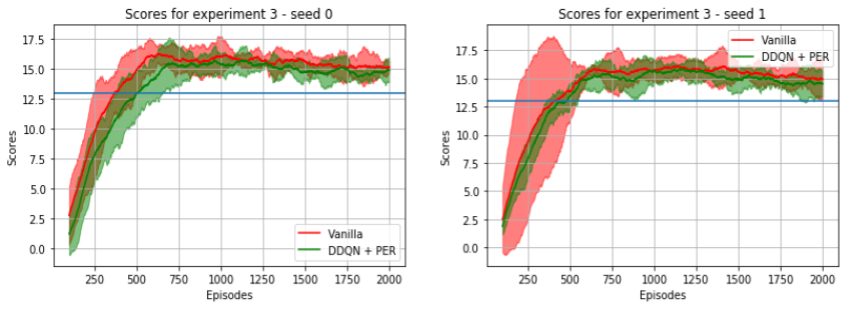
- Experiment 3 : Test if DDQN + PER help in situations with too little exploration. Our hypothesis was that too little exploration might run into unstable learning, and DDQN + PER could help stabilize this process (or even help solve it if the agent couldn't solve the task using only the baseline).
Note: the hyperparameters related to PER were not exposed through the .json file (sorry,I will fix it in later tests), but instead hard-coded in the priority-buffer implementation (see the prioritybuffer.py file). These parameters were set to the following default values:
eps : 0.01 # small value added to the absolute value of the bellman error
alpha : 0.6 # power to raise the priority in order to further control it
beta : 0.4 # importance sampling annealed factor
dbeta : 0.00001 # linear increment per sample added to the "beta" parameter
Spoiler alert: we did not find much improvement in the task at hand by using PER and DDQN. However, these results are preliminary as we did not tune the hyperparameters of PER (nor the other hyperparameters), and we still haven't made test cases for all details of the implementations of the algorithm. We tested each separate component of the improvements (extra data structures, consistency with other sources' implementations, etc.), but still we could have miss some detail in the implementation. Also, perhaps the structure of the task at hand is not too complicated for our vanilla DQN to require these improvements. We plan to make further tests and experiments in this and more complicated environments (visual banana environment, atari, etc.) to see if our improvements actually work and help during training.
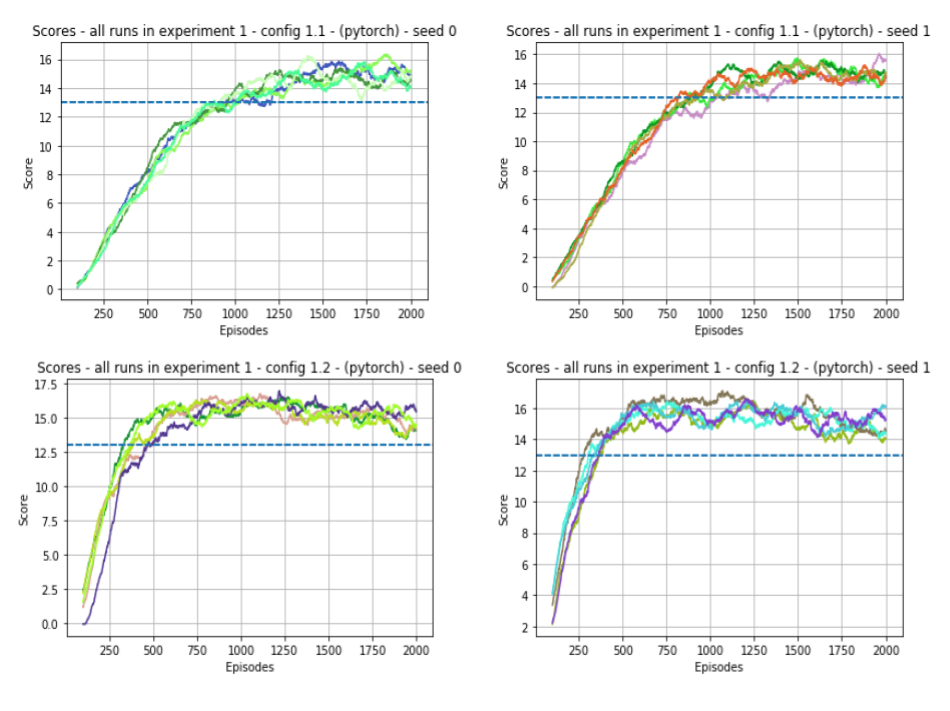
In this experiment we tried to double-check if decreasing the amount of exploration would allow the agent to solve the task in fewer episodes. Because the amount of exploration is small, the agent would be forced to start trusting more its own estimates early on and, if the setup is right (big enough replay buffer, etc.), this might have the effect of making the agent solve the task quickly. The configurations used are the following:
-
config_agent_1_1.json : This configuration has a moderate exploration schedule. We decay epsilon from 1.0 to 0.01 using a multiplicative decay factor of 0.9975 applied per episode. This schedule makes epsilon decay from 1.0 to approx. 0.1 over 1000 episodes, and to the final value of 0.01 over approx. 1600 episodes.
-
config_agent_1_2.json : This configuration has a little more aggresive exploration schedule. We decay epsilon from 1.0 to 0.01 using a multiplicative decay factor of 0.98 applied per episode. This schedule makes epsilon decay from 1.0 to approx. 0.1 over 100 episodes, and to the final value of 0.01 over approx. 200 episodes.
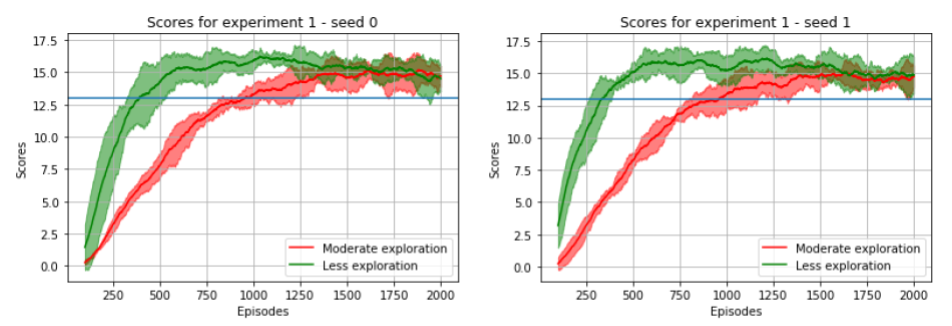
Below we show the training results from 5 runs over 2 random seeds using these configurations. These plots reveal a trend which suggests that with the second configuration (less exploration) we get to solve the task faster (around 400 episodes) than the first configuration (around 900 episodes).
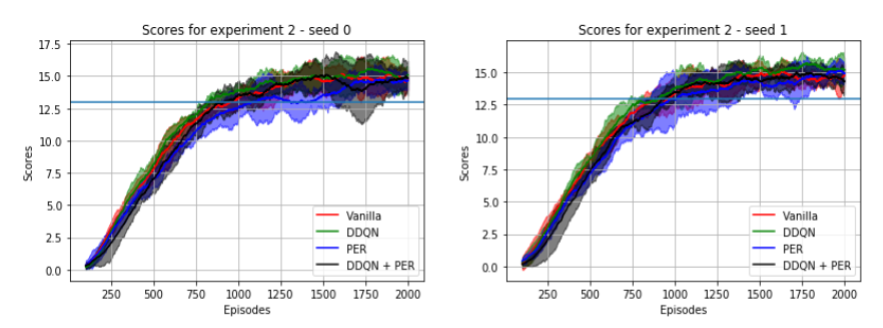
This experiment consisted of testing what improvements do DDQN and PER offer to our vanilla DQN implementation. The configurations for these can be found in the following files:
- config_agent_2_1.json : Configuration with only DDQN active.
- config_agent_2_2.json : Configuration with only PER active.
- config_agent_2_3.json : Configuration with DDQN + PER active.
- config_agent_1_1.json : The baseline, with the same hyperparameters as the ones above.
We used 5 runs and 2 different seeds for each configuration of the experiment. The preliminary results (shown below) look very similar for all configurations, and we can't conclude if there is any improvement using the variations to vanilla DQN.
This experiment consisted on testing if DDQN + PER would help in situations where there is too little exploration. The configurations used for these experiment can be found in the following files:
- config_agent_3_1.json : Configuration without DDQN nor PER.
- config_agent_3_2.json : Configuration with DDQN + PER active.
The exploration schedule was such that in just 60 episodes we would have reached the fixed 0.01 minimum value for epsilon, and have just 18000 experience tuples in a buffer of size of 131072, which consisted just of a approx. 13% of the replay buffer size. All other interactions would add only experience tuples taken from a practically greedy policy. Also, after just 510 episodes, the replay buffer would have just experience tuples sampled from a greedy policy.
We considered that this case would require clever use of the data (PER) to squeeze the most out of the experiences in the replay buffer, and also to not to overestimate the q-values, as we would be following a pure greedy policy after just some steps. The preliminary results don't show much evidence of improvement, except in a run with a different seed, in which the learning curves were less jumpy, indicating more stable learning. The results are shown in the image below, which were created using 5 runs with 2 seeds for both configurations.
Finally, below we mention some of the improvements we consider making in following updates to this post:
-
Make more tests of the improvements implemented, namely DDQN and PER, as we did not see much improvement in the given task. We could run the implementation in different environments from gym and atari, make "unit tests" for parts of the implementation, and tune the hyperparameters (PER) to see if there are any improvements.
-
Get the visual-based agent working for the banana environment. We had various issues with the executable provided, namely memory leaks of the executable that used up all memory in my machine. I first thought they were issues with the replay buffer being to big (as the experiences now stored images), but after some debugging that consisted on checking the system-monitor and even only testing the bare unity environment in the most simple setting possible, i.e. just instantiating it and running a random policy in a very simple script, we still got leaks that did not let us fully test our implementation. I was considering sending a PR, but the leaks only occur using the old ml-agent API (called unityagents, which is version 0.4.0). We made a custom build in the latest version of unity ml-agents and the unity editor, and got it working without leaks, but still could not get the agent to learn, which might be caused by our DQN agent implementation, our model, or the custom build we made.
-
Finish the implementation of a generic model for tensorflow and pytorch (see the incomplete implementations in the model_pytorch.py and model_tensorflow.py files), in order to be able to just send a configuration easily via a .json file or similar, and instantiate the requested model without having to write any pytorch nor tensorflow specific model by ourselves.
-
Implement the remaining improvements from rainbow, namely Dueling DQN, Noisy DQN, A3C, Distributional DQN, and try to reproduce a similar ablation test in benchmarks like gym and ml-agents.
-
Implement recurent versions of DQN and test the implementation in various environments.
- [1] Sutton, Richard & Barto, Andrew. Reinforcement Learning: An introduction.
- [2] Mnih, Volodymyr & Kavukcuoglu, Koray & Silver, David, et. al.. Human-level control through deep-reinforcement learning
- [3] Achiam, Josh. Spinning Up in Deep RL
- [4] Simonini, Thomas. A Free course in Deep Reinforcement Learning from beginner to expert
- [5] Stanford RL course by Emma Brunskill
- [6] UCL RL course, by David Silver
- [7] UC Berkeley DeepRL course by Sergey Levine
- [8] Udacity DeepRL Nanodegree
- [9] DeepRL bootcamp
- [10] Van Hasselt, Hado. Double Q-learning
- [11] Van Hasselt, Hado & Guez, Arthur & Silver, David. Deep Reinforccement Learning with Double Q-learning
- [12] Schaul, Tom & Quan, John & Antonoglou, Ioannis & Silver, David. Prioritized Experience Replay
- [13] Hacker Earth. Segment Trees data structures
- [14] OpenAI. Baselines
- [15] Hessel, Matteo & Modayil, Joseph & van Hasselt, Hado & Schaul, Tom & Ostrovski, Georg & Dabney, Will & Horgan, Dan & Piot, Bilal & Azar, Mohammad & Silver, David Rainbow
- [16] Hausknecht, Matthew & Stone, Peter Deep Recurrent Q-Learning with Partially Observable MDPs