ICNet for Real-time Semantic Segmentation on High-resolution Images
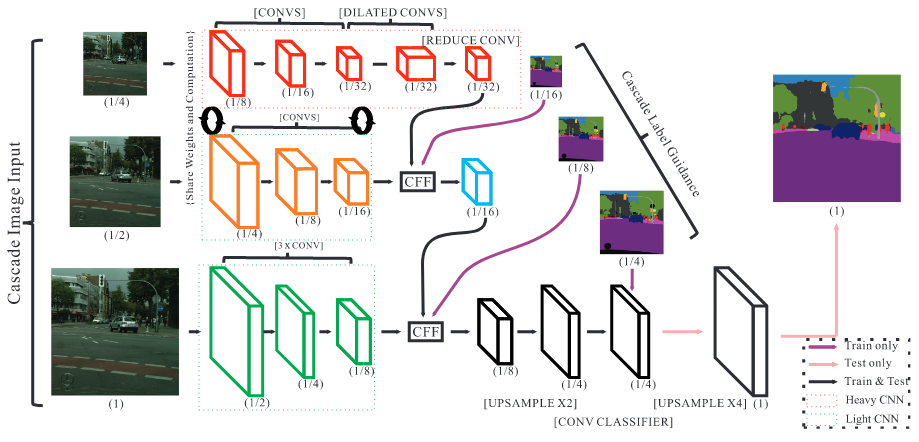
We focus on the challenging task of real-time semantic segmentation in this paper. It finds many practical applications and yet is with fundamental difficulty of reducing a large portion of computation for pixel-wise label inference. We propose an image cascade network (ICNet) that incorporates multi-resolution branches under proper label guidance to address this challenge. We provide in-depth analysis of our framework and introduce the cascade feature fusion unit to quickly achieve high-quality segmentation. Our system yields real-time inference on a single GPU card with decent quality results evaluated on challenging datasets like Cityscapes, CamVid and COCO-Stuff.
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | Device | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|---|
| ICNet | R-18-D8 | 832x832 | 80000 | 1.70 | 27.12 | V100 | 68.14 | 70.16 | config | model | log |
| ICNet | R-18-D8 | 832x832 | 160000 | - | - | V100 | 71.64 | 74.18 | config | model | log |
| ICNet (in1k-pre) | R-18-D8 | 832x832 | 80000 | - | - | V100 | 72.51 | 74.78 | config | model | log |
| ICNet (in1k-pre) | R-18-D8 | 832x832 | 160000 | - | - | V100 | 74.43 | 76.72 | config | model | log |
| ICNet | R-50-D8 | 832x832 | 80000 | 2.53 | 20.08 | V100 | 68.91 | 69.72 | config | model | log |
| ICNet | R-50-D8 | 832x832 | 160000 | - | - | V100 | 73.82 | 75.67 | config | model | log |
| ICNet (in1k-pre) | R-50-D8 | 832x832 | 80000 | - | - | V100 | 74.58 | 76.41 | config | model | log |
| ICNet (in1k-pre) | R-50-D8 | 832x832 | 160000 | - | - | V100 | 76.29 | 78.09 | config | model | log |
| ICNet | R-101-D8 | 832x832 | 80000 | 3.08 | 16.95 | V100 | 70.28 | 71.95 | config | model | log |
| ICNet | R-101-D8 | 832x832 | 160000 | - | - | V100 | 73.80 | 76.10 | config | model | log |
| ICNet (in1k-pre) | R-101-D8 | 832x832 | 80000 | - | - | V100 | 75.57 | 77.86 | config | model | log |
| ICNet (in1k-pre) | R-101-D8 | 832x832 | 160000 | - | - | V100 | 76.15 | 77.98 | config | model | log |
Note: in1k-pre means pretrained model is used.
@inproceedings{zhao2018icnet,
title={Icnet for real-time semantic segmentation on high-resolution images},
author={Zhao, Hengshuang and Qi, Xiaojuan and Shen, Xiaoyong and Shi, Jianping and Jia, Jiaya},
booktitle={Proceedings of the European conference on computer vision (ECCV)},
pages={405--420},
year={2018}
}