本文是关于 WebAssembly 系列的第五篇文章。如果你没有读先前文章的话,建议从头开始。
上一篇文章中,我介绍了编写程序时不用在 WebAssembly 和 javascript 里二者选其一啦,也表达了我希望看到更多的开发者在自己的工程中同时使用 WebAssembly 和 JavaScript 的期许。
开发者们不必纠结于在自己的应用中到底选择 WebAssembly 还是 JavaScript。但是我们确实希望开发者们,希望能把部分 JavaScript 替换成 WebAssembly 来尝试使用
例如,正在开发 React 程序的团队可以把调节器代码(即虚拟 DOM)替换成 WebAssembly 的版本。而对于你的 web 应用的用户来说,他们就跟以前一样使用,不会发生任何变化,同时他们还能享受到 WebAssembly 所带来的好处。
而像 React 团队这样的开发者选择替换为 WebAssembly 的原因正是因为 WebAssembly 比较快。那么为什么它执行的快呢?
在我们了解 JavaScript 和 WebAssembly 的性能区别之前,需要先理解 JS 引擎的工作原理。
该图给出了现在一个应用程序的启动性的大致情况。
**JS 引擎在图中各个部分所花的时间取决于页面所用的 JavaScript 代码。图表中的比例并不代表真实情况下的确切比例情况。相反,它意味着提供一个高级模型,来说明在 JS 和 WebAssembly 中相同功能的性能如何不同。 **
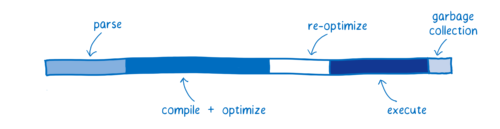
图中的每一个颜色条都代表了不同的任务:
- Parsing —— 表示把源代码变成解释器可以运行的代码所花的时间;
- Compiling + optimizing —— 表示基线编译器和优化编译器花的时间。一些优化编译器的工作并不在主线程运行,所以也不包含在这里。
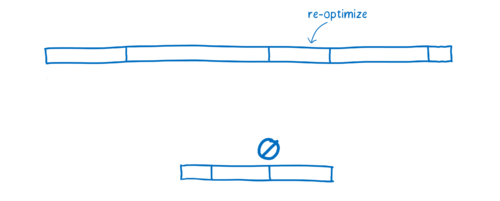
- Re-optimizing —— 当 JIT 发现优化假设错误,丢弃优化代码所花的时间。包括重优化的时间、抛弃并返回到基线编译器的时间。
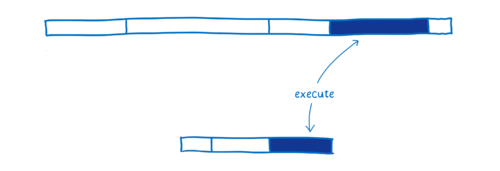
- Execution —— 执行代码的时间
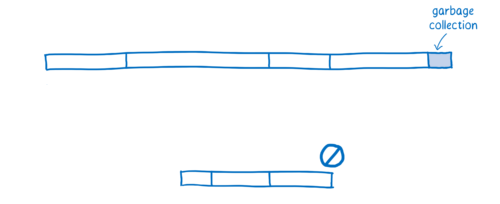
- Garbage collection —— 清理内存的时间
这里注意:这些任务并不是离散执行的,或者按固定顺序依次执行的。而是交叉执行,比如正在进行解析过程时,其他一些代码正在运行,而另一些正在编译。
这样的交叉执行给早期 JavaScript 带来了很大的效率提升,早期的 JavaScript 执行类似于下图:

早期时,JavaScript 只有解释器,执行起来非常慢。当引入了 JIT 后,大大提升了执行效率,缩短了执行时间。
JIT 所付出的开销是对代码的监视和编译时间。如果 JavaScript 开发者依旧像以前那样开发 JavaScript 程序,解析和编译的时间也大大缩短。这就使得开发者们更加倾向于开发更复杂的 JavaScript 应用。
同时,这也说明了执行效率上还有很大的提升空间。
下图是 WebAssembly 和典型的 web 应用的对比的初略估计
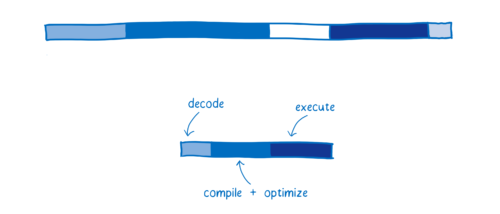
各种浏览器处理上图中不同的过程,有着细微的差别,我用 SpiderMonkey 作为模型来讲解不同的阶段:
这一步并没有显示在图表中,但是这看似简单地从服务器获取文件这个步骤,却会花费很长时间。
WebAssembly 比 JavaScript 的压缩率更高,所以文件获取也更快。即便通过压缩算法可以显著地减小 JavaScript 的包大小,但是压缩后的 WebAssembly 的二进制代码依然更小。
这就是说在服务器和客户端之间传输文件更快,尤其在网络不好的情况下。
一旦到达浏览器,JavaScript 源代码就被解析成了抽象语法树。
浏览器采用懒加载的方式进行,一开始只解析真正需要的部分,而对于浏览器暂时不需要的函数只保留它的桩。
解析过后 AST (抽象语法树)就变成了中间代码(叫做字节码),提供给 JS 引擎编译。
而 WebAssembly 则不需要这种转换,因为它本身就是中间代码。它要做的只是解码并且检查确认代码没有错误就可以了。
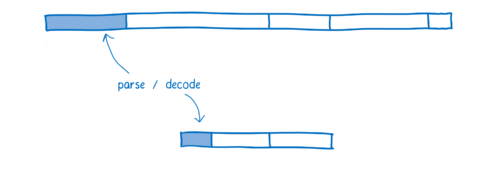
上一篇关于 JIT 的文章中,我有介绍过,JavaScript 是在代码的执行阶段编译的。因为它是弱类型语言,当变量类型发生变化时,同样的代码会被编译成不同版本。
不同浏览器处理 WebAssembly 的编译过程也不同,有些浏览器只对 WebAssembly 做基线编译,而另一些浏览器用 JIT 来编译。
不论哪种方式,WebAssembly 都更贴近机器码。例如:类型是程序的一部分。使它更快的原因有以下几个:
- 在编译优化代码之前,它不需要提前运行代码以知道变量都是什么类型。
- 编译器不需要对同样的代码做不同版本的编译。
- 很多优化在 LLVM 阶段就已经做完了,所以在编译和优化的时候没有太多的优化需要做。
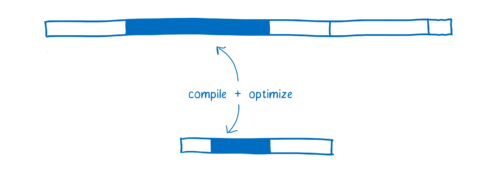
有些情况下,JIT 不得不抛弃已有的优化,重新去尝试执行。
当 JIT 在优化假设阶段做的假设,执行阶段发现是不正确的时候,就会发生这种情况。比如当循环中发现本次循环所使用的变量类型和上次循环的类型不一样,或者原型链中插入了新的函数,都会使 JIT 抛弃已优化的代码。
反优化过程有两部分开销。第一,需要花时间丢掉已优化的代码并且回到基线版本。第二,如果函数依旧频繁被调用,JIT 可能会再次把它发送到优化编译器,又做一次优化编译,因此存在第二次编译它的代价。
在 WebAssembly 中,类型都是确定了的,所以 JIT 不需要根据变量的类型做优化假设。也就是说 WebAssembly 没有重优化阶段。
自己也可以写出执行效率很高的 JavaScript 代码。你需要了解 JIT 的优化机制,例如你要知道什么样的代码编译器会对其进行特殊处理(JIT 文章里面有提到过)。
然而大多数的开发者是不知道 JIT 内部的实现机制的。即使开发者知道 JIT 的内部机制,也很难写出符合 JIT 标准的代码,因为人们通常为了代码可读性更好而使用的编码模式(例如将常见任务抽象为跨类型工作的函数),恰恰不合适编译器对代码的优化。
加之 JIT 会针对不同的浏览器做不同的优化,所以对于一个浏览器优化的比较好,很可能在另外一个浏览器上执行效率就比较差。
正是因为这样,执行 WebAssembly 通常会比较快,很多 JIT 为 JavaScript 所做的优化(例如类型专门化)在 WebAssembly 并不需要。
另外,WebAssembly 就是为了编译器而设计的,这意味着它被设计用于编译器生成,而不是为了人类程序员编写它。
由于人类程序员不需要直接编程它,这样就使得 WebAssembly 专注于提供更加理想的指令(执行效率更高的指令)给机器就好了。执行效率方面,不同的代码功能有不同的效果,一般来讲执行效率会提高 10% - 800%。
JavaScript 中,开发者不需要手动清理内存中不用的变量。JS 引擎会自动地做这件事情,这个过程叫做垃圾回收。
可是,当你想要实现性能可控,垃圾回收可能就是个问题了。垃圾回收器会自动开始,这是不受你控制的,所以很有可能它会在一个不合适的时机启动。目前的大多数浏览器已经能给垃圾回收安排一个合理的启动时间,不过这还是会增加代码执行的开销。
目前为止,WebAssembly 不支持垃圾回收。内存操作都是手动控制的(像 C、C++ 一样)。这对于开发者来讲确实增加了些开发成本,不过这也使代码的执行效率更高。
WebAssembly 比 JavaScript 执行更快是因为:
- 文件抓取阶段,WebAssembly 比 JavaScript 抓取文件更快。即使 JavaScript 进行了压缩,WebAssembly 文件的体积也比 JavaScript 更小;
- 解析阶段,WebAssembly 的解码时间比 JavaScript 的解析时间更短;
- 编译和优化阶段,WebAssembly 更具优势,因为 WebAssembly 的代码更接近机器码,并且它在服务器已经优化结束了。。
- 重优化阶段,WebAssembly 不会发生重优化现象。因为 WebAssembly 中类型和其他信息已经确定了,所以 JS 引擎不需要按照 javascript 的方式去优化。
- 执行阶段,WebAssembly 更快是因为开发人员不需要懂太多的编译器技巧,而这在 JavaScript 中是需要的。WebAssembly 代码也更适合生成机器执行效率更高的指令。
- 垃圾回收阶段,WebAssembly 垃圾回收都是手动控制的,效率比自动回收更高。
这就是为什么在大多数情况下,同一个任务 WebAssembly 比 JavaScript 表现更好的原因。
但是,还有一些情况 WebAssembly 表现的会不如预期;同时 WebAssembly 的未来也会朝着使 WebAssembly 执行效率更高的方向发展。这些我会在下一篇文章《WebAssembly 的现在与未来》中介绍。
欢迎大家关注我的专栏前端大哈,定期发布高质量前端文章。