文章来自于:https://github.com/xuanhao44/net-lab-2023
本实验主要关注的是 IP 数据包格式。详细见指导书。
要完成四个函数:ip_in()、checksum16()、ip_out()、ip_fragment_out()。
ip_in():处理一个收到的数据包checksum16():计算 16 位校验和ip_out():处理一个要发送的 ip 数据包ip_fragment_out():处理一个要发送的 ip 分片
在阅读指导书上的函数的流程之前先思考一下这些函数的大致功能,再去看流程:
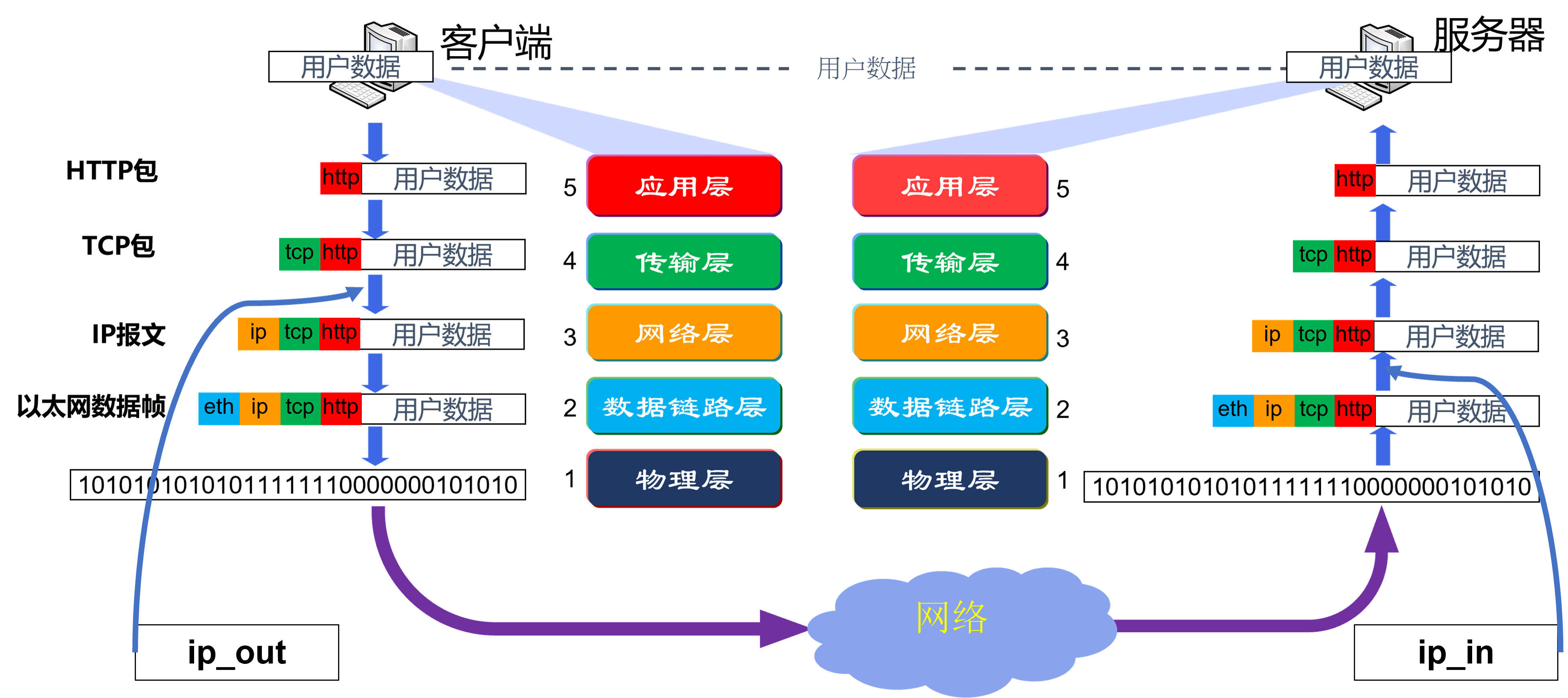
注意到关于 in 和 out,发现每次都需要辨认很久(别笑我),发现还是有点需要注意的。显然不管是封装还是解封装,网络层这块总是从一层拿到数据,给另一层发数据,所以单纯用 in (进) 和 out (出) 去理解函数是不太对的。ip_out() 就是指 IP 层 收到从 TCP 层来的包,处理后送到 MAC 层;ip_in() 就是指 IP 层收到从 MAC 层来的包,处理后送到 TCP 层。
ip_in():- 收到了哪里来的数据包?从数据链路层来的。发往哪里?发往传输层。
- 怎么处理?显然是解封装的过程,即拆掉网络层的报头(从 MAC 层来的是已经去掉 MAC 报头的数据包)。
- 流程中有哪些更多的内容:报头检测、IP 头部校检等等。
ip_out():- 这个要发送的数据包从哪里来?从传输层来。发往哪里去?发往数据链路层。
- 怎么处理:显然是需要封装上本层的 IP 报头的,但还需要注意的是需要将过大的数据包进行分片,所以可能会发出多个包。
- 流程中有哪些更多的内容:只有一些很常规的数据包长度检测等。
自己的流程,没有用指导书上的流程,因为太啰嗦了:
- 取出需要的数据。 取出来之后做一点基础的存储和转换大小端的工作。
- 常规检查,检查项目如下,如不满足则丢弃
- 数据包的长度应大于等于 IP 头部长度
- IP 头部的版本号为 IPv4
- 总长度字段小于或等于收到的包的长度
- 目的 IP 地址应为本机的 IP 地址
- 首部校验和再计算。
清除现有的 checksum,然后再用首部去计算新的 checksum 并比较,应相同,否则丢弃。
此外,下面是对 checksum 的一些补充说明。
- 去 padding。没什么好说的。
- 调用
net_in()函数向上层传递数据包。照着指导书做就行。指导书很差劲!具体步骤见代码。

和实验框架有关的点:
- 分片重组是附加题,所以本次实验
ip_in()暂不考虑重组的问题; - 必做任务只要求做到 UDP,TCP 不需要做,所以在做 IP/ICMP 自测时,当收到 TCP 报文可以当作不能处理,需回送一个 ICMP 协议不可达报文。但是当你已经做到 UDP/
TCP 以上协议,用另外一套自测环境,就不用再返回来做 IP/ICMP 自测。非常令人恼火的是,指导书没有指出回送 ICMP 协议不可达报文不应该去掉报头,这在做 ICMP 实验的时候产生了很大的误导!
需要注意的点:
-
数据包首部长度字段
hdr->hdr_len的单位是 4 字节,所以在表示数据包首部长度的时候需要写成:IP_HDR_LEN_PER_BYTE * hdr->hdr_len
其中常量来自于
include/ip.h。但上式太长,其实也可以用另外一种表示:sizeof(ip_hdr_t)。 -
checksum 的比较中不涉及大小端,不需要 swap。
流程:
- 把 data 看成是每 16 个 bit(即 2 个字节)组成一个数,相加(注意,16 位加法的结果可能会超过 16 位,因此加法结果需要用 32 位数来保存)。
- 如果最后还剩 8 个 bit 值,也要相加这个 8 bit 值。
- 判断相加后 32 bit 结果值的高 16 位是否为 0,如果不为 0,则将高 16 位和低 16 位相加,依次循环,直至高 16 位为 0 为止。
- 将上述的和(低 16 位)取反,即得到校验和。
相加的循环:len 的单位是字节(8 bit),而步进的单位是 16 bit,所以循环的时候 i 应该加 2。
for (int i = 0; i < len; i += 2)
{
res32 += data[i / 2];
}继续分析一个例子:假设一个首部长 25 字节,那么按照 2 字节一步的话,最后就留下了 1 字节,也就是 8 bit。我们关心的是加到第 25 个字节的情况。我们逐步分析:
i=0, +data[0], 对应第 0 和 1 字节
i=2, +data[1], 对应第 2 和 3 字节
i=4, +data[2], 对应第 4 和 5 字节
...
i=24, +data[12], 对应第 24 和 25 字节
显然我们注意到,25 字节长的首部是没有第 25 字节的。那么在 i = 24 的时候,就应该只加上第 24 字节,而不是 data[12]。
最后这个字节的表示方法为:
(uint8_t)data[len - 1]添加上 uint8_t 的显式转换即可取到第 len - 1 位字节,以可以得出 Step 2 的写法:
for (int i = 0; i < len; i += 2)
{
if (i == len - 1)
{
res32 += (uint8_t)data[len - 1];
}
res32 += data[i / 2];
}遗憾的是,IP 和 ICMP 的测试中不存在奇数字节的情况,但是 UDP 中有。所以在奇数的处理上,就算写错了也能过 IP 和 ICMP 实验,但在 UDP 实验中就会感受到 Debug 到最后结果发现问题出在 checksum16 上的痛苦了。
个人觉得应该先写 ip_out。
稍微修改了流程:
- IP 协议最大负载包长的计算:1500 字节(MTU)减去 IP 首部长度。
- 如果数据报包长超过 IP 协议最大负载包长,则需要分片发送。采用的方式是对数据包不断分片,每一片发出后就剔除掉已发出的部分。这样最后剩下的就是最后一片。
- 最后一个分片和小于最大负载包长的数据包的发送。能写在一起的原因是分片大小和片偏移的代码刚好能够复用。
- 最后记得标识 id 增 1。
和实验框架有关的点:
- IP 协议最大负载包长的计算:书上的写法还有除以 8 后向下取整,然后再乘以 8 的步骤。但在该实验中目前最大负载长就是 1500 - 20 = 1480,就是 8 的倍数,所以不这么写也不会出错。
- 不知道为什么
id在ip_fragment_out中的类型是int,很糟心,明明是uint16_t的。
需要注意的点:
用于承载分片数据的数据包不能用 buf_t 的指针,因为在我这种写法里一次循环的结尾就被 remove 掉了,所以需要直接用结构体。
buf_t ip_buf;流程:
- 调用
buf_add_header()增加 IP 数据报头部缓存空间。 - 填写 IP 数据报头部字段。
- 先把 IP 头部的首部校验和字段填 0,再调用
checksum16()函数计算校验和,然后把计算出来的校验和填入首部校验和字段。 - 调用
arp_out()函数将封装后的 IP 头部和数据发送出去。
难一点的是 flags_fragment16,毕竟是把标志与分段放在 16 bit 里一起处理了。
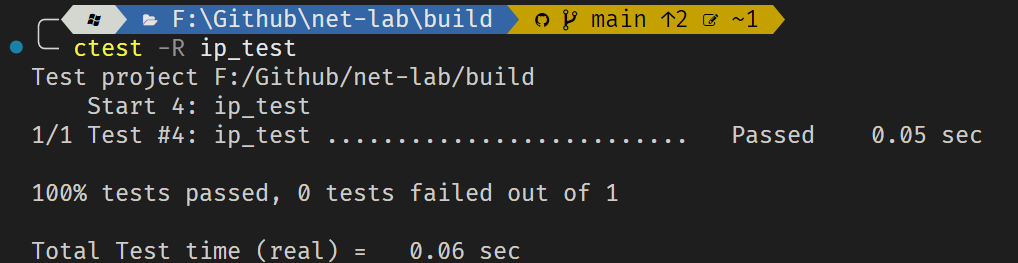
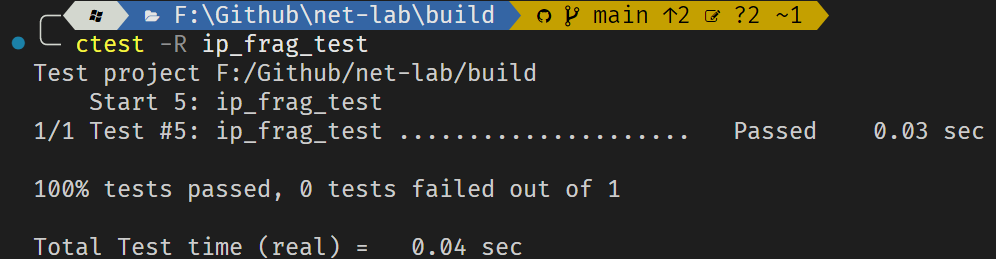
结果如下:
ip_test:
ip_frag_test:
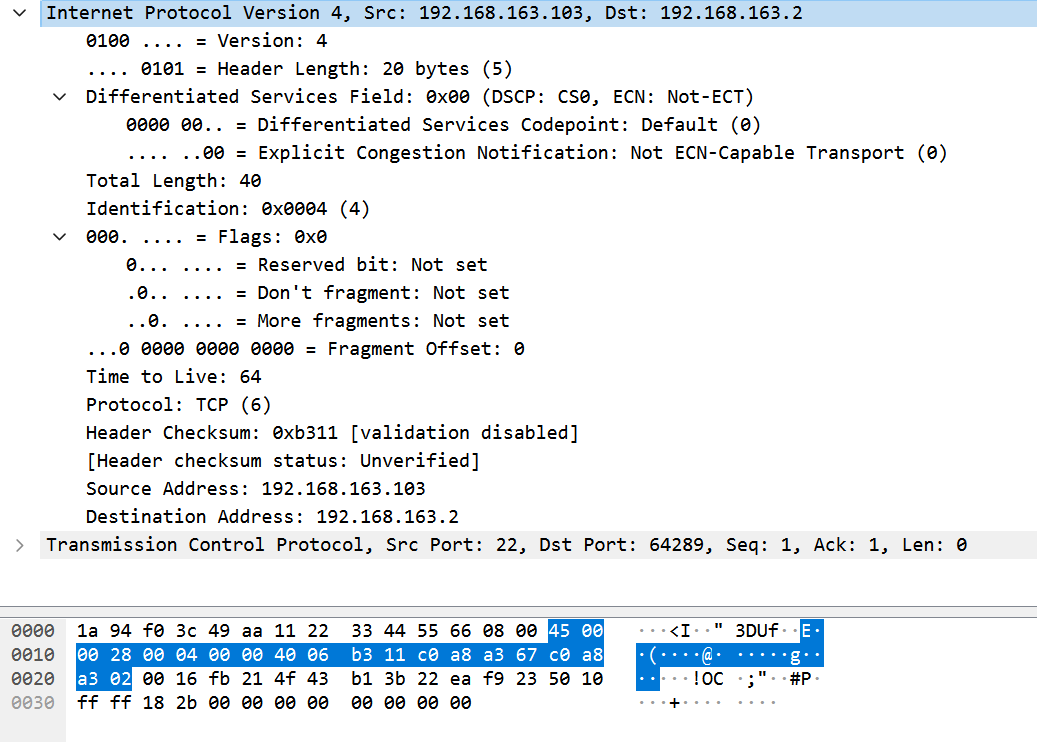
可以看到 IP 层的首部是 20 字节。
查看测试源码和数据知,就是使用 ip_out 发送了很长的一串文本(in.txt),然后用 demo_log 和输出 log 比对。
查看 demo_log 可知,就是进行了 4 次 arp_out,这就是 ip_fragment_out 的最后一步。
arp_out:
ip:192.168.163.103
buf: 45 00 05 dc 00 00 20 00 40 06 8c fc ...
arp_out:
ip:192.168.163.103
buf: 45 00 05 dc 00 00 20 b9 40 06 8c 43 ...
arp_out:
ip:192.168.163.103
buf: 45 00 05 dc 00 00 21 72 40 06 8b 8a ...
arp_out:
ip:192.168.163.103
buf: 45 00 02 6c 00 00 02 2b 40 06 ae 41 ...
写了一个很小的错误是:
while (buf->len > fragment_len)
{
buf_init(&ip_buf, fragment_len);
memcpy(ip_buf.data, buf->data, fragment_len);
ip_fragment_out(&ip_buf, ip, protocol, id, i * fragment_len, 1);
buf_remove_header(buf, fragment_len);
i++;
}这里我原先把 memcpy() 的第一项参数写成了 &ip_buf.data。导致我两个测试都是显示 SEGFAULT。
于是使用了指导书中介绍的调试的办法,就还算顺利的定位了问题。
为啥说还算顺利是因为调试的异常定位是在错误的地方停,报错的地方在 ip_fragment_out() 函数里,也就是要用到 ip_buf 的时候就报错了。我当时还百思不得其解,难道是 ip_fragment_out() 函数错了?但怎么想也觉得不太可能,最后检查了多遍后终于才找到问题根源了。
不过调试的过程确实很有趣,比如看下面这张图。
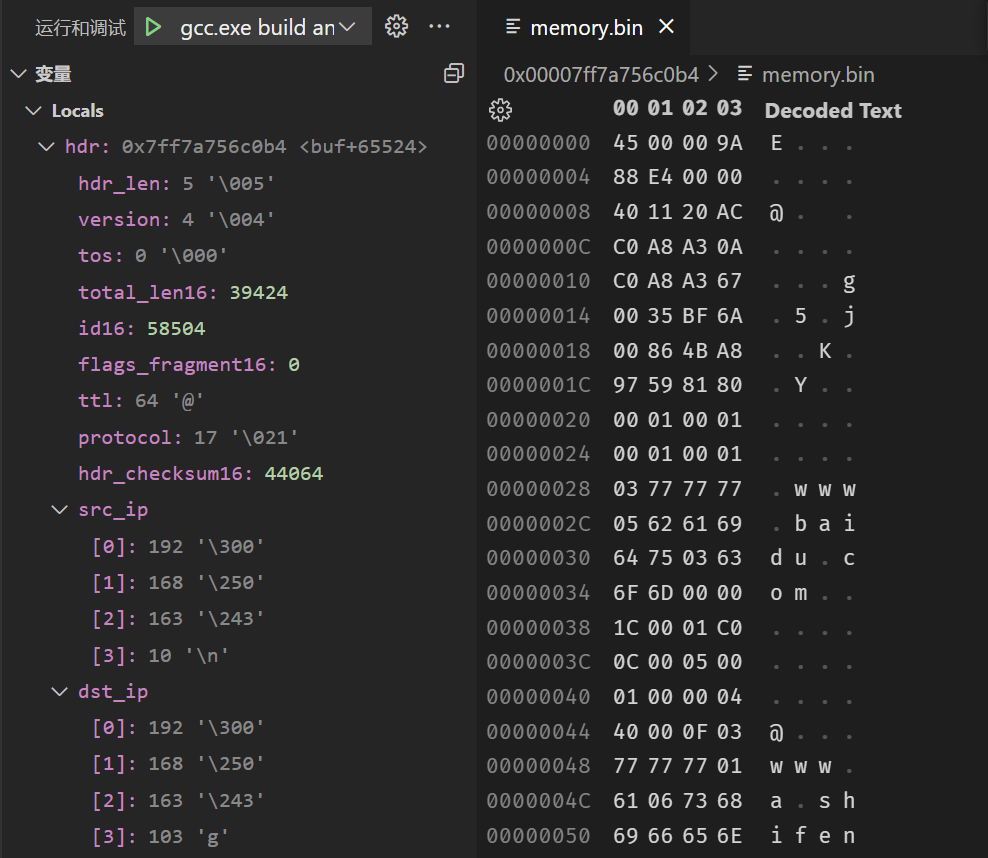
在调试的过程中看首部的各个字段,以及数值表示就能让我很清晰的把握这些数据的来龙去脉。
我在学 IP 这块的时候一直觉得那张 32 位一行的图示很奇怪,不知道为什么这么画——其实没什么意义,实际上数据包就是一串很长的字符串,图示不过是方便讲解所以 32 位一行的。
上面这张图中,我特意调整成了 4 字节一行,和图示的结构一样。但我自己心里明白这些数据是怎么排列的,调整成不管是 8 字节一行,16 字节一行都行。
- 指导书修订很不及时,让学生在做实验的时候遇到了很多不该浪费时间的地方,望及时改正!
- IP 的测试极不全面,很多地方的错误完全检查不出来,无法达到自测的目的。而许多错误到了 ICMP 实验中才能发现。