![]()
[Paper] [Download Dataset] [Dataset on Hugging Face] [Leaderboard] [Online Evaluator]
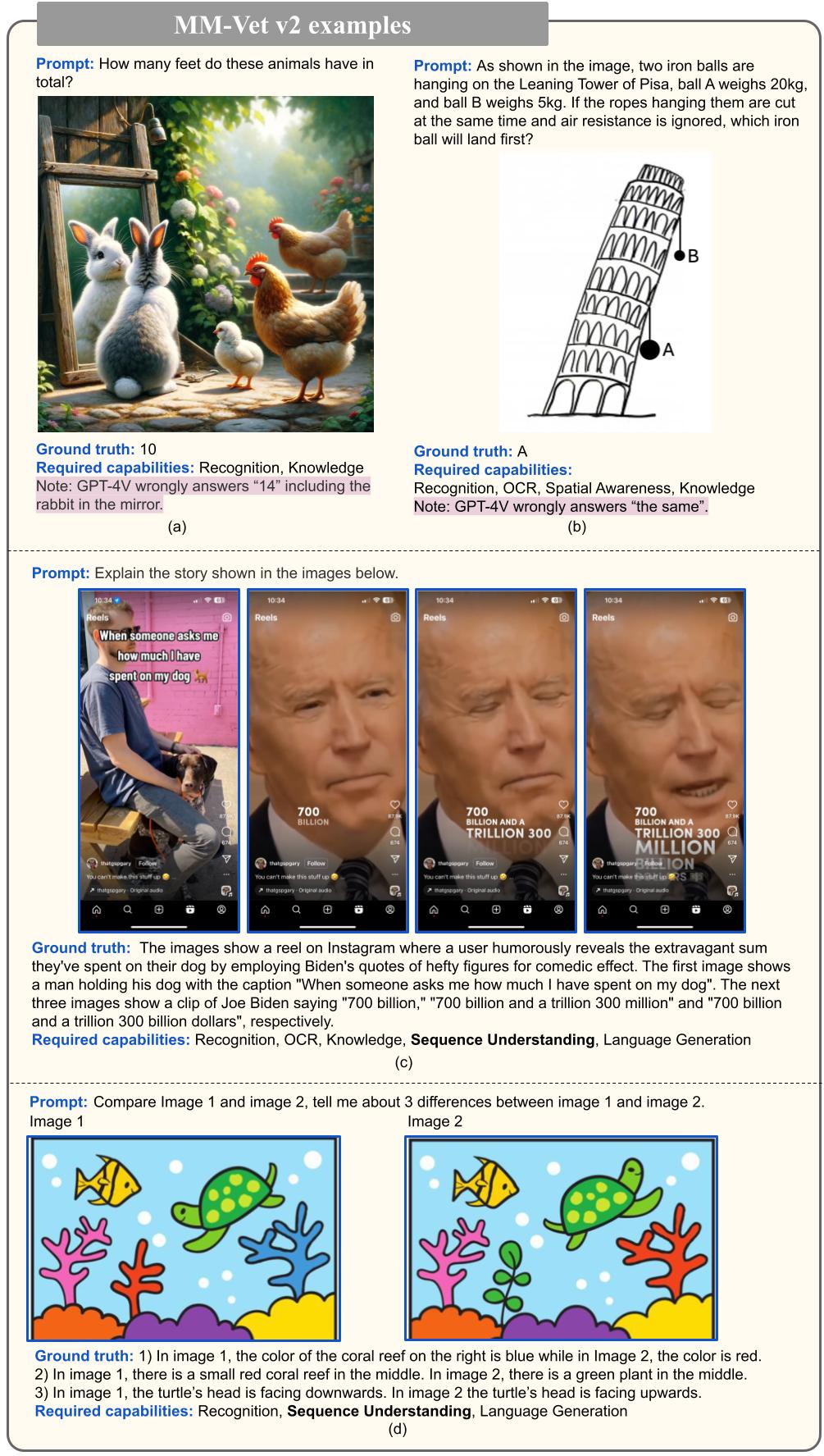 Figure 1: Four examples from MM-Vet v2. Compared with MM-Vet, MM-Vet v2 introduces more high-quality evaluation samples (e.g., (a) and (b)), and the ones with the new capability of image-text sequence understanding (e.g., (c) and (d)).
Figure 1: Four examples from MM-Vet v2. Compared with MM-Vet, MM-Vet v2 introduces more high-quality evaluation samples (e.g., (a) and (b)), and the ones with the new capability of image-text sequence understanding (e.g., (c) and (d)).
The code is under the Apache 2.0 license, and the dataset is under the CC BY-NC 4.0 license.
Step 0: Install openai package with pip install openai>=1 and get access GPT-4 API. If you have not access, you can try MM-Vet v2 online evaluator Hugging Face Space (but it may wait for long time depending on number of users).
Step 1: Download MM-Vet v2 data here and unzip unzip mm-vet-v2.zip.
Step 2: Infer your model on MM-Vet v2 and save your model outputs in json like gpt-4o-2024-05-13_detail-high.json, or just use gpt-4o-2024-05-13_detail-high.json as example to evaluate. We also release inference scripts for GPT-4, Claude and Gemini.
image_detail=high # or auto, low refer to https://platform.openai.com/docs/guides/vision/low-or-high-fidelity-image-understanding
python inference/gpt4.py --mmvetv2_path /path/to/mm-vet-v2 --model_name gpt-4o-2024-05-13 --image_detail ${image_detail}python inference/claude.py --mmvetv2_path /path/to/mm-vet-v2 --model_name claude-3-5-sonnet-20240620python inference/gemini.py --mmvetv2_path /path/to/mm-vet-v2 --model_name gemini-1.5-proStep 3: git clone https://github.com/yuweihao/MM-Vet.git && cd MM-Vet/v2, run LLM-based evaluator
python mm-vet-v2_evaluator.py --mmvetv2_path /path/to/mm-vet-v2 --result_file results/gpt-4o-2024-05-13_detail-high.jsonIf you cannot access GPT-4 (gpt-4-0613), you can upload your model output results (json file) to MM-Vet v2 online evaluator Hugging Face Space to get the grading results.
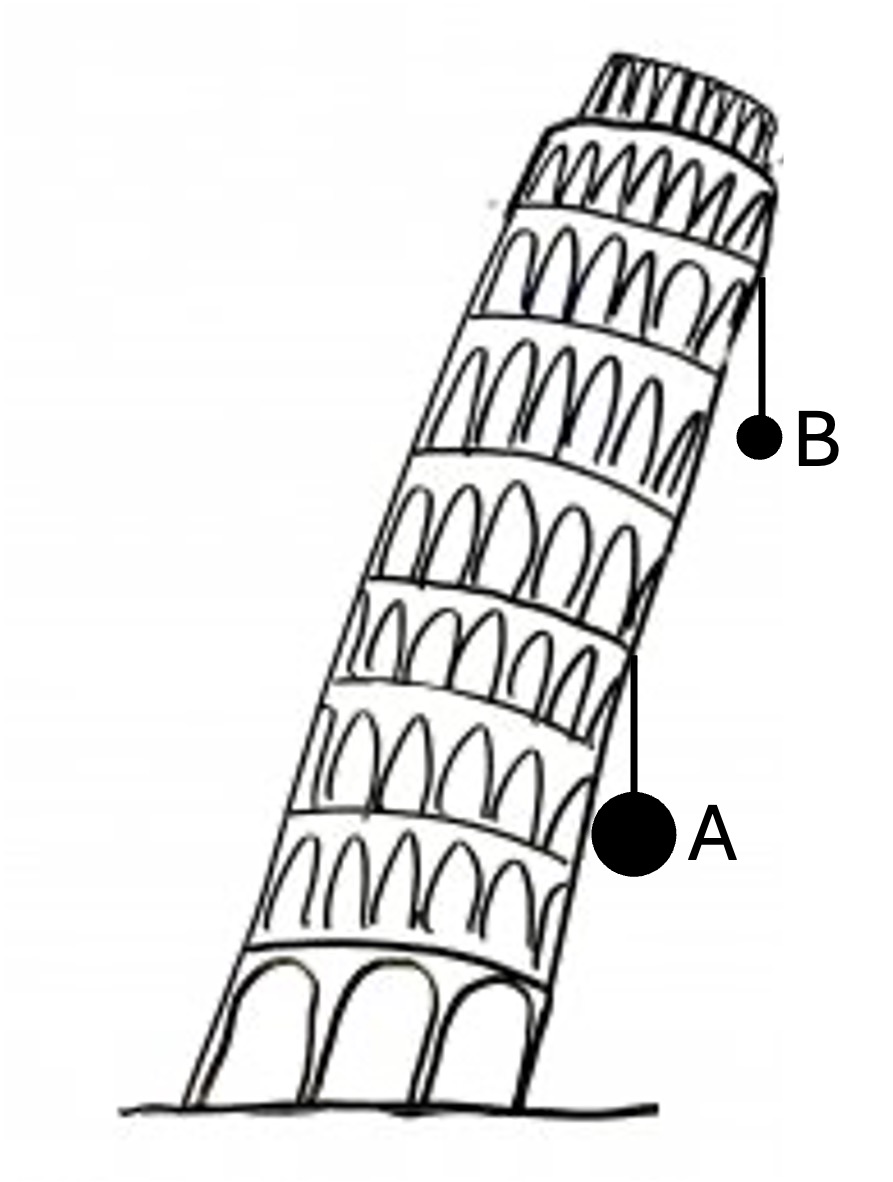
Q: As shown in the image, two iron balls are hanging on the Leaning Tower of Pisa, ball A weighs 20kg, and ball B weighs 5kg. If the ropes hanging them are cut at the same time and air resistance is ignored, which iron ball will land first?
GT: A
Required capabilities: Recognition, OCR, spatial awareness, knowledge

Q: How many feet do these animals have in total?
GT: 10
Required capabilities: Recognition, knowledge, math

Q: How many feet do these animals have in total?
GT: 16
Required capabilities: Recognition, knowledge, math
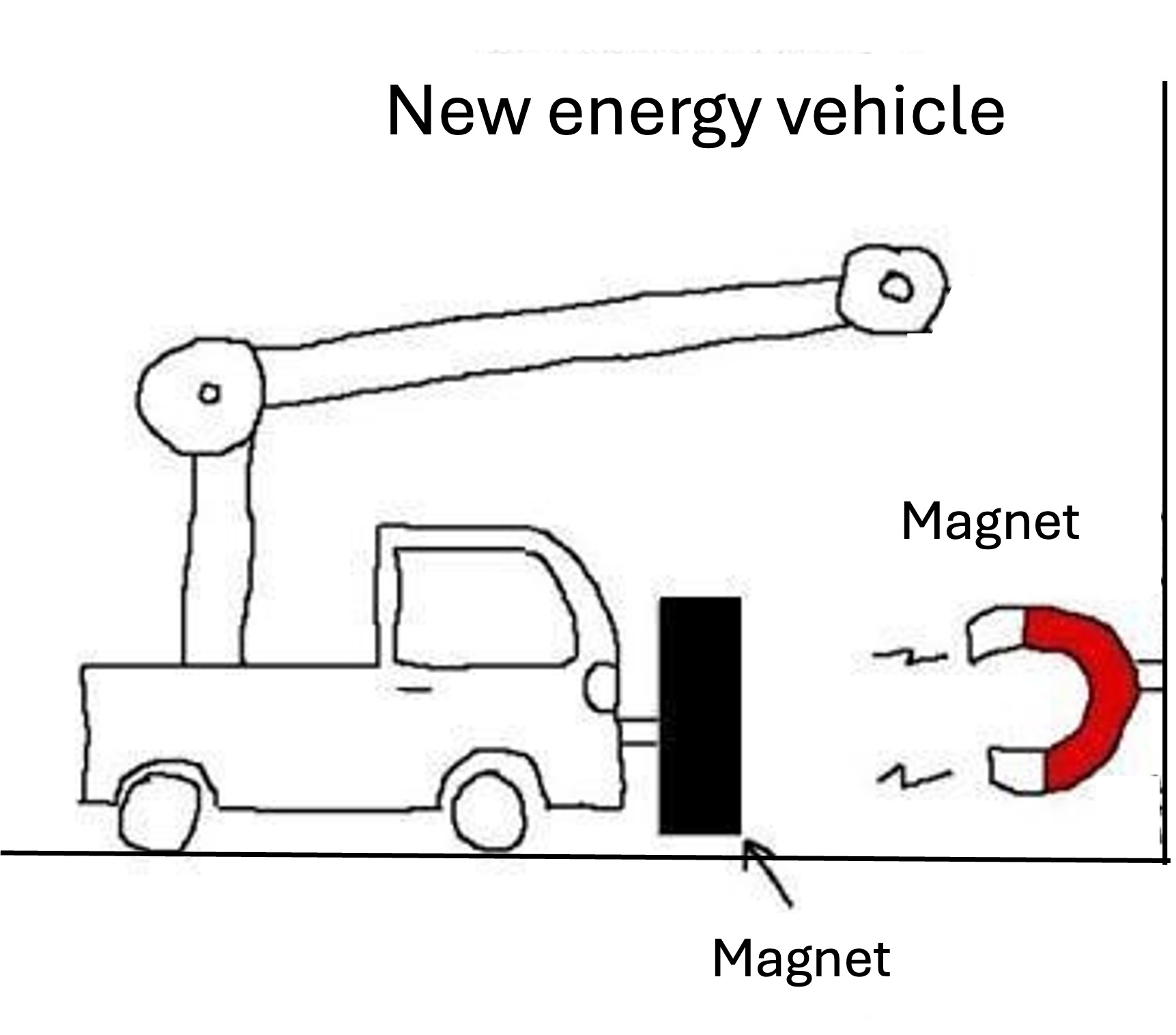
Q: Is it possible for the car to move with magnetic force according to the Physical laws?
GT: yes
Required capabilities: Recognition, OCR, spatial awareness, knowledge
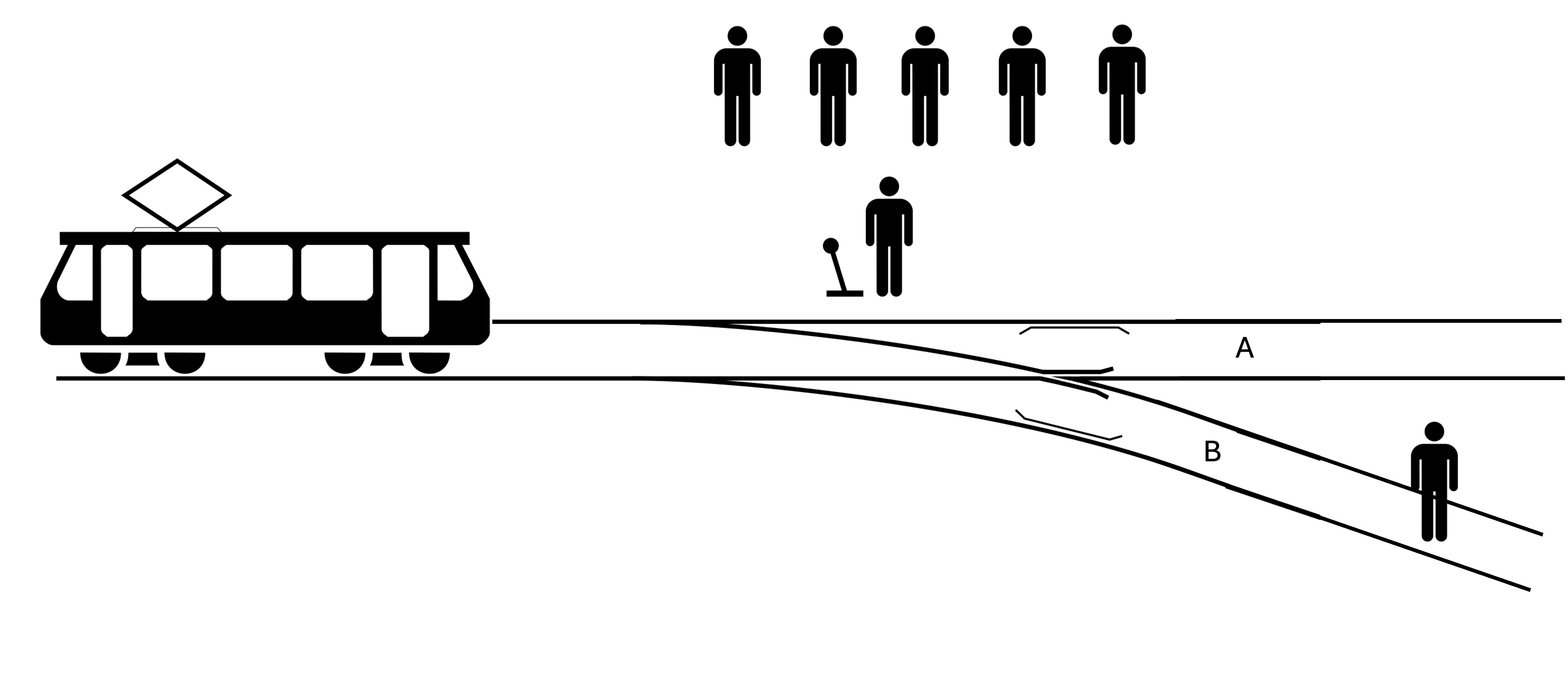
Q: Which track should the trolley go on, A or B?
GT: A
Required capabilities: Recognition, spatial awareness
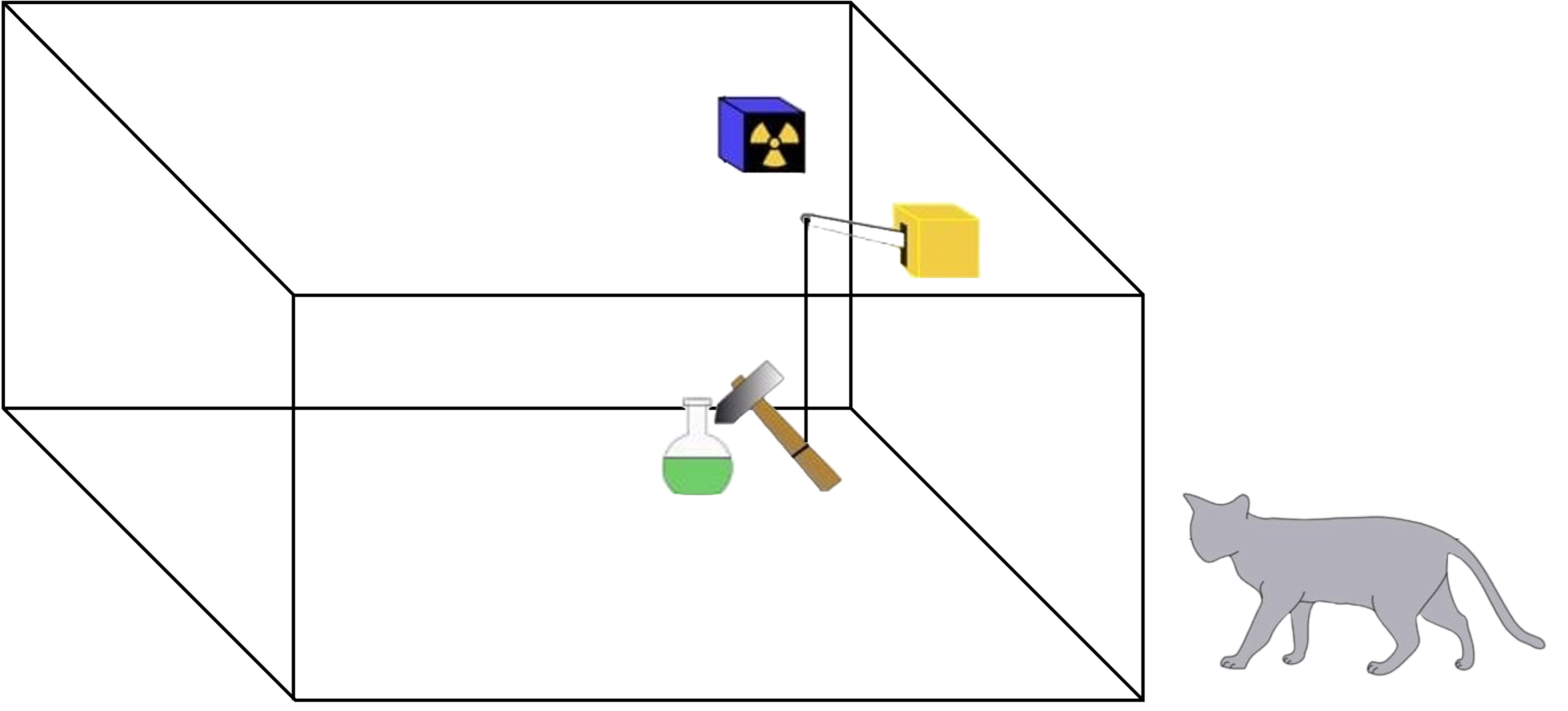
Q: Can we make sure the cat is alive before we open the box?
GT: yes
Required capabilities: Recognition, spatial awareness, knowledge
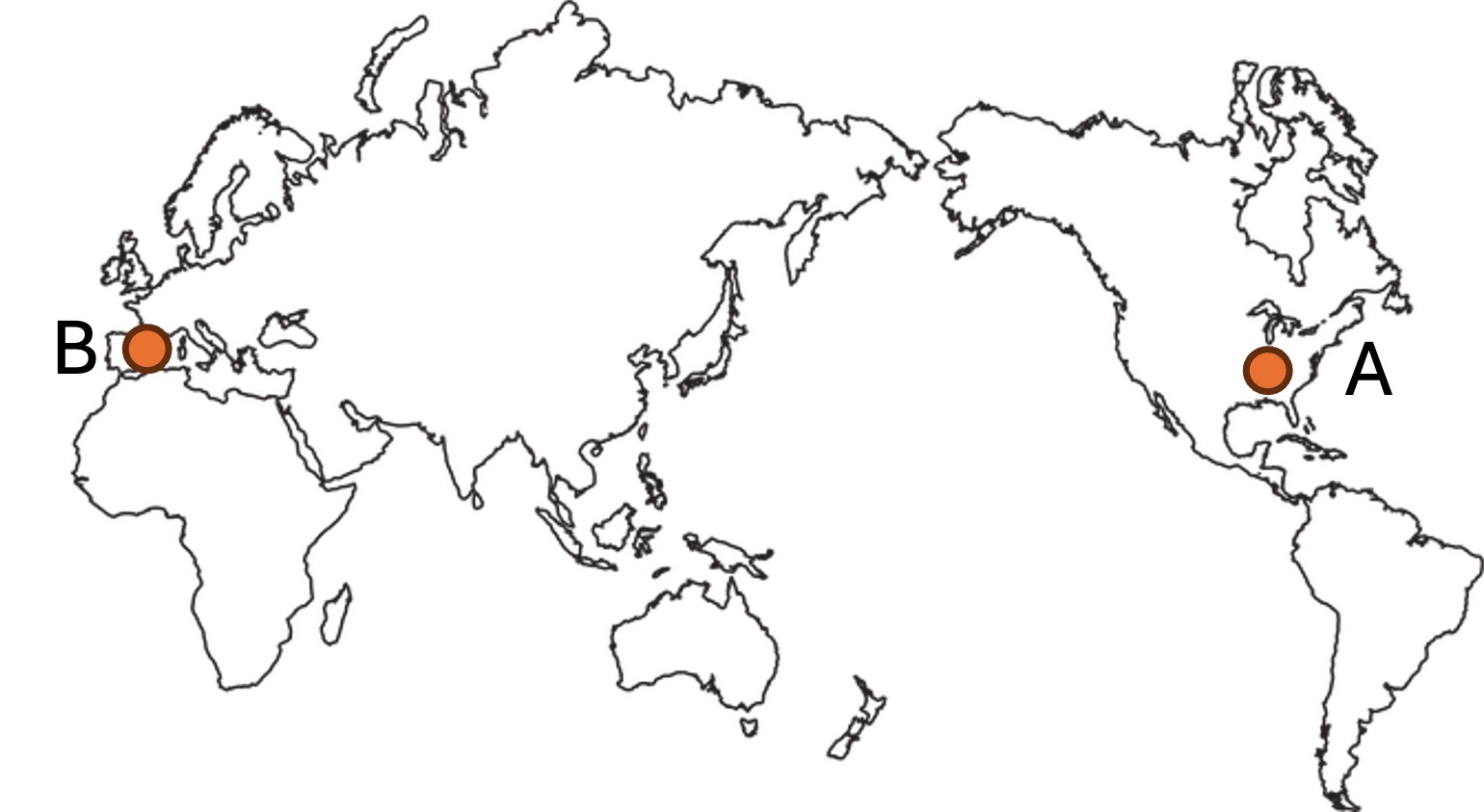
Q: From location A to location B, is it faster to go east or west?
GT: east
Required capabilities: Recognition, spatial awareness, knowledge
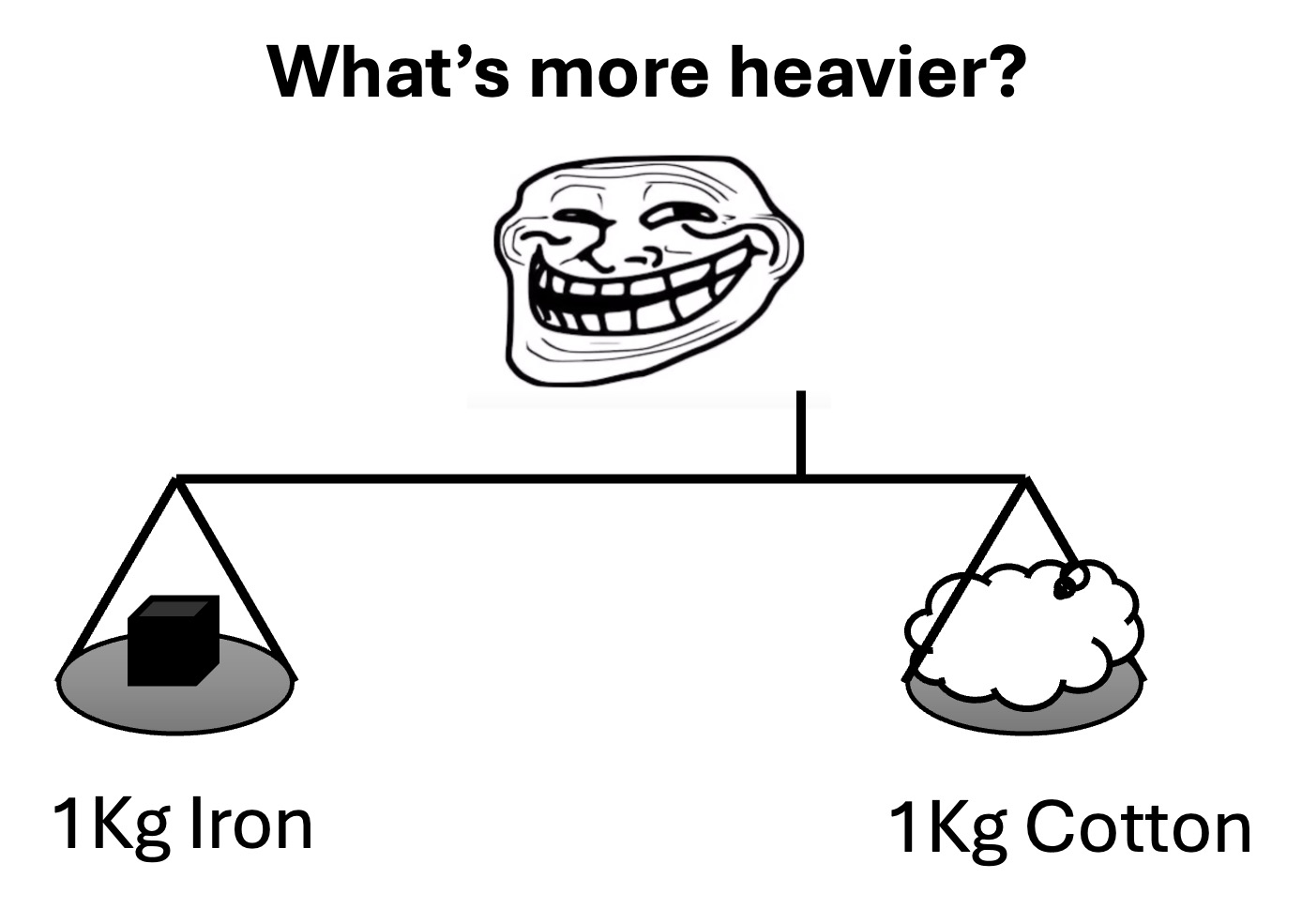
Q: Neglecting air buoyancy (vacuum), which side will go down, iron or cotton?
GT: iron
Required capabilities: Recognition, OCR, spatial awareness, knowledge

Q: How many dwarfs are there near Snow White in the image?
GT: 6
Required capabilities: Recognition, spatial awareness
@article{yu2024mmvetv2,
title={MM-Vet v2: A Challenging Benchmark to Evaluate Large Multimodal Models for Integrated Capabilities},
author={Weihao Yu and Zhengyuan Yang and Lingfeng Ren and Linjie Li and Jianfeng Wang and Kevin Lin and Chung-Ching Lin and Zicheng Liu and Lijuan Wang and Xinchao Wang},
journal={arXiv preprint arXiv:2408.00765},
year={2024}
}