[TOC]
中国电子科技集团公司认知与智能技术重点实验室发布的MaCA(Multi-agent Combat Arena)环境,是国内首个可模拟军事作战的轻量级多智能体对抗与训练平台,是多智能体对抗算法研究、训练、测试和评估的绝佳环境,可支持作战场景和规模自定义,智能体数量和种类自定义,智能体特征和属性自定义,支持智能体行为回报规则和回报值自定义等。目前发布的MaCA环境中预设了两种智能体类型,探测单元和攻击单元:探测单元可模拟L、S波段雷达进行全向探测,支持多频点切换;攻击单元具备侦察、探测、干扰、打击等功能,可模拟X波段雷达进行指向性探测,模拟L、S、X频段干扰设备进行阻塞式和瞄准式电子干扰,支持多频点切换。攻击单元还可模拟对敌方进行火力攻击,同时具有无源侦测能力,可模拟多站无源协同定位和辐射源特征识别。 MaCA 环境为研究利用人工智能方法解决大规模多智能体分布式对抗问题提供了很好的支撑,专门面向多智能体深度强化学习开放了 RL-API 接口。环境支持使用 Python 语言进行算法实现,并支持Tensorflow、Pytorch 等常用深度学习框架的集成调用。
- Linux 64-bit 、Mac OS或windows10 x64操作系统
- Python 3.6及后续版本
- Numpy、Pandas、Pygame软件包
- 安装支撑软件包
pip install -U numpy pandas pygame- 下载环境
git clone https://github.com/CETC-TFAI/MaCA.git- 环境配置
- 命令行形式(适用于Linux、Mac)
cd MaCA
export PYTHONPATH=$(pwd)/environment:$PYTHONPATH- Pycharm中配置(适用于Windows、Linux、Mac)
- 在Pycharm打开MaCA
- 将“environment”文件夹设置为“Sources Root”
- 运行MaCA中任何py文件必须将其“Working Directory”设置为MaCA根目录
运行fight_mp.py,即可开启一场基于预置规则的异构对抗
python fight_mp.py对抗场景如下图:
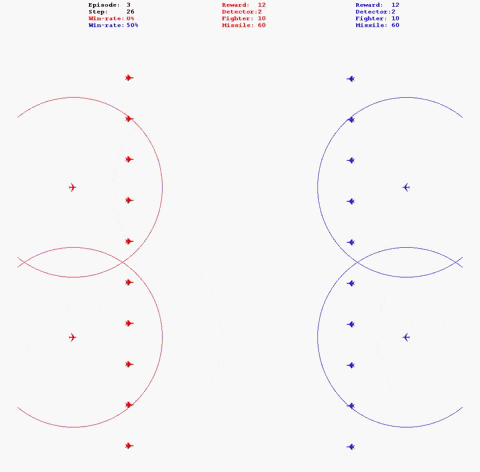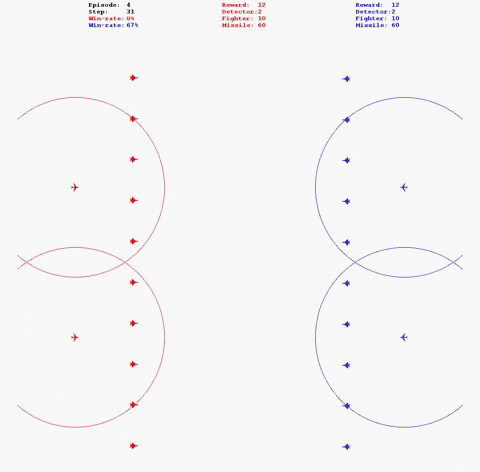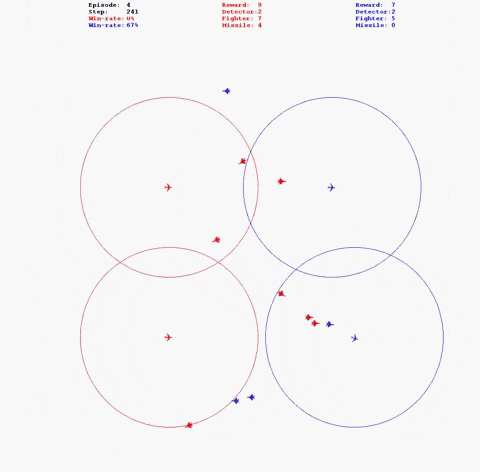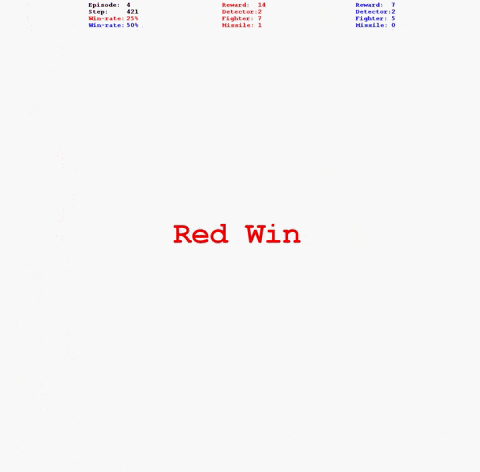
- 运行对抗时增加“--log”参数,即可在log路径下生成以“红方_名称vs_蓝方名称”命名的日志文件夹,其中存储本局对抗相关信息。
python fight_mp.py --log- 默认对抗示例的日志名称为“fix_rule_vs_fix_rule”,使用replay.py即可进行日志回放:
python replay.py fix_rule_vs_fix_rule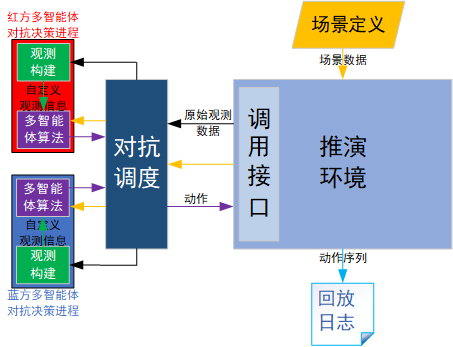
MaCA核心架构如上图所示,由推演引擎环境辅以对抗调度模块,对抗场景库(maps)构成。与外围的决策算法代码相结合,实现多智能体决策训练及对抗。主要模块功能如下:
- 推演环境:承担核心推演功能,负责载入作战场景,对外输出原始战场状态数据(raw obs),接收双方决策算法给出的动作控制信息,执行一系列位置更新、电磁传播、攻击决策算法,实现对抗推演,同时具有现实及日志记录功能。
- 调用接口:外部模块与推演环境的交互接口
- 对抗调度:负责启动红蓝对抗,可对对抗多方面参数进行自定义,如双方决策程序指定、对抗局数、场景选择、每局最高持续帧数等等,同时向决策进程转发推演环境输出的状态数据,接收决策进程输出的动作信息
- 决策进程:红蓝双方对抗控制决策以单独子进程形式存在,相互隔离,主要包括两个模块
- 决策算法:智能体决策算法,接收观测数据,输出动作控制数据
- 观测构建:每个决策算法对应的观测信息构建,由原始状态数据生成与决策算法需求对应的观测数据。
MaCA代码结构与上述模块划分一致,具体如下图:
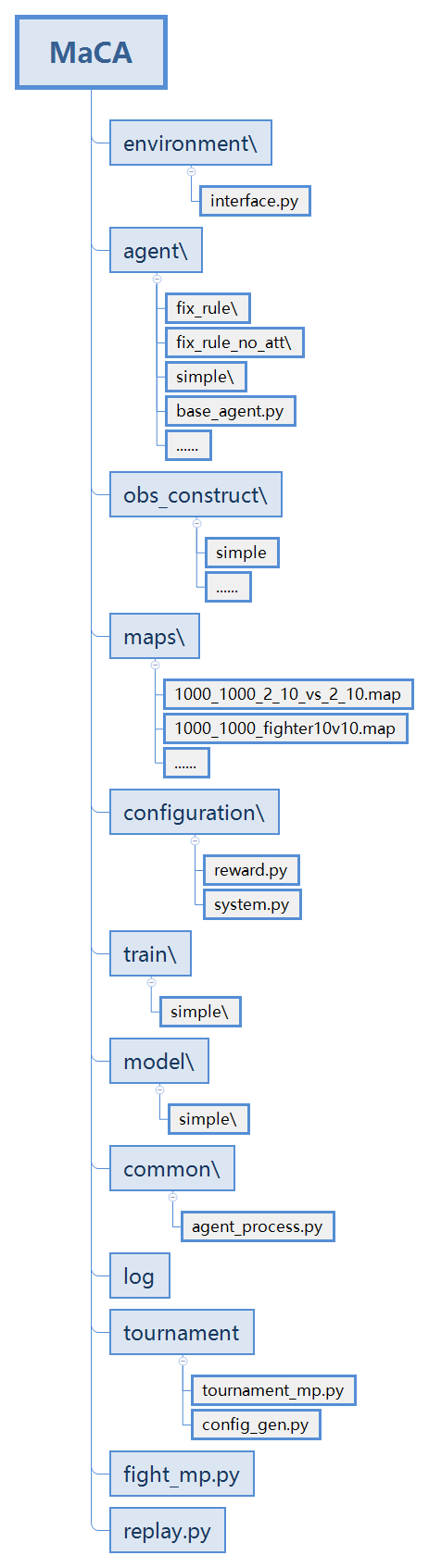
- environment/:推演环境
- interface.py:环境调用接口
- agent/:用于存储封装好的可直接调用的智能体决策代码,每个决策代码可单独设立一个文件夹,按照标准封装,系统直接调用
- fix_rule/:基于规则的同构异构对抗决策算法
- fix_rule_no_att/:基于规则的同构异构对抗决策算法(无攻击能力)
- simple/:基于DQN的同构对抗决策示例算法,需使用pytorch
- obs_construct/:观测值组织形式自定义,开发者可根据算法需要自定义obs结构
- simple/:基于DQN的同构对抗决策示例对应的obs组织
- fight_mp.py:对抗调度程序
- replay.py 日志回放入口程序
- maps/:对抗场景库
- 1000_1000_2_10_vs_2_10.map:预置异构对抗场景
- 1000_1000_fighter10v10.map:预置同构对抗场景
- configuration/:配置数据
- train/:决策算法训练所在路径
- simple/:simple决策模型训练代码
- model/:决策模型数据存储路径
- simple/:simple决策模型数据存储路径
- common/:多模块复用代码
- agent_process.py:对抗调度和比赛调度模块公用子进程管理代码
- log/:对抗日志存储路径
- tournament/:多智能体比赛调度及结果统计模块
- tournament_mp.py:比赛调度程序
- config_gen.py:比赛配置辅助生成工具
MaCA环境的接口定义在interface.py 文件的Environment类中,其接口函数如下:
| 接口函数 | 描述 |
|---|---|
| init | 环境实例初始化 |
| reset | 环境重置 |
| step | 环境运行一步 |
| get_obs | 获得组合的观测信息 |
| get_done | 判断对抗是否结束 |
| get_alive_status | 获取各作战单元的存活状态 |
| get_map_size | 获取地图大小信息 |
| get_unit_num | 获取各类别作战单元数目 |
| get_unit_property_list | 获取各作战单元属性信息 |
| get_reward | 获取回报 |
参数:
| 序号 | 参数名 | 功能 | 存在性 | 赋值规则 |
|---|---|---|---|---|
| 1 | map_path | 地图路径 | 必选 | MaCA根目录下开始的完整地图文件路径,如“maps/1000_1000_fighter10v10.map” |
| 2 | side1_obs_ind | 红方使用的obs构建模块 | 必选 | 使用raw obs则赋值为“raw”,使用其他自定义obs构建则输入对应构建模块所在文件夹名 |
| 3 | side2_obs_ind | 蓝方使用的obs构建模块 | 必选 | 同side2_obs_ind |
| 4 | max_step | 每局最大步长 | 可选 | 正整数值,不赋值此参数则使用默认值5000 |
| 5 | render | 是否开启显示 | 可选 | True:开启显示,False:关闭显示。不使用此参数则为默认不开启 |
| 6 | render_interval | 每隔几步显示一帧 | 可选 | 正整数值,不赋值此参数则使用默认每步都显示 |
| 7 | random_pos | 是否使用随机出生位置 | 可选 | True:开启随机出生,False:关闭示。不使用此参数则为默认红方在左侧蓝方在右侧 |
| 8 | log | 日志记录开启指示 | 可选 | False:不开启日志,其他字符串值:日志文件夹名称。不使用此参数则默认不开启 |
| 9 | random_seed | 指定随机种子 | 可选 | -1:不指定随机种子,其他正整数:指定随机种子。不使用此参数则默认不指定,由环境生成。该参数主要用于回放时载入原始种子重现对抗场景,fight和train时不需考虑。 |
返回值:无
参数:无 返回值:无
参数:
| 序号 | 参数名 | 功能 | 存在性 | 赋值规则 |
|---|---|---|---|---|
| 1 | side1_detector_action | 红方探测单元动作集 | 必选 | 参见动作结构 |
| 2 | side1_fighter_action | 红方干扰打击单元动作集 | 必选 | 参见动作结构 |
| 3 | side2_detector_action | 蓝方探测单元动作集 | 必选 | 参见动作结构 |
| 4 | side2_fighter_action | 蓝方干扰打击单元动作集 | 必选 | 参见动作结构 |
参数:无 返回值:
| 序号 | 返回值名 | 功能 | 数据形式 |
|---|---|---|---|
| 1 | side1_obs | 红方obs | 参见raw obs |
| 2 | side2_obs | 蓝方obs | 同上 |
参数:无 返回值:无
参数:无 返回值:
| 序号 | 返回值名 | 功能 | 数据形式 |
|---|---|---|---|
| 1 | side1_detector | 红方探测单元单步回报 | 整型 |
| 2 | side1_fighter | 红方打击干扰单元单步回报 | 整型 |
| 3 | side1_round | 红方本局输赢回报 | 整型 |
| 4 | side2_detector | 蓝方探测单元单步回报 | 整型 |
| 5 | side2_fighter | 蓝方打击干扰单元单步回报 | 整型 |
| 6 | side2_round | 蓝方本局输赢回报 | 整型 |
为使得环境能够返回Agent对抗或训练时自定义的状态信息,自组织状态信息的接口统一放在obs_construct/下,如simple智能体中指定obs_ind为simple,则应在obs_construct模块下构建simple文件夹,每一个信息组织形式文件夹下必须包含construct.py文件,且该文件定义ObsConstruct类及obs_construct成员函数,成员函数接口如下:
def obs_construct(self, obs_raw_dict)
# obs_raw_dict为raw信息结构为方便统一对抗调用形式,限定Agent必须包含如下成员、函数接口及固定格式的返回值。
from agent.base_agent import BaseAgent
class Agent(BaseAgent):
def __init__(self): #初始化接口
BaseAgent.__init__(self) #从BaseAgent继承
self.obs_ind = 'raw' #状态信息形式,’raw’表示原始信息形式
#注:可根据原始信息自行组织新的信息,可参考simple
def set_map_info(self, size_x, size_y, detector_num, fighter_num):#读取地图信息
pass #根据需要自行选择函数实现形式
def get_action(self, obs_dict, step_cnt): #obs_dict为状态,step_cnt为当前步数(从1开始)
return detector_action, fighter_action环境底层原始观测数据Raw data Observation结构为字典,包含三部分内容分别为detector_obs_list、fighter_obs_list、join_obs_dict。 detector_obs_list表示探测单元信息,结构为detector数目的list。每一个元素为字典结构,表示当前detector的obs信息,具体内容如下:
| Key | Value |
|---|---|
| id | 探测单元id编号,从1开始 |
| alive | 攻击单元存活状态 |
| pos_x | 横向坐标(位置坐标体系圆点为左上角,水平向右为x,垂直向下为y) |
| pos_y | 纵向坐标(位置坐标体系圆点为左上角,水平向右为x,垂直向下为y) |
| course | 航向(0-359),水平向右为0度,顺时针旋转 |
| r_iswork | 雷达开关状态 |
| r_fre_point | 雷达频点 |
| r_visible_list | 雷达观测到的敌方单位列表,每一元素字典,表示敌方单位信息,结构为 {‘id’:编号,’type’:类型(0:探测单元,1:攻击单元) ,‘pos_x’:横向坐标,’pos_y’:纵向坐标} |
| last_reward | 上一个状态采用动作的回报 |
| last_action | 上一个状态采用的动作(字典结构) {‘course’:,’r_iswork’:,’r_fre_point’: } |
fighter_obs_list表示攻击单元信息,结构为detector数目的list。每一个元素为字典结构,表示当前detector的obs信息,具体内容如下:
| Key | Value |
|---|---|
| id | 攻击单元id编号,编号从探测单元数目开始 |
| alive | 攻击单元存活状态 |
| pos_x | 横向坐标(位置坐标体系圆点为左上角,水平向右为x,垂直向下为y) |
| pos_y | 纵向坐标(位置坐标体系圆点为左上角,水平向右为x,垂直向下为y) |
| course | 航向(0-359),水平向右为0度,顺时针旋转 |
| r_iswork | 雷达开关状态 |
| r_fre_point | 雷达频点 |
| r_visible_list | 雷达观测到的敌方单位列表,每一元素字典,表示敌方单位信息,结构为 {‘id’:编号,’type’:类型(0:探测单元,1:攻击单元) ,‘pos_x’:横向坐标,’pos_y’:纵向坐标} |
| j_iswork | 干扰雷达开关 |
| j_fre_point | 干扰雷达频点 |
| j_recv_list | 雷达被动观测的敌方单位列表,每一元素字典,表示敌方单位信息,结构为 {‘id’:编号,’type’: 类型(0:探测单元,1:攻击单元) ,’direction’:目标相对自身的方向,’r_fp’:频点} |
| l_missle_left | 远程导弹剩余数目 |
| s_missle_left | 短程导弹剩余数目 |
| striking_list | 打击列表[{'attacker_id': 攻击者编号, 'target_id': 目标编号, 'missile_type': 导弹类型(1:远程,2:中程), information_source_type: 信息来源类型(0:L探测单元,1:S探测单元,2:战机,3:被动侦测) step_count: step计数, op_count: 观测点计数, del_ind: 删除指示(默认false)}] |
| striking_dict_list | 攻击列表[{‘target_id’:目标编号,‘pos_x’:横向坐标,’pos_y’:纵向坐标,‘type’: 类型(0:探测单元,1:攻击单元) }] |
| last_reward | 上一个状态采用动作的回报 |
| last_action | 上一个状态采用的动作(字典结构) {‘course’:,’r_iswork’:,’r_fre_point’:,’j_iswork’:,’j_fre_point’;,’hit_target’:,’missle_type’:} |
joint_obs_list为表示全局信息的字典{‘strike_list’:打击列表,’passive_detection_enemy_list’:被动侦测列表}。strike_list为每一个作战单元striking_list的并集,passive_detection_enemy_list:[{‘id’:敌方编号,’type’: 类型(0:探测单元,1:攻击单元),‘pos_x’:横向坐标,’pos_y’:纵向坐标}]
以2个探测单元,10个攻击单元为例,则: detector_action为2*2的数组,每一行表示每一个探测单元的两个动作:
| 意义 | 取值范围 | |
|---|---|---|
| 动作1 | 航向 | [0-359]离散值 |
| 动作2 | 雷达开关及频点 | 频点[0,频点总数],0表示雷达关,非0表示开机对应频点 |
fighter_action为10*4的数组,每一行表示每一个攻击单元的四个动作:
| 意义 | 取值范围 | |
|---|---|---|
| 动作1 | 航向 | [0-359]离散值 |
| 动作2 | 雷达开关及频点 | 频点[0,频点总数],0表示关,非0表示开机对应频点 |
| 动作3 | 干扰设备开关机频点 | 频点[0,频点总数+1],0表示关,[1,频点总数]表示开机对应频点 频点总数+1:阻塞干扰 |
| 动作4 | 是否发射导弹及攻击目标的id | [0,25] 0:表示不发射导弹 1-12: 表示远程导弹攻击敌方目标id 13-24: 表示中程导弹攻击敌方目标id+12 |
回报信息可以通过Environment 接口中的get_reward获得,具体结构如下: 以2个探测单元,10个攻击单元为例,则:
- detector_reward为(2,)的numpy数组,每一个元素表示每一个探测单元的动作回报
- fighter_reward为(10,)的numpy数组,每一个元素表示每一个攻击单元的动作回报
- round_reward为游戏输赢的回报,此回报只有当一局对抗结束才有效
决策的功能是接收观测量并处理,选择合适的动作,并与环境交互。这里将多智能体决策程序称为agent,代码存放在agent路径中,子文件夹名称作为该agent名称。其中,agent.base_agent模块定义了所有agent的基类BaseAgent,其中定义了一些基本数据以及观测信息构建类指示函数:
def get_obs_ind(self):
"""
obs indication
:return: obs构建程序路径指示字符串。对应obs_construct中同名观测构建代码,若该项赋值为'raw'代表使用原始raw obs data
"""
'''返回obs_ind的值'''agent程序最主要的方法是get_action,即接收观测量并返回动作。 一个简单的agent应具有如下形式:
class SimpleAgent(BaseAgent):
def __init__(self):
BaseAgent.__init__(self)
self.obs_ind = 'simple_agent' # 指示本决策agent需要使用哪个观测构建类
'''初始化数据'''
def set_map_info(self, size_x, size_y, detector_num, fighter_num):
"""
获取地图信息
:param size_x: 横向尺寸
:param size_y: 纵向尺寸
:param detector_num: 探测单元数量
:param fighter_num: 攻击单元数量
:return: N/A
"""
'''初始化地图、作战实体相关信息'''
def get_action(self, obs_data, step_cnt):
"""
获取动作
:param obs_data: obs数据
:param step_cnt: 当前step数
:return:
detector_action:侦查单元动作
fighter_action:攻击单元动作
"""
'''由观测信息得到动作并输出'''环境输出的底层观测信息称为raw obs,该数据包括红方或蓝方自身所有可知状态信息。对于不同技术思路的agent来说,可能并不需要所有信息,或者数据构建形式不能满足agent自身需求,此时需要agent编写者基于raw obs进行观测信息重构,环境提供此机制便于开发者自定义观测数据。 观测重构代码应存放于obs_construct/“obs_ind名称”/construct.py,其中“obs_ind名称”应与agent中obs_ind变量赋值相同。一个典型的obs重构代码应具有如下形式:
class ObsConstruct:
def __init__(self, size_x, size_y, detector_num, fighter_num):
"""
obs construct init
:param size_x: 战场横向尺寸
:param size_y: 战场纵向尺寸
:param detector_num: 探测单元数量
:param fighter_num: 攻击单元数量
"""
'''内部数据初始化'''
def obs_construct(self, obs_raw_dict):
'''
obs构建调用接口
:param obs_raw_dict: raw obs数据
:return: 自定义obs数据
'''
'''接收raw obs,构建新obs'''agent及配套obs construct按上述要求编写完成后,使用fight_mp进行对抗时会自动生成agent所需观测数据提供给agent进行动作决策。
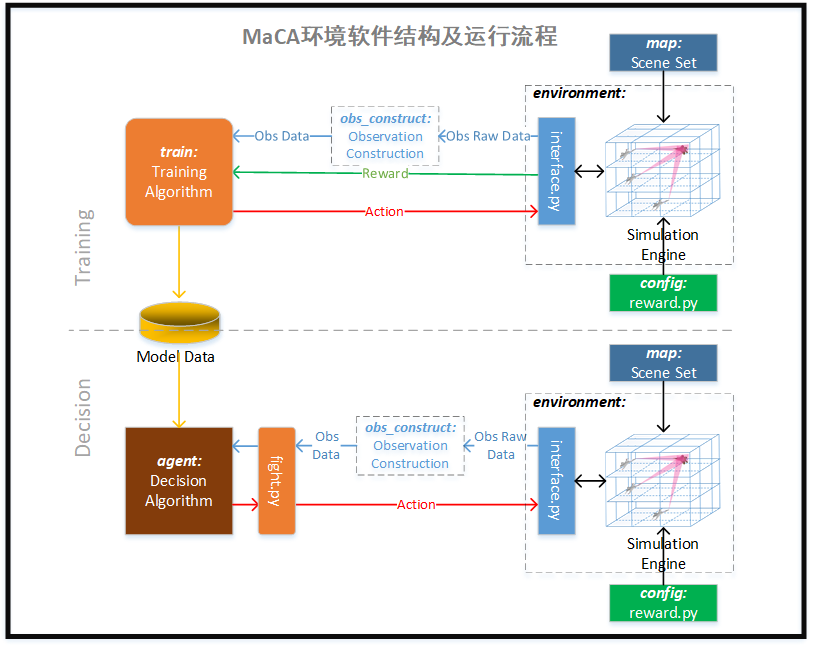
对于使用强化学习等机器学习方法构建的agent程序,需要进行一系列的训练,形成模型数据,才可以实现较好的动作决策。推荐将训练代码存放于“train/agent同名子文件夹”路径下,生成的模型数据存放于“model/agent同名子文件夹”,便于管理使用。 由于不同技术思路下的agent训练过程各不相同,本环境无法提类似fight_mp的统一训练管控入口,需要开发者自己编写训练调度程序,调用环境接口进行训练。对抗执行流程如下:
- 实例化双方agent
- 获取双方obs_ind
- 调用environment.interface.Environment()创建环境
- environment.interface.get_map_info()获取地图信息
- 将地图信息传给每个agent各自的set_map_info()
- 进入step推进的循环
- environment.interface.Environment.get_obs()获取obs信息
- 使用agent的get_action()将obs传输给agent并获取动作指令
- environment.interface.Environment.step()将动作返回环境,进行下一步推演
- 每一step完成后通过environment.interface.Environment.get_reward()获得回报数据,通过每一step完成后通过environment.interface.Environment.get_done()判断本局是否结束。
具体训练流程可参考train/simple/main.py
中国电子科技集团公司认知与智能技术重点实验室发布的MaCA环境为多智能体对抗算法研究领域带来了一个全新的实验、训练与评估验证平台,为广大研究者提供了更多的交流学习机会。众多军队科研机构,企业科研机构,高等院校都在这个“竞技场”上修炼升级,同台竞技,相互促进,共同提高,将极大地促进军事智能算法研究和重大基础科学问题的解决,实现军事智能跨越式发展和实质性突破,为军事智能未来应用打下坚实基础。