The Python interpreter is normally limited to run on a single thread at a time by Python's global interpreter lock, or GIL. This design makes the interpreter's design simpler but makes it hard to write multithreaded Python programs. The most common workaround is Python's multiprocessing module which provides a way to run multiple cooperative Python processes. However, multiprocessing has several downsides. First, managing multiple processes is much more complicated than managing a single process, with tasks like running a debugger being substantially more difficult in the multiprocessing case. Furthermore, sharing non-Python data between the processes can be tricky. For instance in PyTorch we have a lot of CUDA-allocated Tensors that we would like to share between processes, but to do this we have to carefully allocate them into the systems "shared memory" to make sure all processes can see them, and we have to have custom management of the lifetime of these objects.
Future versions of Python will have a mechanism for allocating multiple separate interpreters in a single process, but this will not be available until Python 3.10 at the earliest. Even then, lots of Python extension modules, PyTorch and Numpy included, make the assumption that there is only one interpreter and one GIL. They will need to be modified to be compatible with these extensions.
But it is possible today to get multiple interpreters in a single process without modifying most extensions! It just requires loading the entire Python library multiple times.
The reason having multiple Python interpreters is hard is because CPython's API has a lot of global symbols and values like the interpreter lock. By writing a custom shared library loader, we can arrange that multiple copies of Python and its extensions libaries can be loaded in a single process such that they cannot see each other. Nevertheless, data allocated in C/C++ such as PyTorch Tensors can be shared across interpreters since they exist in the same process.
A shared library loader is the part of libc accessed by dlopen which reads shared libraries into memory. The normal Unix loader is inflexible: it will only ever load a library once, and it has a fixed method for linking the symbols of that library with the running process. However, nothing stops us from writing our own loader with a more flexible API for symbol resolution:
// linker.h
struct SymbolProvider {
SymbolProvider() {}
virtual at::optional<Elf64_Addr> sym(const char* name) const = 0;
// for symbols referring to thread local state (TLS)
virtual at::optional<TLSIndex> tls_sym(const char* name) const = 0;
SymbolProvider(const SymbolProvider&) = delete;
SymbolProvider& operator=(const SymbolProvider&) = delete;
virtual ~SymbolProvider() {}
};
// RAII wrapper around dlopen
struct SystemLibrary : public SymbolProvider {
// create a wrapper around an existing handle returned from dlopen
// if steal == true, then this will dlclose the handle when it is destroyed.
static std::shared_ptr<SystemLibrary> create(
void* handle = RTLD_DEFAULT,
bool steal = false);
static std::shared_ptr<SystemLibrary> create(const char* path, int flags);
};
struct CustomLibrary : public SymbolProvider {
static std::shared_ptr<CustomLibrary> create(
const char* filename,
int argc = 0,
const char** argv = nullptr);
virtual void add_search_library(std::shared_ptr<SymbolProvider> lib) = 0;
virtual void load() = 0;
};
Here a SymbolProvider is an abstract object that can resolve symbol names (strings) to an address (Elf64_Addr). The SystemLibrary class does this as a wrapper around the system loader using dlopen and dlsym. The CustomLibrary is our custom loader's API. It resolves symbols by looking through a list of SymbolProvider objects which can be backed by the system or other custom libraries.
We can use this API to get multiple Python's in the same process:
std::vector<CustomLibraryPtr> python_libs_;
// RTLD_GLOBAL, the symbols in the current process
auto global = SystemLibrary::create();
for (int i = 0; i < 2; ++ i) {
auto p = CustomLibrary::create(PYTHON_SO_PATH);
p->add_search_library(global);
p->load();
python_libs_.push_back(p);
}
It's hard to use these interpreters directly because all of the Python API functions have to be looked up using the sym method. Instead of doing it that way, we can create another shared library libpython_runner.so that contains our interaction with the Python API:
// python_runner.cpp
struct PythonGuard {
PythonGuard() {
Py_Initialize();
// this has to occur on the thread that calls finalize
// otherwise 'assert tlock.locked()' fails
py::exec("import threading");
// release GIL after startup, we will acquire on each call to run
PyEval_SaveThread();
}
~PythonGuard() {
PyGILState_Ensure();
Py_Finalize();
}
};
static PythonGuard runner;
extern "C" void run(const char * code) {
// use pybind11 API to run some code
py::gil_scoped_acquire guard_;
py::exec(code);
}
Now we can link that against the Python library and use it to run code by exposing the run function which compiles and execs a string of Python. Wrapping it up an in object we get:
struct PythonAPI {
PythonAPI() {
auto global = SystemLibrary::create();
python_ = CustomLibrary::create(PYTHON_SO_PATH);
python_->add_search_library(global);
python_->load();
python_runner_ = CustomLibrary::create("libpython_runner.so");
python_runner_->add_search_library(python_);
python_runner_->add_search_library(global);
python_runner_->load();
}
void run(const char* code) {
auto run = (void(*)(const char* code)) python_runner_->sym("run").value();
run(code);
}
CustomLibraryPtr python_;
CustomLibraryPtr python_runner_;
};
We can then make multiple copies of the object to get multiple interpreters. Let's time using a single one against using two to show that we really have two separate GILs
auto example_src = R"end(
print("I think None is", id(None))
from time import time
def fib(x):
if x <= 1:
return 1
return fib(x - 1) + fib(x - 2)
def do_fib():
s = time()
fib(30)
e = time()
print(e - s)
)end";
int main() {
PythonAPI a;
PythonAPI b;
a.run(example_src);
b.run(example_src);
std::cout << "fib(30) for single interpreter\n";
std::thread t0([&]{
a.run("do_fib()");
});
std::thread t1([&]{
a.run("do_fib()");
});
t0.join();
t1.join();
std::cout << "fib(30) for 2 interpreters\n";
std::thread t2([&]{
a.run("do_fib()");
});
std::thread t3([&]{
b.run("do_fib()");
});
t2.join();
t3.join();
}
When we run this we get:
I think None is 139756875126544
I think None is 139756860208912
fib(30) for single interpreter
0.5423781871795654
0.5387833118438721
fib(30) for 2 interpreters
0.2851290702819824
0.28827738761901855
You can see that each interpreter is really different because they have a different id for the singleton None object. Furthermore running two threads in separate interpreters is nearly twice as fast at computing fib as a single interpreter used in two threads.
We now have a way to get multiple Python interpreters in a process. A problem arises when we try to use any extension library:
a.run("import regex");
> terminate called after throwing an instance of 'pybind11::error_already_set'
> what(): ImportError: [...]/unicodedata.cpython-38-x86_64-linux-gnu.so: undefined symbol: _PyUnicode_Ready
Because Python is calling dlopen on any C extension library, those libraries cannot see the Python symbols we loaded with the CustomLibrary object. The system loader doesn't know about the symbols we loaded.
Internally CPython calls _PyImport_FindSharedFuncptr to do this loading, so we can fix this problem by overriding it with our own implementation:
// find_shared_function.cpp
extern "C" {
CustomLibraryPtr the_python_library;
}
// note: intentially leaking the vector so that
// dtors on the loaded libraries do not get called.
// this module will unload after python so it is unsafe
// for destruct the loaded libraries then.
auto loaded = new std::vector<CustomLibraryPtr>;
typedef void (*dl_funcptr)(void);
extern "C" dl_funcptr _PyImport_FindSharedFuncptr(
const char* prefix,
const char* shortname,
const char* pathname,
FILE* fp) {
std::cout << "CUSTOM LOAD SHARED LIBRARY " << pathname << "\n";
auto lib = CustomLibrary::create(pathname);
lib->add_search_library(SystemLibrary::create());
lib->add_search_library(the_python_library);
lib->load();
auto init_name = fmt::format("{}_{}", prefix, shortname);
auto result = (dl_funcptr)lib->sym(init_name.c_str()).value();
loaded->emplace_back(std::move(lib));
return result;
}
Note that we need a reference to the_python_library which we want to link the extensions against. Since this will be different for each interpreter, we need different copies of this function for each interpreter. When you have a hammer, every problem looks like a nail, so we will generate multiple copies of this function by using the custom loader to load it multiple times. We can modify our PythonAPI object from before to put these pieces together:
struct PythonAPI {
PythonAPI() {
auto global = SystemLibrary::create();
+ find_shared_function_ = CustomLibrary::create("libfind_shared_function.so");
+ find_shared_function_->add_search_library(global);
+ find_shared_function_->load();
python_ = CustomLibrary::create(PYTHON_SO_PATH);
+ python_->add_search_library(find_shared_function_);
python_->add_search_library(global);
python_->load();
+ auto find_shared_python_ref = (CustomLibraryPtr*) find_shared_function_->sym("the_python_library").value();
+ *find_shared_python_ref = python_;
python_runner_ = CustomLibrary::create("libpython_runner.so");
python_runner_->add_search_library(python_);
python_runner_->add_search_library(global);
python_runner_->load();
}
void run(const char* code) {
auto run = (void(*)(const char* code)) python_runner_->sym("run").value();
run(code);
}
+ CustomLibraryPtr find_shared_function_;
CustomLibraryPtr python_;
CustomLibraryPtr python_runner_;
};
With this change, now we can dynamically load extension libraries into the Python interpreters and they will correctly link their extensions against their own API:
a.run("import regex");
> CUSTOM LOAD SHARED LIBRARY [...]/lib-dynload/_heapq.cpython-38-x86_64-linux-gnu.so
> CUSTOM LOAD SHARED LIBRARY [...]/lib-dynload/unicodedata.cpython-38-x86_64-linux-gnu.so
> CUSTOM LOAD SHARED LIBRARY [...]/site-packages/regex/_regex.cpython-38-x86_64-linux-gnu.so
This is pretty cool because it allows us to use extension libraries (and Python itself!) without modification.
We've tested this with numpy, and it appears to pass the numpy.test() test suite when run simultaneously on two separate threads (except for a few tests that directly call dlopen, which are expected to fail in this setup):
auto run_numpy = R"end(
import numpy as np
print(np.arange(10)*10)
)end";
a.run(run_numpy);
> CUSTOM LOAD SHARED LIBRARY [...]/numpy/core/_multiarray_umath.cpython-38-x86_64-linux-gnu.so
> [...]
> CUSTOM LOAD SHARED LIBRARY [...]/numpy/random/_generator.cpython-38-x86_64-linux-gnu.so
> [ 0 10 20 30 40 50 60 70 80 90]
It might seem like loading multiple copies of Python and all of its extensions is going to take a lot of RAM. But most of the libraries are read-only program text and debug information. Since these sections are mmap'd into the process directly from the library file, the RAM for all the read-only pages will be shared across all interpreters. Only the global variables, and some relocation tables will get duplicated.
The full source code for these examples also contains the implementation of the custom loader. It is a heavily modified version of Androids libbionic linker. It is only a prototype so it is limited to x86_64 code and ELF-format shared libraries (found on Linux and BSD but not OSX or Windows).
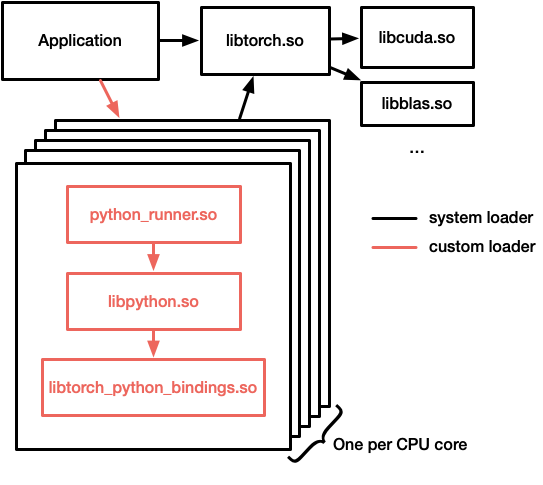
We plan to integrate this custom loading approach into torch::deploy so that C extensions can be used in the private Python interpreters that deploy uses to run deep learning models, but we also wanted to put this independent example together since it may prove useful in other cases where using multiple embedded Python interpreters would be beneficial.
Special thanks to the PyTorch Platform Team, especially Ailing Zhang and Will Constable for getting torch::deploy integrated into PyTorch, and to Greg Clayton for helping figure out how to register custom loaded code with lldb for debugging.