{kind=link}
The RAG Web Pipeline is a versatile tool designed to extract and provide relevant information from websites using the RAG (Retrieval-Augmented Generation) model. This pipeline is particularly useful for tasks such as question-answering, summarization, and dialogue generation directly from web content.
Create a .env file and Add OPENAI_API_KEY = ""
-
Flexible Input Options: The pipeline accepts various input sources, including:
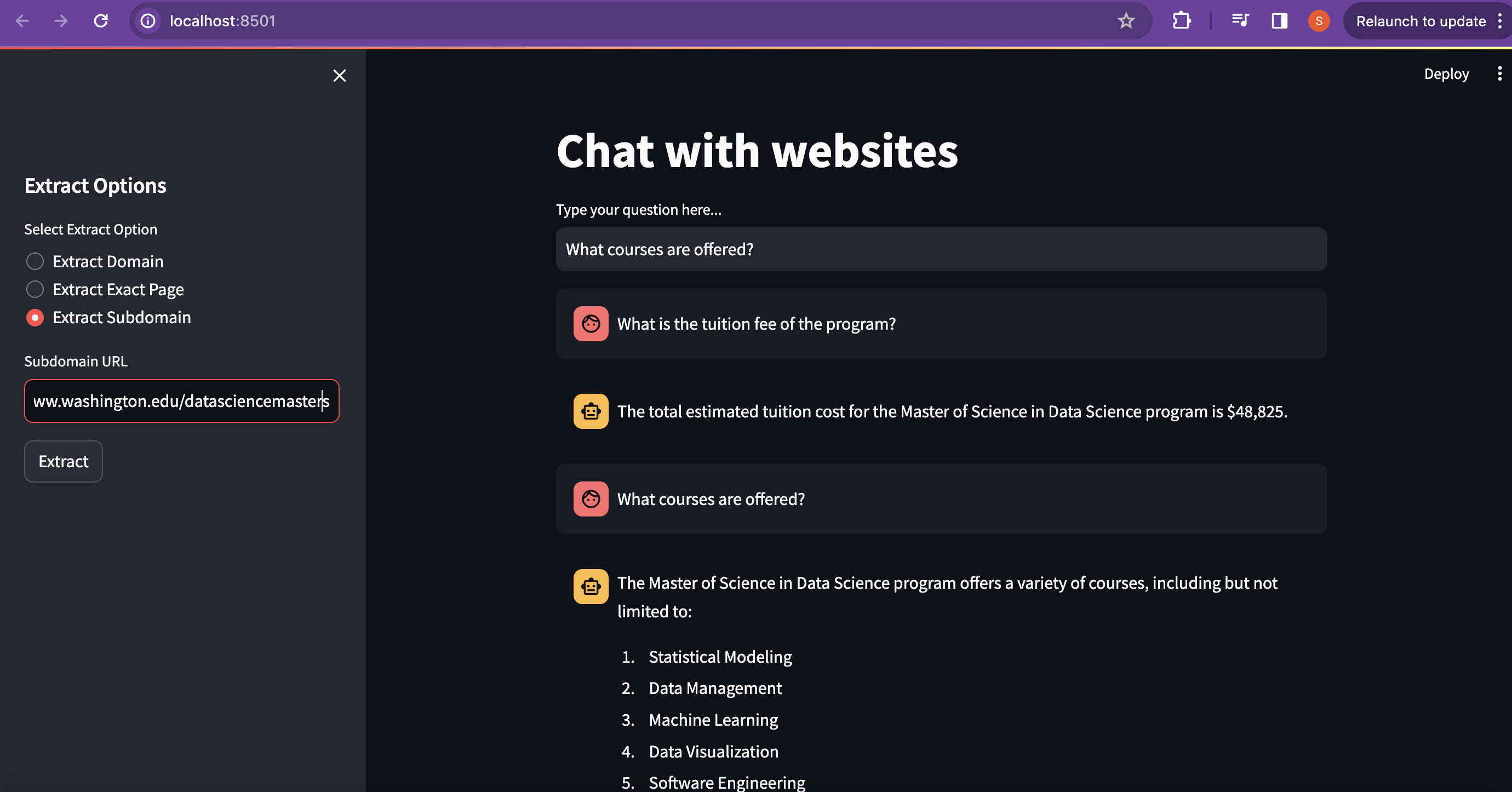
- Direct URL: Extracts information from a specific webpage.
- Website Crawling: Gathers data from the entire website through link crawling.
- Subdomain Crawling: Explores web content starting from a specific subdomain.
-
RAG Model Integration: Utilizes the power of the Retrieval-Augmented Generation (RAG) model to understand and generate responses based on extracted information.
-
Multi-Purpose: Suitable for a wide range of tasks such as information retrieval, question answering, dialogue systems, and content summarization.
-
Input Selection: Users can specify the input type (URL, website crawling, subdomain crawling) based on their requirements.
-
Data Extraction: The pipeline extracts relevant information from the provided source using intelligent web scraping techniques.
-
RAG Model Processing: The extracted data is processed by the RAG model to generate responses to user queries or to provide summaries of the content.
-
Output Presentation: Users can interact with the system through a user-friendly interface to input queries and receive responses generated by the RAG model.
To use the RAG Web Pipeline, simply follow these steps:
-
Clone the repository to your local machine.
-
Install the required dependencies by running
pip install -r requirements.txt. -
Add the OpenAI Key in .env file
-
Launch the pipeline using the provided scripts or integrate it into your existing projects.
-
Select the desired input option (URL, website crawling, subdomain crawling) and provide the necessary inputs.
-
Interact with the system by entering queries and exploring the generated responses.