-
Only tested in Winodws a.k.a my machine. I'm not gradio / webUI expert therefore do not expect any auto / e2e solutions. Also I do not gruntee to have any decent test coverage.
-
Currently SD1, SD2 and SDXL are tested. You cannot merge different UNET architecture. Check out model versions first.
-
No, it have no chance to support SD3 / AuraFlow / Flux. This will be V3 and requires revamp the nasty block prefixes here, and the "UI" that I never use it. I'd do it if someone are willing to manage 50+ layers
-
You will see loads of
Missing key(s) in state_dict:when the settings in A1111 is not correcly loaded. Keep switching UI's selected model to non SDXL models, and try again. If you see a*.yamlis loaded, it is usually success. Sadly it is done in A1111 instead of extensions. -
See the base merger for more details.
-
NO SUPPORT FOR aki / "秋葉" build.
-
Check out sd-webui-bayesian-merger (along with merger base code "meh") which is doing what I'm aiming for, but it doesn't include ImageReward. ljleb's fork is currently in active developement, and has a nice guide. Nah the original 'sdweb-auto-MBW' is not brute force search, but a strange 'binary search', which is not effective or efficient.
-
See my own findings in AutoMBW. Now published to CivitAI also. Contents will not overlap.
-
Feel free to discuss in this original thread, or catch me in Discord / Telegram.
-
Around 33.4GB of system RAM. Counted casually (loads of applications opened), will drop to 26.4GB after first iterlation. It is considered that model must be created in system RAM first, then move to GPU's VRAM.
-
conda(miniconda) for dependency, even A1111 has its ownvenv.
- Install these extensions via "Extensions" > "Install from URL":
- Install
dynamicpromptsvia wheels from pypi:
-
Download the *.whl file (
dynamicprompts-0.29.0-py2.py3-none-any.whl) -
Run in cmd:
"FULL_PATH_OF_YOUR_A1111_WEBUI\venv\Scripts\python.exe" -m pip install path_of_the_whl_file.whl --prefer-binary
- You may face "Premission denied" while moving extension from
tmptoextensions:
-
Either
cd extensionsand thengit clone https_github_com_this_repoand then restart WebUI -
Or make a directory
auto-MBW-rtdirectly intmpthen rerun the installation.
- From AutoMBW V1, make sure your WebUI instance has API enabled as
--apiinCOMMANDLINE_ARGS.
REM IF you have multiple Pythons installed, set this.
set PYTHON=C:\Users\User\AppData\Local\Programs\Python\Python310\python.exe
REM 2nd SD (7861) for 2nd GPU (1)
set COMMANDLINE_ARGS=--medvram --disable-safe-unpickle --deepdanbooru --xformers --no-half-vae --api --port=7861 --device-id=1- Install these extensions via "Extensions" > "Install from URL":
-
pip install -r requirements.txtexplicitly in this directory. I've seendynamicpromptsis failed to install along with A1111. Afterthatpipwill throw some error but A1111 will start eventually.
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
gradio 3.41.2 requires huggingface-hub>=0.14.0, but you have huggingface-hub 0.13.4 which is incompatible.
- (240730) If you experience
ImportError: cannot import name 'xxx', checkout this sourcecode again and explictlypip install xxx. I'm not sure how long it stays compatable with A1111. Freeze A1111 or just seek other mergers.
- "Make payload". Treat it like "trigger words", or anything you like, or testing dataset in AI/ML.
-
A minimal payload (e.g. single 512x512 image) is suggested if you are using it for the first time, to make sure the code works.
programmer's life -
Payloads are stored in
payloads/*.json.
- "Set classifier". I like BayesianOptimizer with ImageReward.
- I will set my recommended values as default.
- "Search". For RTX 3090, it requires around 60x time for each payload. If the payload takes around 15 seconds to complete, it takes around 15 minutes. It applies for a batch using 4 minutes (4.5 hours).
-
Optimization part (on test score) takes only a few seconds to compelete. 26 parameters is easy, comparing to 860M for SD.
-
You may see "Warning: training sequential model failed. Performing random iteration instead." It means that the optimizer has nothing to initialize but pure random. Ignore this if you're going to start from random weights.
- See
csv/history/*/*.csvfor results. Also seemodels/Stable-diffusion/*.test-23110502.recipe.txtfor a formatted recipe.
- Trust me. Always reboot webUI first. Head straight into merging without any operation. State control in WebUI (even Python) is awful.
- Currently I am experiencing Error when updating the "UNET Visualizer" and "Gallery". It is deep into Gradio's Queue and I am unable to fix it. However before it throws error, I can see live update. Since it is not fatal crash, I'll leave it open and ignore this issue. I have found that
every=0.5or10or30will throw this error, butNonewill not, however no preview will be shown. Currently I chooseevery=None, maybe I will make it configurable and let user guess it (tied with image generation time?)
ERROR: Exception in ASGI application
Traceback (most recent call last):
...
h11._util.LocalProtocolError: Can't send data when our state is ERROR- If the worst case happens a.k.a. program crash while merging after optimization, you will need to merge manually with the recipe (27 numbers, indexed from 0 to 26). Since there is bug in sd-webui-runtime-block-merge, please refer the image below. PoC script. tldr: IN00-IN11, M00, TIME_EMBED, OUT00-OUT11, OUT. Fixed in my fork. Swap TIME_EMBED and OUT if using my fork.

- If you want to continue the training as warm start, make sure grid = vertices = random = 0. Then input the "Warm Up Parameters" in sequence as IN00-IN11, M00, TIME_EMBED, OUT00-OUT11, OUT. Same as above. Swap TIME_EMBED and OUT if using my fork. See the recipe with console output, the generated csv and compare with the FULL screenshot (TIME_EMBED and OUT swapped). The console log should align to the CSV, instead of the content in recipe.
{kind=link}
testweights: 0.4,0.9,0.5,0.6,0.5,0.0,0.9,0.9,1.0,0.4,0.3,0.8,0.3,1.0,0.9,0.6,0.8,0.9,0.7,0.6,1.0,0.9,0.6,0.7,0.3,0.6,0.0
...
0.4,0.9,0.5,0.6,0.5,0.0,0.9,0.9,1.0,0.4,0.3,0.8,0.3,1.0,0.9,0.6,0.8,0.9,0.7,0.6,1.0,0.9,0.6,0.7,0.3,0.6,0.0,0.6132534303822829,174590.83615255356,174624.89337921143
- (Related to the previous error), if you see the
hyper_scoreis reporting the same score with wrong iterlation count (e.g. always 0.529 with iter 1, 2, 4, 8 etc.), the merge already failed, and you should restart the WebUI and close the webpage completely. I have found that it is usually caused by Model A / B are same as the WebUI's selected model. I have added checking about this issue.
-
For "Search Type A" and "Search Type B", they are related "Opt (A to B)" for switching streadgy in runtime. By default it is solely using Type A.
-
For "P1 / P2 / P3", they also switch streadgy in runtime, in simple iteration in sequence. By default only P1 is enabled.
Some ML algorithms requires consistency, I'll add reference if I really find the reasoning on this feature. -
"Force CPU" is forced on. I see
RuntimeError: expected device cuda:0 but got device cpuif it is offand it is a headache to trace and move all tensors. -
Both upper limit of "Sampling steps" and "hires Sampling steps" are raised to 2048. SD's Traning step is 1000 and you can further extrapolate to infinity. Now I use 256/64 frequently. Hence the extended range.
-
"Test Intervals" upper range is raised to 10000. Using 20+ for
BayseianOptimizerwill raiseValueError: broadcast dimensions too large.already (np.meshgrid). I was considering 10000 i.e. 4 DP. Unless you are doing exhausive Grid search, any search in relative scale desires for a fine space. Merge ratio is also in relative scale a.k.a fraction, which you don't need 1 DP if you are not required to remember the numbers (opposite of human search in MBW):
all_pos_comb = np.array(np.meshgrid(*pos_space)).T.reshape(-1, n_dim) if args[params["chk_enable_clamping"]]:
search_space.update({str(idx): [*np.round(np.linspace(args[clamp_lower[idx]], args[clamp_upper[idx]], num=args[pass_params["sl_test_interval"]]+1), 8)]})
else:
search_space.update({str(idx): [*np.round(np.linspace(lower, upper, num=args[pass_params["sl_test_interval"]]+1), 8)]})- After serval actual runs, unfourtunately 20 intervals still occasionally throws the same error while performing
meshgrid, meanwhile it takes 2-3 time longer to complete an iterlation, and it is also 2-3 times harder to converge. "Test Intervals" default will be stayed at 10. These are the optimizers usingmeshgrid:
LipschitzOptimizer
BayesianOptimizer
ForestOptimizer- Keep "Test Grouping" as 1. I don't know why we need to repeat the parameters. Is it related to supersampling?
grouping = localargs.pass_through["grouping"]
tunables = localargs.pass_through["tunables"]
testweights = localargs.pass_through["weights"].copy()
for key in tunables:
for interval in range(grouping):
testweights[int(key)*grouping+interval] = localargs[key]-
Initialize Grid / Vertex / Random should be ignored. It is only useful if you are dedicated to search from the extreme ratios first (pure A by experience). Also the search parameters are way too much (24 + 2 in total). It will waste so much time.
-
"Warm Start" will be disabled. It will use hyperactive's API for initialization, and then "Read the parameters from the input of the 26 slidebars in page bottom", if grid = vertices = random = 0. Disable for random initialization (common for DNN training).
-
Clamping / LoRA is untouched. I only moved the UI components to reduce some area.
-
"Early Stop" is enabled with parameters is slighty raise to 27, which is parameter counts. It is a common setting for Early stopping. The iterlation count is also raised to 270 (expect 10 intervals).
-
Search Time is greatly increased to 10000 minutes (around 7 days). It was 2880 minutes (2 days). I have found that my prefered payloads (12 payloads x 1 image) takes longer then 2 days for worst case (expected 12 hours). It is comparable to common SD / LoRA finetuning, but computational power is still minimum (only t2i).
- The efficiency is considered fast..
torch.lerpgreatly reduces overhead.
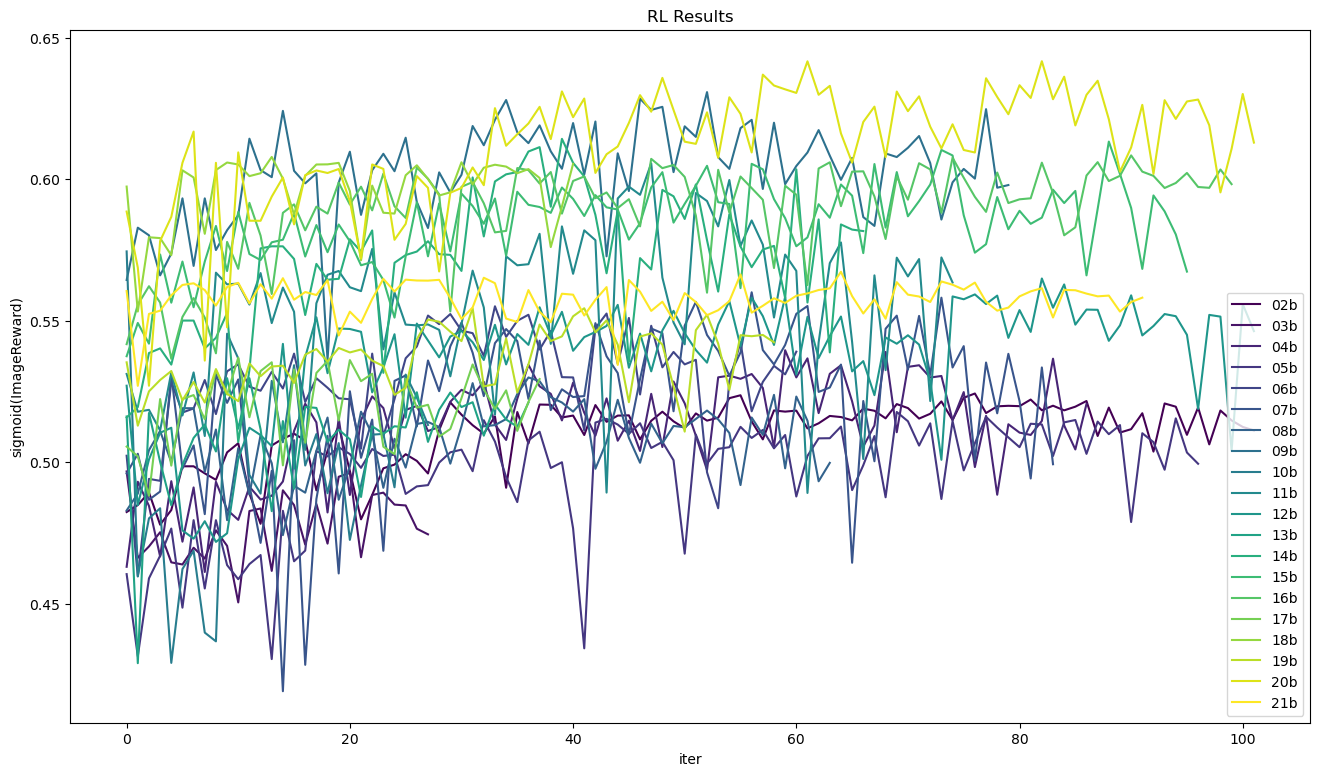
- See this notebook I've made. Transfer the files from
csv/history/[long_folder_name]/[long_file_name].csvto anywhere you want, and then change the path in the notebook (csv_files = glob.glob("[your_folder]/*.csv")), and also rename the csv asid-[long_file_name].csvand execute the notebook. It is similar to the legit training process while finetuning, but the y-axis is inverted, because loss function is usually opposite to reward function. See this article for comparasion.
-
autombw once more with the "average weight" of your merge model.
-
Logger is added. Inspired from sd-webui-animatediff and sd-webui-controlnet .
-
Fix for multiple SD instandces. It reads
--portinstead of hardcodedhttp://127.0.0.1:7860. -
Rearrange the UI components. It is so raw and confusing.
- Just a hobby. If you are feared by tuning for numbers, try "averaging" by simply 0.5, 0.33, 0.25... for 20 models. It works..
NOTE: THIS IS IN BETA. NEWER COMMITS MAY BREAK OLDER ONES. FUNCTIONALITY NOT GUARANTEED.
An automated (yes, that's right, AUTOMATIC) MBW extension for AUTO1111.
Rewritten from scratch (not a deviation) UI and code.
Old (V1) example models here: https://huggingface.co/Xynon/SD-Silicon
Old (V1) article here: https://medium.com/@media_97267/the-automated-stable-diffusion-checkpoint-merger-autombw-44f8dfd38871
Made by both Xynon#7407 and Xerxemi#6423.
Big thanks to bbc-mc for the original codebase and the start of this merge paradigm.
You can find it here: https://github.com/bbc-mc/sdweb-merge-block-weighted-gui
MERGING BACKEND: Huge thanks to ashen
https://github.com/ashen-sensored/sd-webui-runtime-block-merge
LORA BACKEND: Huge thanks to hako-mikan
https://github.com/hako-mikan/sd-webui-lora-block-weight
LORA BACKEND (SOLID): Huge thanks to hako-mikan
https://github.com/hako-mikan/sd-webui-supermerger
OPTIMIZER LIB: Massive thanks to SimonBlanke
https://github.com/SimonBlanke/Hyperactive
Wiki/Documentation
coming soonTM