ddddocr rust 版本。
ocr_api_server rust 版本。
二进制版本,验证码识别,不依赖 opencv 库,跨平台运行。
a simple OCR API server, very easy to deploy。


一个容易使用的通用验证码识别 rust 库
·
报告Bug
·
提出新特性
| 系统 | CPU | GPU | 备注 |
|---|---|---|---|
| Windows 64位 | √ | ? | 部分版本 Windows 需要安装 vc 运行库 |
| Windows 32位 | √ | ? | 不支持静态链接,部分版本 Windows 需要安装 vc 运行库 |
| Linux 64 / ARM64 | √ | ? | 可能需要升级 glibc 版本, 升级 glibc 版本 |
| Linux 32 | × | ? | |
| Macos X64 | √ | ? | M1/M2/M3 ... 芯片参考 #67 |
lib.rs 实现了 ddddocr。
main.rs 实现了 ocr_api_server。
model 目录是模型与字符集。
依赖本库 ddddocr = {git = "https://github.com/86maid/ddddocr.git", branch = "master"}
开启 cuda 特性 ddddocr = { git = "https://github.com/86maid/ddddocr.git", branch = "master", features = ["cuda"] }
支持静态和动态链接,默认使用静态链接,构建时将会自动下载链接库,请设置好代理,cuda 特性不支持静态链接(会自己下载动态链接库)。
如有更多问题,请跳转至疑难杂症部分。
如果你不想从源代码构建,这里有编译好的二进制版本。
还可以使用配置好的 Github Action 进行构建。
旧版本。
主要用于识别单行文字,即文字部分占据图片的主体部分,例如常见的英数验证码等,本项目可以对中文、英文(随机大小写or通过设置结果范围圈定大小写)、数字以及部分特殊字符。
let image = std::fs::read("target.png").unwrap();
let mut ocr = ddddocr::ddddocr_classification().unwrap();
let res = ocr.classification(image, false).unwrap();
println!("{:?}", res);let image = std::fs::read("target.png").unwrap();
let mut ocr = ddddocr::ddddocr_classification_old().unwrap();
let res = ocr.classification(image, false).unwrap();
println!("{:?}", res);classification(image, true);




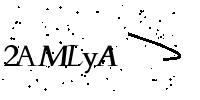




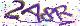


let image = std::fs::read("target.png").unwrap();
let mut det = ddddocr::ddddocr_detection().unwrap();
let res = det.detection(image).unwrap();
println!("{:?}", res);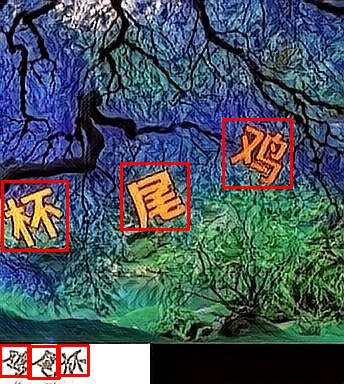

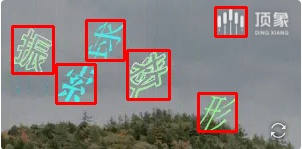


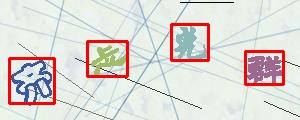

以上只是目前我能找到的点选验证码图片,做了一个简单的测试。
算法非深度神经网络实现。
小滑块为单独的png图片,背景是透明图,如下图:

然后背景为带小滑块坑位的,如下图:

let target_bytes = std::fs::read("target.png").unwrap();
let background_bytes = std::fs::read("background.png").unwrap();
let res = ddddocr::slide_match(target_bytes, background_bytes).unwrap();
println!("{:?}", res);如果小图无过多背景部分,则可以使用 simple_slide_match,通常为 jpg 或者 bmp 格式的图片
let target_bytes = std::fs::read("target.png").unwrap();
let background_bytes = std::fs::read("background.png").unwrap();
let res = ddddocr::simple_slide_match(target_bytes, background_bytes).unwrap();
println!("{:?}", res);一张图为带坑位的原图,如下图:

一张图为原图,如下图:

let target_bytes = std::fs::read("target.png").unwrap();
let background_bytes = std::fs::read("background.png").unwrap();
let res = ddddocr::slide_comparison(target_bytes, background_bytes).unwrap();
println!("{:?}", res);为了提供更灵活的 ocr 结果控制与范围限定,项目支持对ocr结果进行范围限定。
可以通过在调用 classification_probability 返回全字符表的概率。
当然也可以通过 set_ranges 设置输出字符范围来限定返回的结果。
| 参数值 | 意义 |
|---|---|
| 0 | 纯整数 0-9 |
| 1 | 纯小写字母 a-z |
| 2 | 纯大写字母 A-Z |
| 3 | 小写字母 a-z + 大写字母 A-Z |
| 4 | 小写字母 a-z + 整数 0-9 |
| 5 | 大写字母 A-Z + 整数 0-9 |
| 6 | 小写字母 a-z + 大写字母A-Z + 整数0-9 |
| 7 | 默认字符库 - 小写字母a-z - 大写字母A-Z - 整数0-9 |
如果值为 string 类型,请传入一段不包含空格的文本,其中的每个字符均为一个待选词,例如:"0123456789+-x/="
let image = std::fs::read("image.png").unwrap();
let mut ocr = ddddocr::ddddocr_classification().unwrap();
// 数字 3 对应枚举 CharsetRange::LowercaseUppercase,不用写枚举
// ocr.set_ranges(3);
// 自定义字符集
ocr.set_ranges("0123456789+-x/=");
let result = ocr.classification_probability(image, false).unwrap();
// 哦呀,看来数据有点儿太多了,小心卡死哦!
println!("概率: {}", result.json());
println!("识别结果: {}", result.get_text());支持导入 dddd_trainer 训练后的自定义模型。
use ddddocr::*;
let mut ocr = Ddddocr::with_model_charset(
"myproject_0.984375_139_13000_2022-02-26-15-34-13.onnx",
"charsets.json",
)
.unwrap();
let image_bytes = std::fs::read("888e28774f815b01e871d474e5c84ff2.jpg").unwrap();
let res = ocr.classification(&image_bytes).unwrap();
println!("{:?}", res);Usage: ddddocr.exe [OPTIONS]
Options:
-a, --address <ADDRESS>
监听地址 [default: 127.0.0.1]
-p, --port <PORT>
监听端口 [default: 9898]
-f, --full
开启所有选项
--jsonp
开启跨域,需要一个 query 指定回调函数的名字,不能使用 file (multipart) 传递参数, 例如 http://127.0.0.1:9898/ocr/b64/text?callback=handle&image=xxx
--ocr
开启内容识别,支持新旧模型共存
--old
开启旧版模型内容识别,支持新旧模型共存
--det
开启目标检测
--ocr-probability <OCR_PROBABILITY>
开启内容概率识别,支持新旧模型共存,只能使用官方模型, 如果参数是 0 到 7,对应内置的字符集, 如果参数为空字符串,表示默认字符集, 除此之外的参数,表示自定义字符集,例如 "0123456789+-x/="
--old-probability <OLD_PROBABILITY>
开启旧版模型内容概率识别,支持新旧模型共存,只能使用官方模型, 如果参数是 0 到 7,对应内置的字符集, 如果参数为空字符串,表示默认字符集, 除此之外的参数,表示自定义字符集,例如 "0123456789+-x/="
--ocr-path <OCR_PATH>
内容识别模型以及字符集路径, 通过哈希值判断是否为自定义模型, 使用自定义模型会使 old 选项失效, 路径 model/common 对应模型 model/common.onnx 和字符集 model/common.json [default: model/common]
--det-path <DET_PATH>
目标检测模型路径 [default: model/common_det.onnx]
--slide-match
开启滑块识别
--simple-slide-match
开启简单滑块识别
--slide-compare
开启坑位识别
-h, --help
Print help测试是否启动成功,可以通过直接 GET/POST 访问 http://{host}:{port}/ping 来测试,如果返回 pong 则启动成功。
http://{host}:{port}/{opt}/{img_type}/{ret_type}
opt:
ocr 内容识别
old 旧版模型内容识别
det 目标检测
ocr_probability 内容概率识别
old_probability 旧版模型内容概率识别
match 滑块匹配
simple_match 简单滑块匹配
compare 坑位匹配
img_type:
file 文件,即 multipart/form-data
b64 base64,即 {"a": encode(bytes), "b": encode(bytes)}
ret_type:
json json,成功 {"status": 200, "result": object},失败 {"status": 404, "msg": "失败原因"}
text 文本,失败返回空文本
import requests
import base64
host = "http://127.0.0.1:9898"
file = open('./image/3.png', 'rb').read()
# 测试 jsonp,只能使用 b64,不能使用 file
api_url = f"{host}/ocr/b64/text"
resp = requests.get(api_url, params = {
"callback": "handle",
"image": base64.b64encode(file).decode(),
})
print(f"jsonp, api_url={api_url}, resp.text={resp.text}")
# 测试 ocr
api_url = f"{host}/ocr/file/text"
resp = requests.post(api_url, files={'image': file})
print(f"api_url={api_url}, resp.text={resp.text}")cuda 和 cuDNN 都需要安装好。
CUDA 12 构建需要 cuDNN 9.x。
CUDA 11 构建需要 cuDNN 8.x。
不确定 cuda 10 是否有效。
默认使用静态链接,构建时将会自动下载链接库,请设置好代理,cuda 特性不支持静态链接(会自己下载动态链接库)。
如果要指定静态链接库的路径,可以设置环境变量 ORT_LIB_LOCATION,设置后将不会自动下载链接库。
例如,库路径为 onnxruntime\build\Windows\Release\Release\onnxruntime.lib,则 ORT_LIB_LOCATION 设置为 onnxruntime\build\Windows\Release。
默认开启 download-binaries 特性,自动下载链接库。
自动下载的链接库存放在 C:\Users\<用户名>\AppData\ort.pyke.io。
开启动态链接特性 ddddocr = { git = "https://github.com/86maid/ddddocr.git", branch = "master", features = ["load-dynamic"] }
开启 load-dynamic 特性后,可以使用 Ddddocr::set_onnxruntime_path 指定 onnxruntime 动态链接库的路径。
开启 load-dynamic 特性后,构建时将不会自动下载 onnxruntime 链接库。
请手动下载 onnxruntime 链接库,并将其放置在程序运行目录下(或系统 API 目录),这样无需再次调用 Ddddocr::set_onnxruntime_path。
windows 静态链接失败,请安装 vs2022。
linux x86-64 静态链接失败,请安装 gcc11 和 g++11,ubuntu ≥ 20.04。
linux arm64 静态链接失败,需要 glibc ≥ 2.35 (Ubuntu ≥ 22.04)。
macOS 静态链接失败,需要 macOS ≥ 10.15。
cuda 在执行 cargo test 的时候可能会 painc (exit code: 0xc000007b),这是因为自动生成的动态链接库是在 target/debug 目录下,需要手动复制到 target/debug/deps 目录下(cuda 目前不支持静态链接)。
动态链接需要 1.18.x 版本的 onnxruntime。
更多疑难杂症,请跳转至 ort.pyke.io。