This is a fairly complete implementation of Reinforcement Learning with Prediction-Based Rewards in Chainer. For more information on this implementation and intrinsic rewards using random network distillation, check out my blog post.
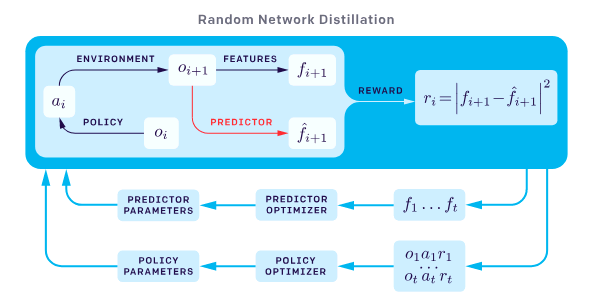
- Why use this implementation when OpenAI provided a full implementation? Because it's much simpler and easy to follow, and is a complete implementation. It uses Chainer rather than Tensorflow.
- As in the paper, the Reinforcement Learning algorithm used is Proximal Policy Optimization (PPO).
- All hyperparameters are mostly the same as those listed in the paper.
- This implementation can seamlessly switch between a recurrent policy (RNN), or convolutional-only policy (CNN). The recurrent layers can be turned off by specifying the argument
--rnn_hidden_layers 0. - The RNN layers can be replaced with a Differentiable Neural Computer (DNC) using the
--dncand--rnn_single_record_trainingflag. You'll need to import my Chainer implementation (dnc.py) from: https://github.com/AdeelMufti/DifferentiableNeuralComputer. I was investigating its use in my work on Probabilistic Model-Based Reinforcement Learning Using The Differentiable Neural Computer. - This implementation was not tested on Montezuma's Revenge, as the environment did not intersect with the work I've been interested in. Nor do I have access to free GPUs that I can leave running for long periods of time. If you have the computation capacity to try it out on Montezuma's Revenge, please let me know how it goes! I believe OpenAI used
MontezumaRevengeNoFrameskip-v4for their experiments. - When I use the term iteration, I mean a full round of performing and logging rollouts, and training the neural networks.
- While the paper defines a total number of rollouts per environment for training (in batches of "Rollout Length"), I define a target cumulative extrinsic rewards score, averaged over the number of trials ("Rollout Length") per iteration. The training will keep going forever until this score is achieved.
- During training, progress is saved at each iteration, and the program automatically resumes training if interrupted.
- I didn't write fancy code to automatically determine the actions per environment, so you will need to define them manually in the
ACTIONSconstant inrl_rnd.py. Note that the current implementation only supports discrete actions. - GPU support is built in, and can be toggled using the
--gpuargument. I would recommend GPUs be used single threaded. Otherwise rollouts on CPUs can be performed multi-threaded, configured through the--num_threadsargument.
Python 3.5 and pip 3 are required. Perform the following steps to clone this repo and install required packages:
- git clone https://github.com/AdeelMufti/RL-RND
- cd RL-RND
- pip install -r requirements.txt
To install Pygame Learning Environment (for PixelCopter-v0 and more):
- git clone https://github.com/ntasfi/PyGame-Learning-Environment
- cd PyGame-Learning-Environment
- pip install -e .
Note: There is a bug in the gym_ple package. Find where your Python 3.5 packages are kept, and edit lib/python3.5/site-packages/gym_ple/ple_env.py, and add the following lines under def __init__():
if game_name == 'PixelCopter':
game_name = 'Pixelcopter'
- python rl_rnd.py [--args]
| Parameter | Default | Description |
|---|---|---|
| --data_dir | /data/rl_rnd | The base data/output directory |
| --game | PixelCopter-v0 | Game to use |
| --experiment_name | experiment_1 | To isolate its files from others |
| --frame_resize | 84 | h x w resize of each observation frame |
| --initial_normalization_num_trials | 8 | Collect observations over this many trials for initialization of RND normalization pramaters |
| --num_trials | 128 | Trials per iteration of training. Referred to as "Rollout Length" in the paper |
| --portion_experience_train_rnd_predictor | 0.25 | As in the RND paper |
| --z_dim | 32 | Dimension of encoded vector |
| --rnn_hidden_dim | 256 | RNN hidden units |
| --rnn_hidden_layers | 1 | RNN hidden layers |
| --rnn_single_record_training | False | Required for DNC |
| --final_hidden_dim | 0 | Units for additional linear layers before final output |
| --final_hidden_layers | 0 | Additional linear layers before final output |
| --epochs_per_iteration | 4 | Number of optimization epochs |
| --sequence_length | 64 | This amount of input records are stacked together for a forward pass |
| --minibatches | 4 | Backprop performed over this many rollouts |
| --stacked_frames | 4 | # of observations stacked together for the value/policy |
| --stacked_frames_rnd | 1 | # of observations stacked together for the RND predictor network |
| --sticky_action_probability | 0.25 | Repeat the previous action with this probability |
| --intrinsic_coefficient | 1.0 | As in the RND paper |
| --extrinsic_coefficient | 2.0 | As in the RND paper |
| --extrinsic_reward_clip | 1.0 | Will be clipped from - to +, as in the RND paper |
| --gamma_intrinsic | 0.99 | Discount factor for intrinsic rewards |
| --gamma_extrinsic | 0.999 | Discount factor for extrinsic rewards |
| --lambda_gae | 0.95 | GAE parameter |
| --epsilon_ppo | 0.1 | PPO loss clip range, to +/- of this value |
| --rnd_obs_norm_clip | 5.0 | Will be clipped from - to +, as in the RND paper |
| --beta_entropy | 0.001 | Entropy coeficient |
| --epsilon_greedy | 0.0 | epsilon-greedy for exploration |
| --model_policy_lr | 0.0001 | Learning rate for policy network |
| --model_rnd_predictor_lr | 0.0001 | Learning rate for RND predictor network |
| --model_value_lr | 0.0001 | Learning rate for value network |
| --model | False | Resume using .model files that are saved when training completes |
| --keep_past_x_snapshots | 10 | Delete snapshots older than this many iterations to free up disk space |
| --no_resume | False | Dont auto resume from the latest snapshot |
| --disable_progress_bar | False | Disable Chainer's progress bar when optimizing |
| --gpu | -1 | GPU ID (negative value indicates CPU) |
| --gradient_clip | 0.0 | Gradients clipped scaled to this L2 norm threshold |
| --rng_seed | 31337 | |
| --num_threads | 10 | # threads for running rollouts in parallel. Best to use 1 only for GPU |
| --target_cumulative_rewards_extrinsic | 100 | Target cumulative extrinsic reward over all trials in an interation. Training ends when this is achieved |
| --dnc | Differentiable Neural Computer. N,W,R,K, e.g. 256,64,4,0 |
Example usage:
- Terminal 1: killall -9 python; sleep 1; rm -fr /data/rl_rnd/PixelCopter-v0/experiment_1 && mkdir -p /data/rl_rnd/PixelCopter-v0/experiment_1 && python -u rl_rnd.py --game PixelCopter-v0 --gpu 0 --num_threads 1 --rnn_hidden_layers 0 --sticky_action_probability 0. --final_hidden_dim 256 --final_hidden_layers 3 --stacked_frames 10 --z_dim 1024 --gradient_clip 1. >> /data/rl_rnd/PixelCopter-v0/experiment_1/log.txt &
- Clean up previous run (if there is any). Launch the training, and log output to a file
- Terminal 1: tail -f /data/rl_rnd/PixelCopter-v0/experiment_1/log.txt
- To review useful output as training progresses
- Terminal 2: watch -n 1 "grep avg /data/rl_rnd/PixelCopter-v0/experiment_1/log.txt | tail"
- This will output the mean/std/min/max of the cumulative extrinsic rewards from of all rollouts at each iteration
- Terminal 3: python graph.py --game PixelCopter-v0
- Graph the cumulative extrinsic rewards from of all rollouts at each iteration. It refreshes as new results become available