YouTube Comment Sentiment Analysis
- Firstly chose to extract comments without replies so that they don't affect the overall sentiment of the general comment section & due to this also, then number of comments on youtube video differs as from what we extracted because we are not extracting the replies.
- Write the code to extract the comment out of video with the help of YouTube data API v3 & run it.
- Verify the order of comments from the youtube video after sorting it by newest first.
- As a result, it extracted 25665 comments in 137 seconds at a rate of 188 comments per second.
- Download the data as .csv & save it on your google drive.
- Mount the google drive on the google colab & continue coding with the extracted dataset further.
First we shuffle the dataset. The most prominent step while building any machine learning model is data preprocessing as it will directly affect the result of your model. The more you pre-process the data, the more accurate your model performs
- The dataset is unlabelled because of using API, you can only extract the comments but not the polarity.
- Polarity is something that can identify the emotion of a particular sentence by using the words present in that.
- This can be done using the TextBlob module of python. The code will demonstrate the finding of the polarity of all the comments.
- As TextBlob find the polarity score, now using threshold concept we can extract a new feature, i.e., sentiment of each comment either positive (1) or negative (-1).
- Now moving further with the data preprocessing step, lowercasing the words in every comment.
- It becomes important as it makes the data more effective to produce a better result but if not converted then the system treats them as two different words which might be redundant information and led to producing different results than the desired one.
- It contains words of less importance, i.e., commonly used words like is, am, the, are, a, etc. as they don’t add any fruitful information that is required for analysis.
- So, by removing these kinds of words, our data become more concise as having fewer features but significant.
- The task of stopwords removal is done using the nltk module as it provides a list of stopwords in different languages.
- As of now, we are working with the one dataset, but for making predictions of sentiment analysis or can say that for testing the accuracy of the model trained, a test data set/validation data set would be required.
- So, splitting the dataset into training data and test data using the train_test_split module of scikit learn.
- It will split the dataset into two parts in the required proportion.
- So there will be two datasets available i.e (X_train, y_train) & (X_test, y_test).
- Now we extract features out of text data, i.e. conversion to integer values or floating-point values as a machine learning model can’t be applied directly to the text data.
- Use the CountVectorizer module by scikit learn, which will create a vocabulary from the text data, as it will store the count of each word every time it appears in the text.
- Tokenization: Tokenize the text into words,
- Vocabulary: Build vocabulary with all the words present in the text/document,
- Encoding: Encode the entire document creating a vector with the same length as of vocabulary.
Now we have got the pre-processed data consisting of training (tf_train, y_train) and test (tf_test,y_test) dataset. So the next step is the selection of an appropriate machine learning algorithm for classification, i.e., Logistic Regression.
- It’s a predictive modeling algorithm for the classification where there is a labeled dataset with the categorical target variable. It falls into the category of the supervised machine learning algorithm.
- It will help in predicting the probability of outcomes i.e. binary classification or multi-classification. Examples of logistic regression include spam classifier, customer churn prediction, tumor prediction, etc.
- These are some of the famous examples of the same, while we can apply the same for other cases as in this instance of sentiment analysis, where there are two classes to classify i.e. either positive (1) or negative (-1).
- The scikit learn is utilized to implement logistic regression for the sentiment classification.
- Now after the model training, the accuracy score on the training dataset is 96.34 %, which implies your model is predicting 96.34 % accurate results, which is quite good. In the next step, we can discover the accuracy score on the test dataset,
- The accuracy of the model on the test dataset is 94.70 %, which means the model is predicting 94.70 % accurate results on the unseen dataset.
- Now we make predictions on the test dataset by using a model trained above.
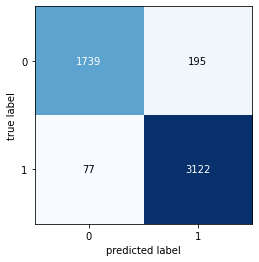
It helps us to know about the performance of our model on the test dataset where we already have the output of the same.
This is another metric that will provide the quality of predictions by finding precision, recall, f1 score.
- It gives a better measure of classification events than the accuracy metric. It is equal to the harmonic mean of precision & recall.
- Another advantage of this is, it provides a more precise evaluation than accuracy in imbalance class distribution but here in our case we found out F1 score to be 0.9428 which is less than the accuracy because our model was not imbalanced, as we had 16075 negatives (-1)s & 9590 positives (1)s.
- A machine learning model has been trained for the sentiment analysis of the youtube comments followed by the pre-processing of the dataset. Preprocessing includes data labeling, lowercasing of the text, stopwords removal, data splitting, feature extraction.
- For the sentiment classification into two classes positive and negative, Logistic Regression, machine learning classification algorithm has been used & achieved an accuracy score of 96.34 % on training data and 94.70 % on test data, and the F1 score is 0.9428.
Lazy loading, which is the practice of delaying load or initialization of resources or objects until they're actually needed to improve performance and save system resources.
- Pagination is used in some form in almost every web application to divide returned data and display it on multiple pages within one web page.
- Pagination also includes the logic of preparing and displaying the links to the various pages. Pagination can be handled client-side or server-side.
- Pagination is a strategy employed when querying any dataset that holds more than just a few hundred records. Thanks to pagination, we can split our large dataset into chunks ( or pages ) that we can gradually fetch and display to the user, thus reducing the load on the database. Pagination also solves a lot of performance issues both on the client and server-side! Without pagination, you'd have to load the entire chat history only to read the latest message sent to you.
- These days, pagination has almost become a necessity since every application is very likely to deal with large amounts of data. This data could be anything from user-generated content, content added by administrators or editors, or automatically generated audits and logs. As soon as your list grows to more than a few thousand items, your database will take too long to resolve each request and your front-end's speed and accessibility will suffer. As for your users, they will experience frequent buffers loaded onto their screens.
- In extracting comments out of YouTube.
- Language barrier, moved on to some english specific vids.
- One drawback: was not able to take very popular vids with comments > 60000 as then it would take the google script to execute for more than 6 minutes which automatically terminates it.
VIDEO ANALYSED: https://www.youtube.com/watch?v=DUrBIxB1q0o