Pearson PDF Downloader is a utility to download ebook from https://elibrary.in.pearson.com/ considering you have the book_id.
Install all the requirements
pip install -r requirements.txt
The steps to get pearson book_id is shown below:
- Login to https://elibrary.in.pearson.com/ with your credentials.
- Search and open the book you want to download
- Get
book_idandpage_countusing inspect element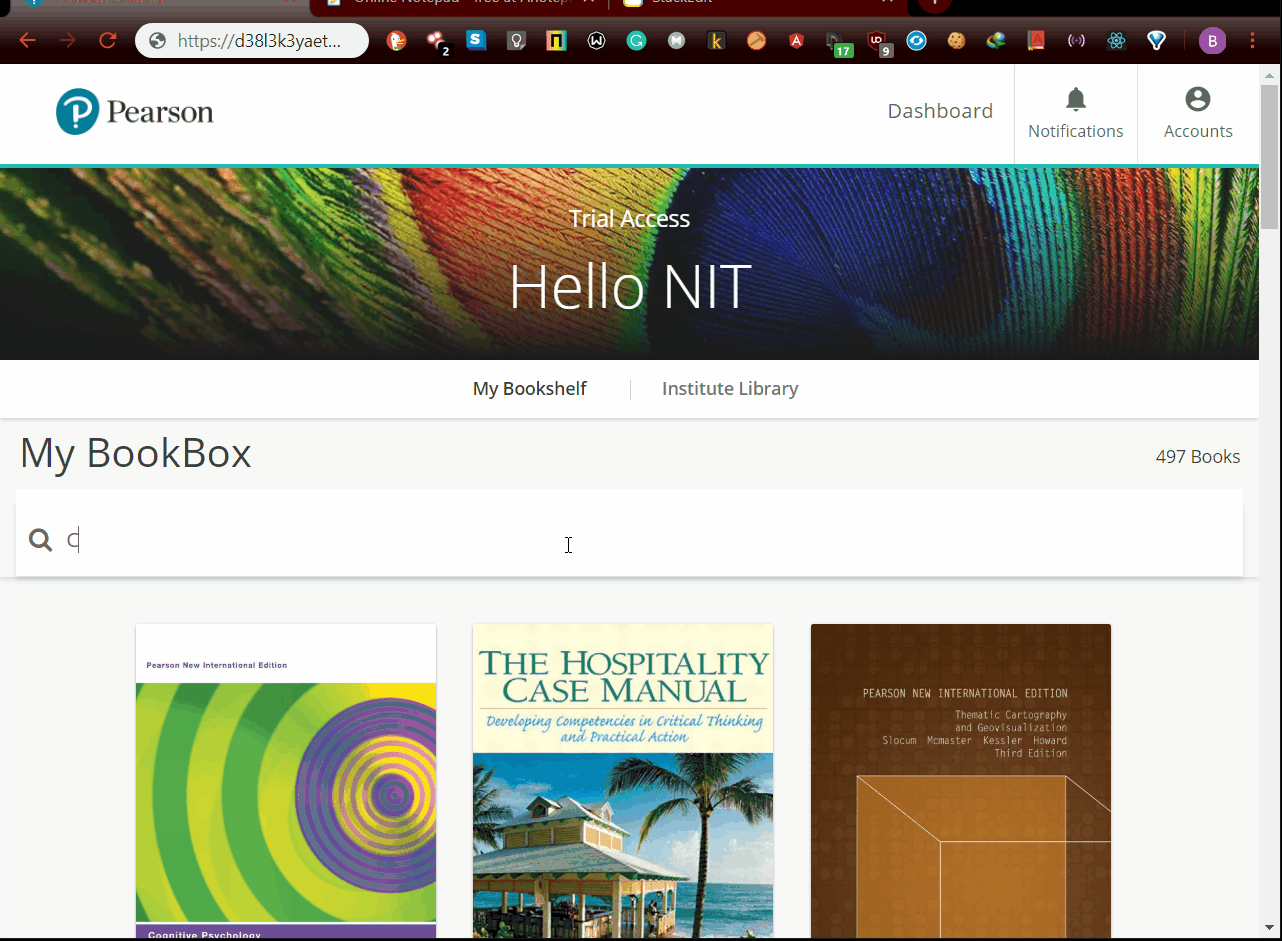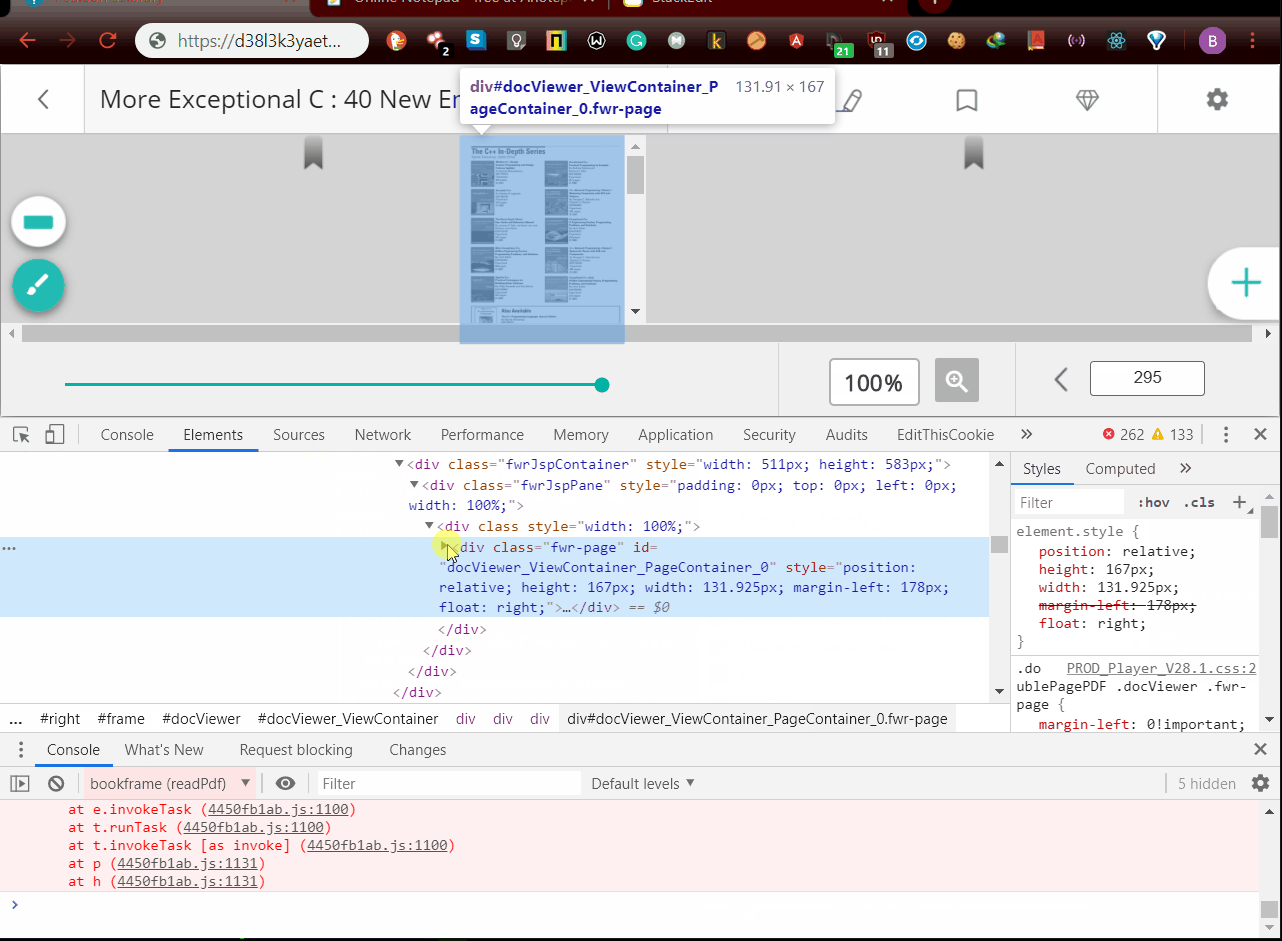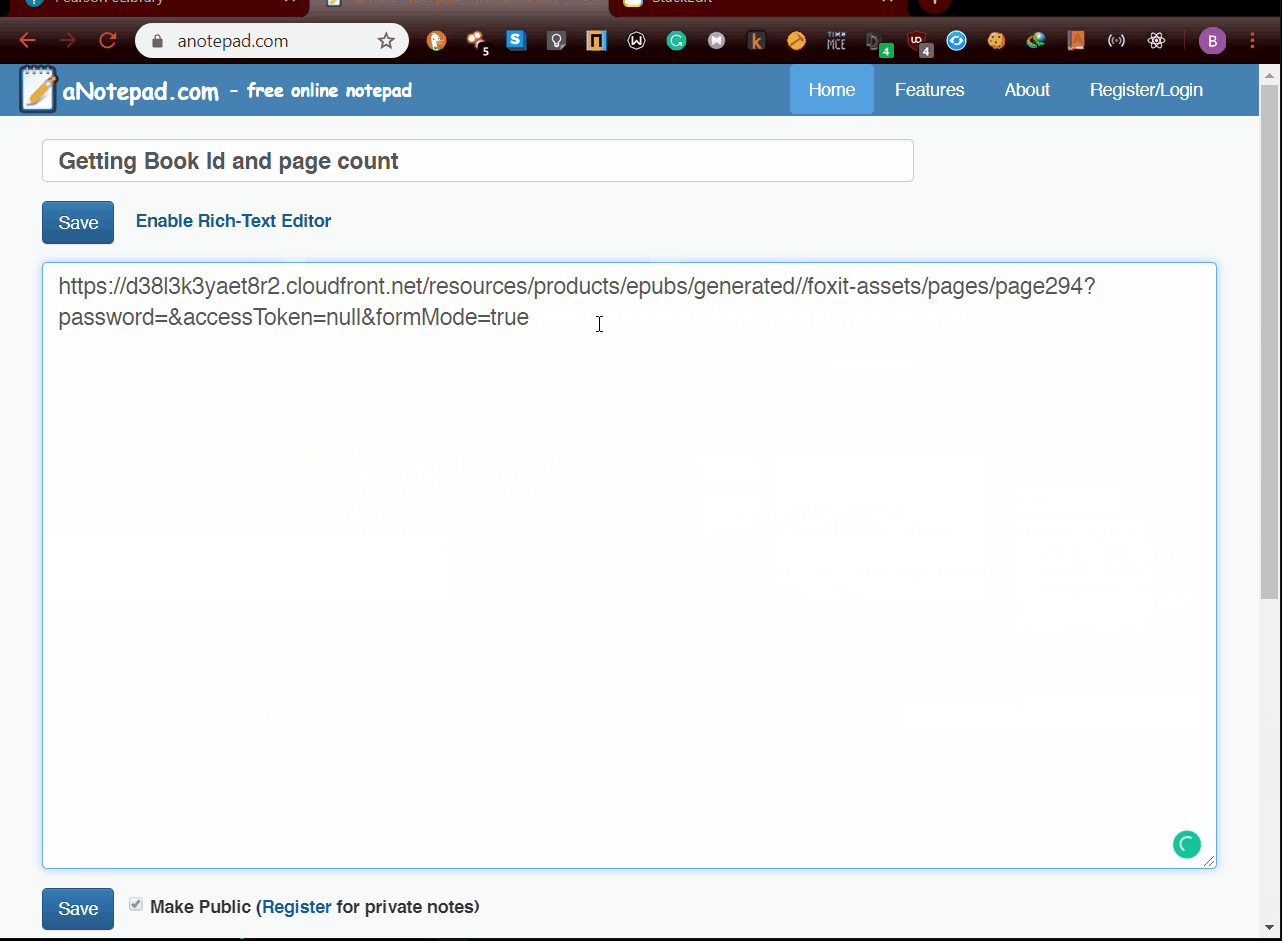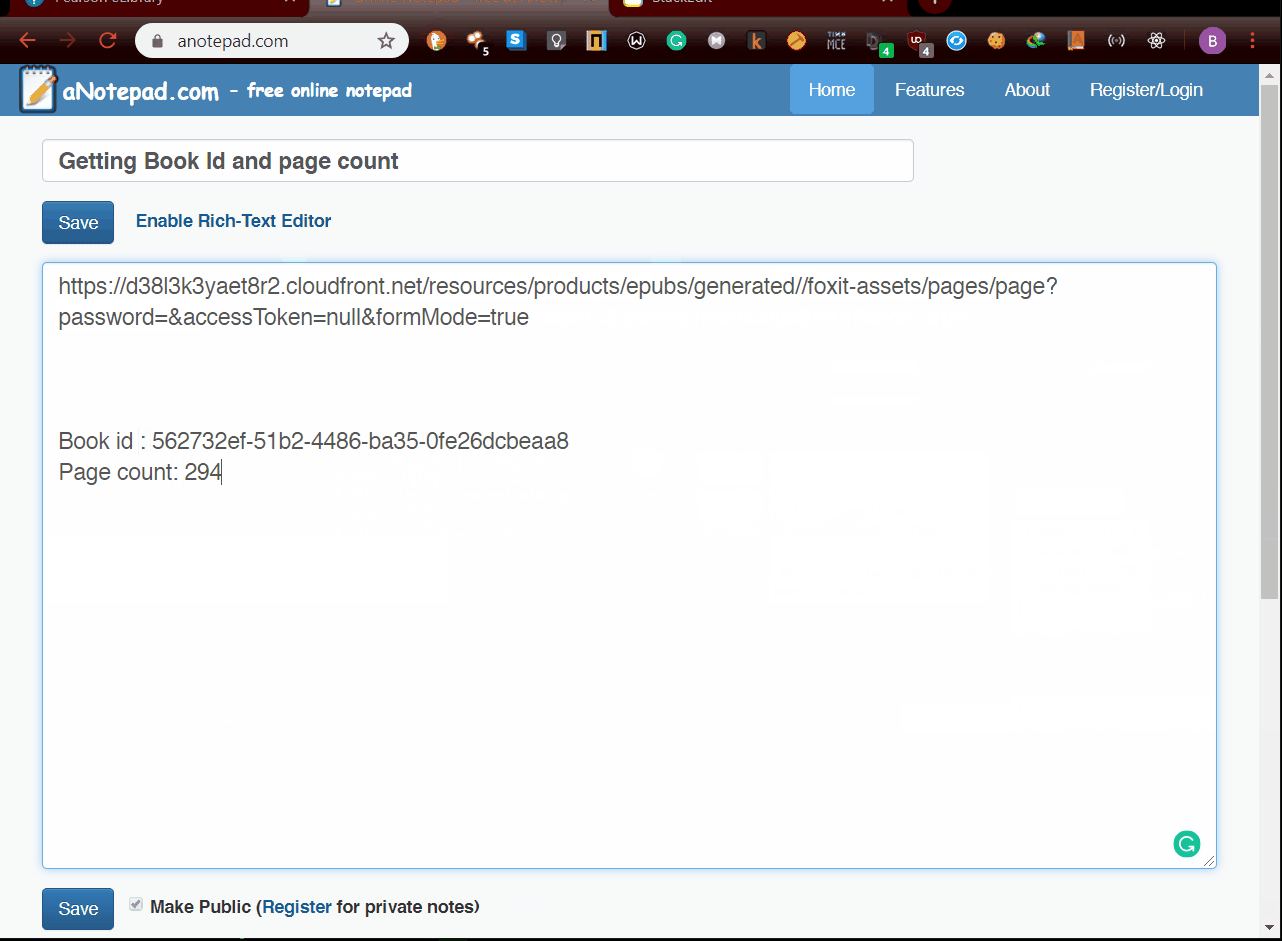 After getting book_id and page_count you can download the pdf running.
python pdl.py
After getting book_id and page_count you can download the pdf running.
python pdl.py
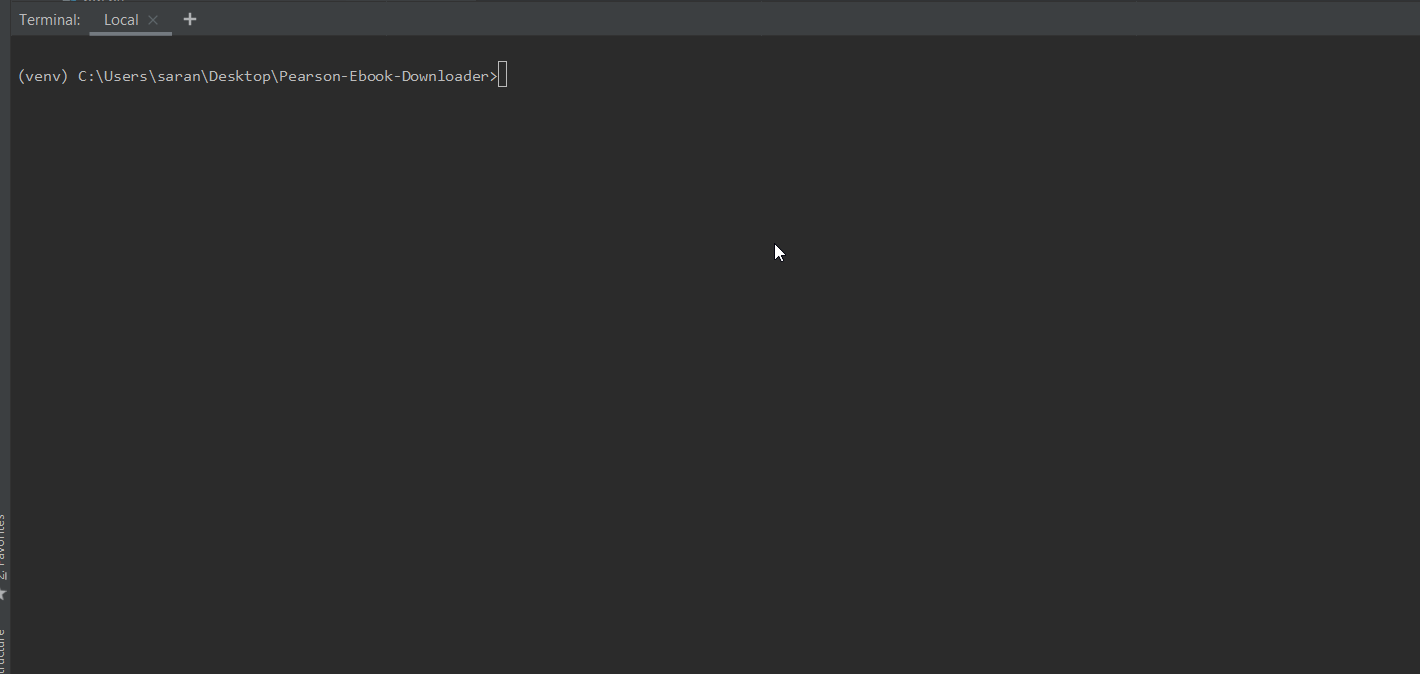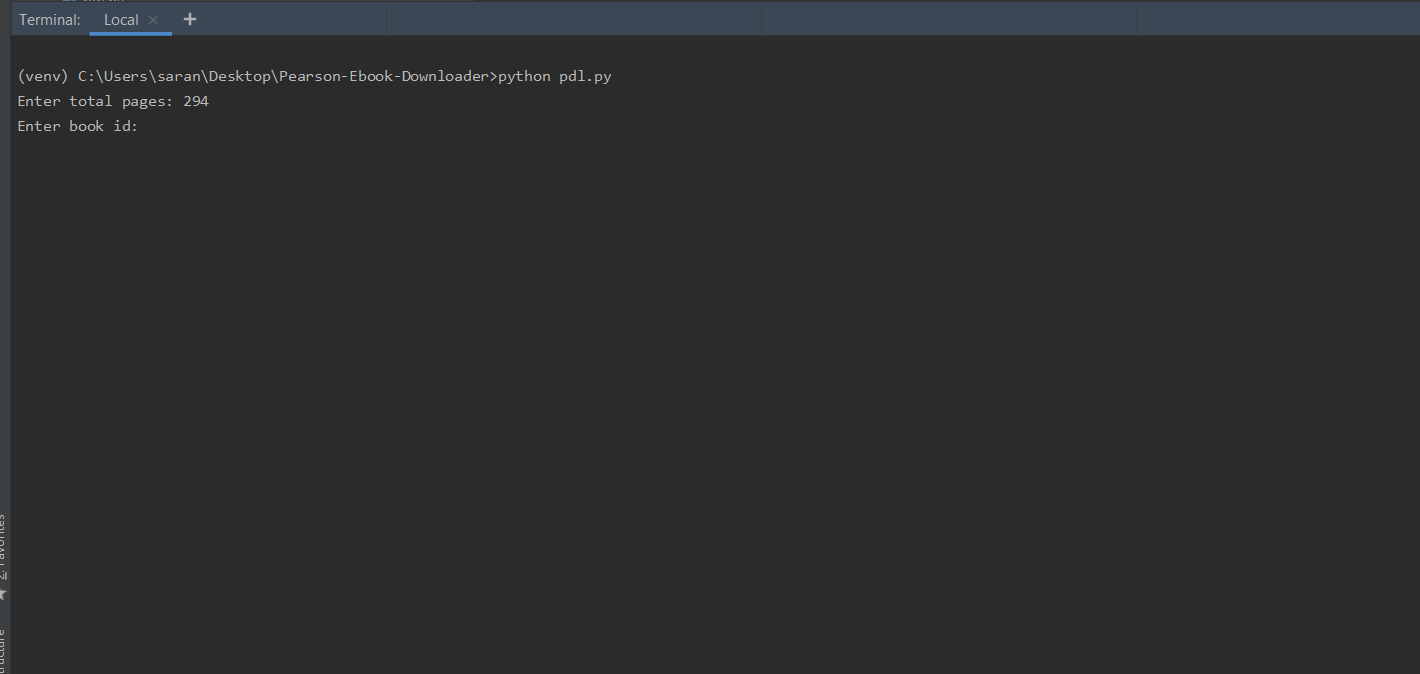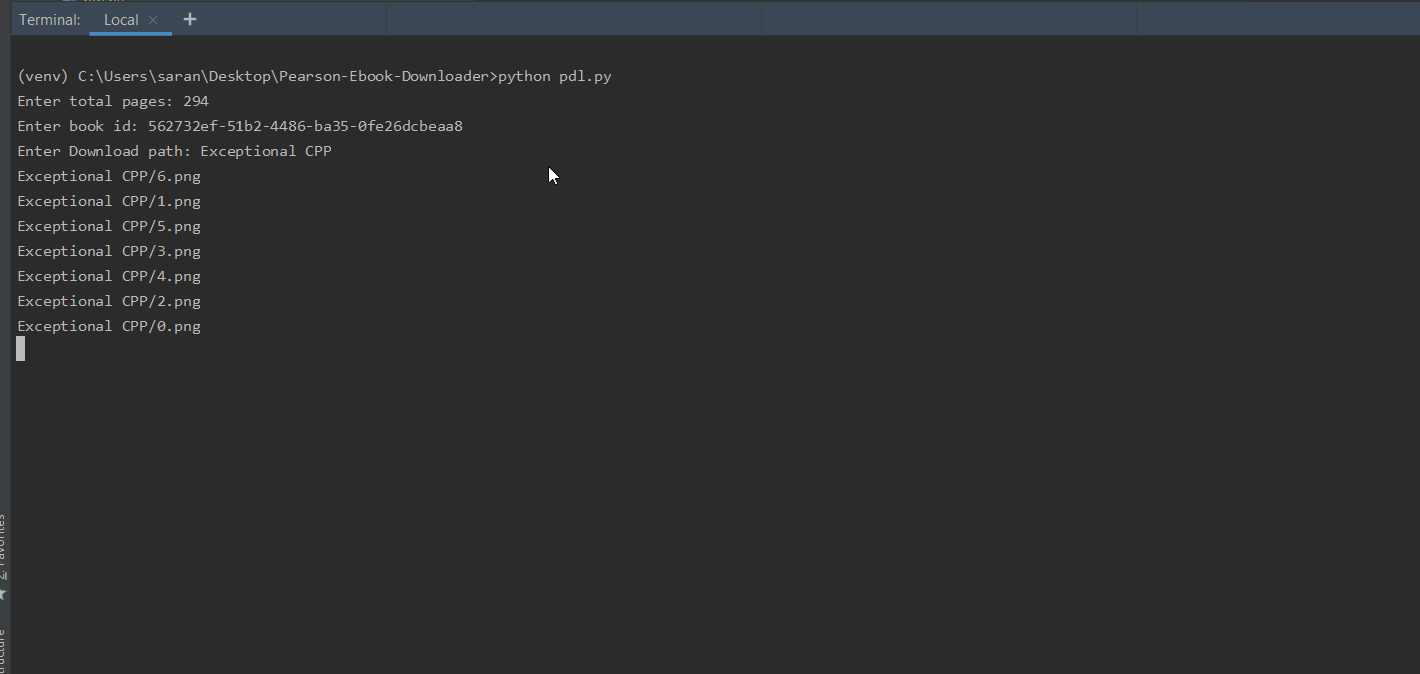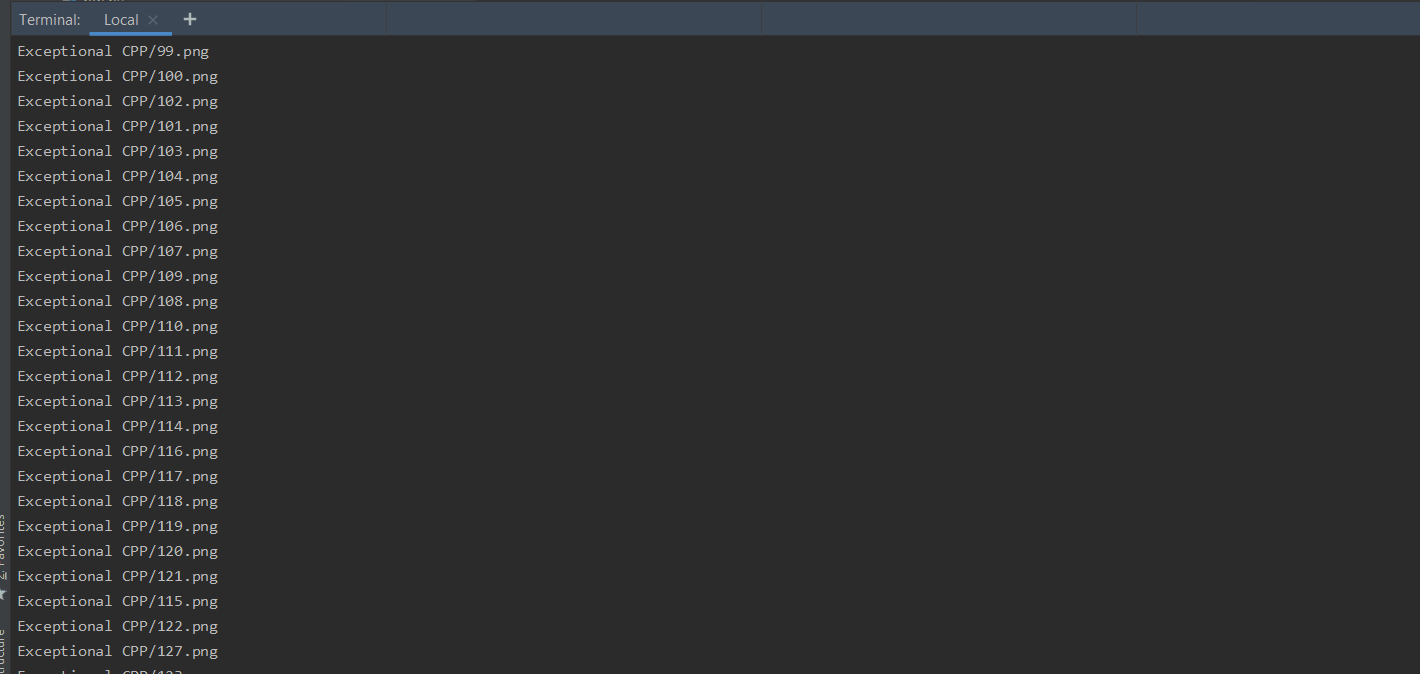 The ebooks are downloaded as pdf.
The ebooks are downloaded as pdf.
Right now, I'm only able to download image as pdfs which is larger in size. I was able to grab the zip file that contains the true pdf for the book which is unfortunately password protected.
- Concurrency
- Convert images to pdf
- Downloading true pdf