SSD is simple to use but inconvenient to modify codes. In this repo, I list all the files and codes needed to be changed when using a new dataset.
data/VOC0712/create_data.sh
data/VOC0712/create_list.sh
data/VOC0712/labelmap_melon.prototxt
examples/ssd/score_ssd_pascal.py
examples/ssd/ssd_pascal.py
Following the original instructions to compile SSD. Make sure that you can run it successfully.
For convenience, please follow the VOC dataset format to make the new dataset. Click here to download the MELON dataset I made for this repo.
cd ~/data/VOCdevkit
mkdir MELON
Put all training/test images in MELON/JPEGImages
Put all xml-format labels in MELON/Annotations
Add all the training/val samples in MELON/ImageSets/Main/trainval.txt
Add all the test samples in MELON/ImageSets/Main/test.txt
The final directory structure is like this:
VOCdevkit
├── MELON
│ ├── Annotations
│ ├── ImageSets
│ │ └── Main
│ └── JPEGImages
├── VOC2007
│ ├── Annotations
│ ├── ImageSets
│ │ ├── Layout
│ │ ├── Main
│ │ └── Segmentation
│ ├── JPEGImages
│ ├── SegmentationClass
│ └── SegmentationObject
└── VOC2012
├── Annotations
├── ImageSets
│ ├── Action
│ ├── Layout
│ ├── Main
│ └── Segmentation
├── JPEGImages
├── SegmentationClass
└── SegmentationObject
SSD provides two scripts to convert any VOC-format dataset to LMDB database. But before doing this, we need to take some efforts to modify necessary codes for processing our new dataset.
First cd to the SSD root directory. Then,
mkdir data/MELON
cp data/VOC0712/* data/MELON/
Next, modify the data/MELON/create_list.sh. In this script, replace the extension of image files with yours (e.g., png).
In the second loop of the script, replace the keywords VOC2007 and VOC2012 with MELON since we have only one dataset.
Run data/MELON/create_list.sh to generate test_name_size.txt, test.txt, and trainval.txt in data/MELON/.
After this, rename the labelmap_voc.prototxt (optional).
mv data/MELON/labelmap_voc.prototxt data/MELON/labelmap_melon.prototxt
Then edit it,
vim data/MELON/labelmap_melon.prototxt
In this file, the first block points to the background. So, don't change it. For the rest block, change their class names accordingly.
For the second script data/MELON/create_data.sh,
replace the keyword dataset_name with MELON, and labelmap_voc.prototxt with labelmap_melon.prototxt.
Now the new dataset is ready to be made. Simply run data/MELON/create_data.sh.
This will create a LMDB database in ~/data/VOCdevkit and make a soft link in examples/MELON/.
There are two python scripts for training and test respectively.
In examples/ssd/ssd_pascal.py.
Change train_data and test_data to our new dataset.
Replace all the keywords related to voc with melon.
Change num_classes. Don't forget to plus one for the background.
Set gpus and batch_size if needed.
Modify the num_test_image (important!) and test_batch_size.
All the modifications in examples/ssd/score_ssd_pascal.py are the same.
Run python examples/ssd/ssd_pascal.py to train a new model.
Use python examples/ssd/score_ssd_pascal.py to evaluate the model.
Below is the original content.

By Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg.
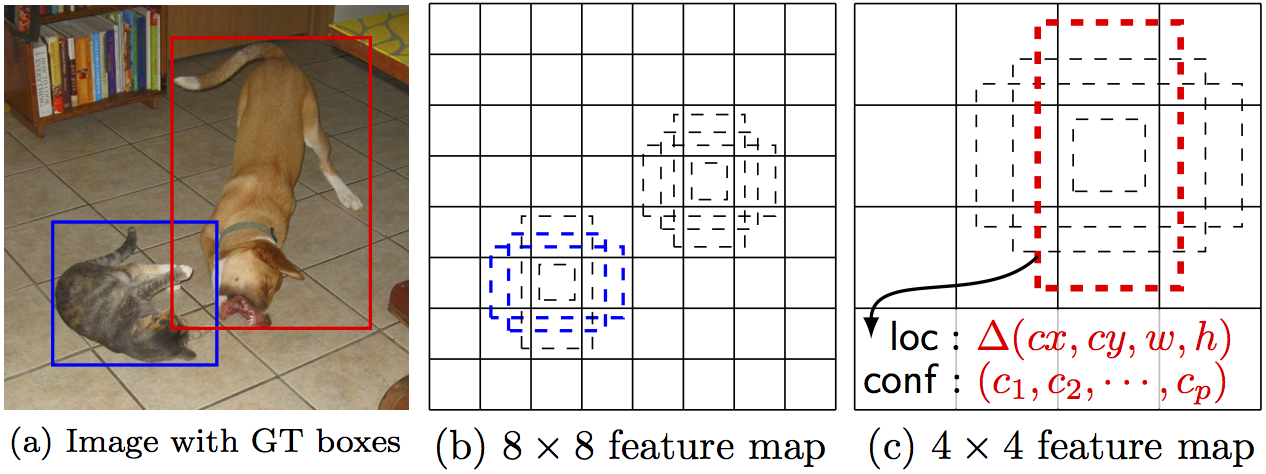
SSD is an unified framework for object detection with a single network. You can use the code to train/evaluate a network for object detection task. For more details, please refer to our arXiv paper and our slide.
| System | VOC2007 test mAP | FPS (Titan X) | Number of Boxes | Input resolution |
|---|---|---|---|---|
| Faster R-CNN (VGG16) | 73.2 | 7 | ~6000 | ~1000 x 600 |
| YOLO (customized) | 63.4 | 45 | 98 | 448 x 448 |
| SSD300* (VGG16) | 77.2 | 46 | 8732 | 300 x 300 |
| SSD512* (VGG16) | 79.8 | 19 | 24564 | 512 x 512 |

Note: SSD300* and SSD512* are the latest models. Current code should reproduce these results.
Please cite SSD in your publications if it helps your research:
@inproceedings{liu2016ssd,
title = {{SSD}: Single Shot MultiBox Detector},
author = {Liu, Wei and Anguelov, Dragomir and Erhan, Dumitru and Szegedy, Christian and Reed, Scott and Fu, Cheng-Yang and Berg, Alexander C.},
booktitle = {ECCV},
year = {2016}
}
- Get the code. We will call the directory that you cloned Caffe into
$CAFFE_ROOT
git clone https://github.com/weiliu89/caffe.git
cd caffe
git checkout ssd- Build the code. Please follow Caffe instruction to install all necessary packages and build it.
# Modify Makefile.config according to your Caffe installation.
cp Makefile.config.example Makefile.config
make -j8
# Make sure to include $CAFFE_ROOT/python to your PYTHONPATH.
make py
make test -j8
# (Optional)
make runtest -j8-
Download fully convolutional reduced (atrous) VGGNet. By default, we assume the model is stored in
$CAFFE_ROOT/models/VGGNet/ -
Download VOC2007 and VOC2012 dataset. By default, we assume the data is stored in
$HOME/data/
# Download the data.
cd $HOME/data
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
# Extract the data.
tar -xvf VOCtrainval_11-May-2012.tar
tar -xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar- Create the LMDB file.
cd $CAFFE_ROOT
# Create the trainval.txt, test.txt, and test_name_size.txt in data/VOC0712/
./data/VOC0712/create_list.sh
# You can modify the parameters in create_data.sh if needed.
# It will create lmdb files for trainval and test with encoded original image:
# - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_trainval_lmdb
# - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_test_lmdb
# and make soft links at examples/VOC0712/
./data/VOC0712/create_data.sh- Train your model and evaluate the model on the fly.
# It will create model definition files and save snapshot models in:
# - $CAFFE_ROOT/models/VGGNet/VOC0712/SSD_300x300/
# and job file, log file, and the python script in:
# - $CAFFE_ROOT/jobs/VGGNet/VOC0712/SSD_300x300/
# and save temporary evaluation results in:
# - $HOME/data/VOCdevkit/results/VOC2007/SSD_300x300/
# It should reach 77.* mAP at 120k iterations.
python examples/ssd/ssd_pascal.pyIf you don't have time to train your model, you can download a pre-trained model at here.
- Evaluate the most recent snapshot.
# If you would like to test a model you trained, you can do:
python examples/ssd/score_ssd_pascal.py- Test your model using a webcam. Note: press esc to stop.
# If you would like to attach a webcam to a model you trained, you can do:
python examples/ssd/ssd_pascal_webcam.pyHere is a demo video of running a SSD500 model trained on MSCOCO dataset.
-
Check out
examples/ssd_detect.ipynborexamples/ssd/ssd_detect.cppon how to detect objects using a SSD model. Check outexamples/ssd/plot_detections.pyon how to plot detection results output by ssd_detect.cpp. -
To train on other dataset, please refer to data/OTHERDATASET for more details. We currently add support for COCO and ILSVRC2016. We recommend using
examples/ssd.ipynbto check whether the new dataset is prepared correctly.
We have provided the latest models that are trained from different datasets. To help reproduce the results in Table 6, most models contain a pretrained .caffemodel file, many .prototxt files, and python scripts.
-
PASCAL VOC models:
-
COCO models:
-
ILSVRC models:
[1]We use examples/convert_model.ipynb to extract a VOC model from a pretrained COCO model.