xVASynth is a machine learning based speech synthesis app, using voices from characters/voice sets from video games.
Steam: https://store.steampowered.com/app/1765720/xVASynth_v2
HuggingFace 🤗 Space online demo: https://huggingface.co/spaces/Pendrokar/xVASynth
New: xVATrainer, for training your own custom voices: https://github.com/DanRuta/xva-trainer

This is an Electron UI wrapped around inference of FastPitch models trained on voice data from video games. The app serves as a framework, which loads and uses whichever models are given to it. As such, the app does nothing by itself, and models need to be installed. Models which have a corresponding asset file will be loaded in their respective game/category. Anything else gets loaded in the "Other" category.
The main benefit of this tool is allowing mod creators to generate new voice lines for third party game modifications (mods). There are other uses, such as creating machinima, and just generally having fun with familiar voices.
Join chat on Discord here: https://discord.gg/nv7c6E2TzV
Where possible, make sure you download the app from the Nexusmods websites (Files tab, "Main Files" section). There the compiled version will be the most up-to-date.
The base application can be downloaded and placed anywhere. Aim to install it onto an SSD, if you have the space, to reduce voice set loading time. To install voice sets, you can drop the files into the respective game directory: xVASynth/resources/app/models/<game>/
Watch the above video for a summary of this section.
To start, download the latest release, double click the xVASynth.exe file, and make sure to click Allow, if Windows asks for permission to run the python server script (this is used internally). Alternatively, check out the Development section, to see how to run the non-packaged dev code.
Once the app is up and running, select the voice set category (the game) from the top left dropdown, then click a specific voice set.
A list of already synthesized audio files for that voice set, if any, is displayed. For synthesis, click the Load model button. This may take a minute, on a slow machine.
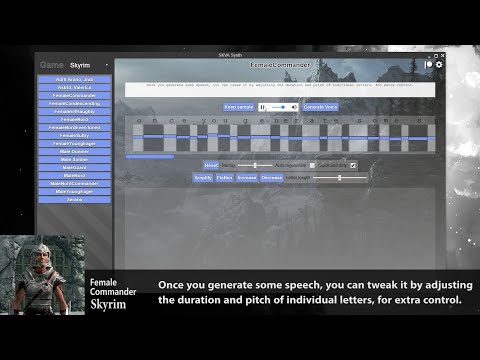
Once finished, type your text in the text area and click the Generate Voice button. Once generated, you will be shown a preview of the output. Click the Keep sample button to save to file, or click the Generate Voice after making ammends to the text input, to discard it and re-generate.
You can adjust the pitch, durations, and energy of individual letters by moving the letter sliders up and down, or by using the tools in the toolbars below.
In the list of audio files, you can preview, re-name, click to open the containing folder, or delete each one.
If the required CUDA dependencies are installed on your system, you can enable GPU inference by switching the toggle in the settings menu (click the setting cog at the top right).
- Install Node modules with
npm install. - Create a Python 3.9 virtual environment with
python -m venv .venv. - Activate the virtual environment.
- Install Python dependencies from one of the
requirements_*.txtfiles. For example,pip install -r requirements_cpu.txt. - Run the application with
npm start.
The app uses both JavaScript (Electron, UI) and Python code (FastPitch Model). As the python script needs to remain running alongside the app, and receive input, communication is done via an HTTP server, with the JavaScript code sending localhost requests, at port 8008. During development, the python source is used. In production, the compiled python is used.
First, run the scripts in package.json to create the electron distributables.
Second, use pyinstaller to compile the python. pip install pyinstaller and run pyinstaller -F server.spec. Discard the build folder, and move the server folder (in dist) into release-builds/xVASynth-win32-x64/resources/app, and rename it to cpython. Distribute the contents in xVASynth-win32-x64 and run app through xVASynth.exe.
Run the distributed app once and check the server.log file for any problems, remove any unnecessary files before distribution.
Make sure you remove your environment folder, if it is copied over to the distributed output.
Though, if you're just tweaking small things in JS/HTML/CSS, it may be easier to just edit/copy over the files into an existing packaged distributable. There's no code obfuscation or anything like that in place.
A large number of models have been trained for this app. They are publicly hosted on the nexus.com website, on the game page respective to the game the voice belongs to.
Future plans are currently to continue training models for more voices, with plenty more remaining.