为什么写这个博客,主要是CSDN上有几个比较热的微博爬虫,基本在今年都挂掉了用不了。比如 《微博爬虫,每日百万级数据》,博主写的比较全,不过因为今年微博查的更严了,所以每日百万级的基本不太可能(除非有很多账号,然而淘宝上的微博账号也涨价了,要达到这么大的数据量都够买一块RTX2080了)。
所以基于一些爬虫框架,这篇博客给出的是更加简单易懂的轻量级微博爬虫,对于学校实验、数据测试、NLP模型训练是大概够用的,原文见 我的博客:https://blog.csdn.net/qq_39521554/article/details/87940001
*说明:这个轻量级爬虫每次爬取内容大概在每个ID100条左右(可以设置的更大),只需要建立超过一个较大的微博ID列表(这个表可以自己爬或者网上找)然后随机选取一部分用户进行爬取即可。同一IP每日建议不超过10万条,以免被封。
此外有条件的可以用分布式爬虫扩展一下,如果对于数据量需求不高的则此版本即可。
-本项目Python版本为Python3.6
-selenium
-BeautifulSoup v4
git clone git@github.com:Y1ran/Weibo_Light_Spyder_2019.git cd WeiboSpider pip install -r requirements.txt
首先,在准备开始爬虫之前,得想好要爬取哪个网址。新浪微博的网址分为网页端和手机端两个,大部分爬取微博数据都会选择爬取手机端,因为对比起来,手机端基本上包括了所有你要的数据,并且手机端相对于PC端是轻量级的。 下面是GUCCI的手机端和PC端的网页展示。
定好爬取微博手机端数据之后,接下来就该模拟登陆了。 模拟登陆的网址和登陆的网页下面的样子
在登录之后可以进入想要爬取的商户信息,因为每个商户的微博量不一样,因此对应的微博页码也不一样,这里首先将商户的微博页码爬下来。与此同时,将那些公用信息爬取下来,比如用户uid,用户名称,微博数量,关注人数,粉丝数目
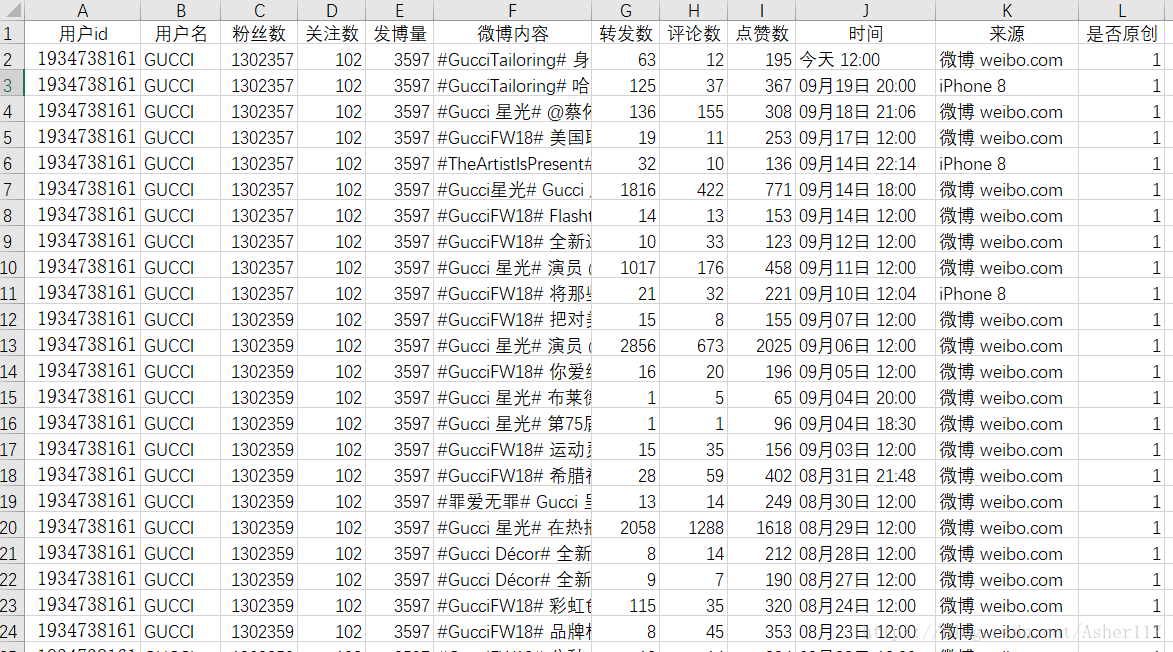
在得到最大页码之后,直接通过循环来爬取每一页数据。抓取的数据包括,微博内容,转发数量,评论数量,点赞数量,发微博的时间,微博来源,以及是原创还是转发。
在得到所有数据之后,可以写到csv文件,或者excel