![]()
![]()
DataTunerX (DTX) is designed as a cloud-native solution integrated with distributed computing frameworks. Leveraging scalable GPU resources, it's a platform built for efficient fine-tuning LLMs with a focus on practical utility. Its core strength lies in facilitating batch fine-tuning tasks, enabling users to conduct multiple tasks concurrently within a single experiment. DTX encompasses essential capabilities such as dataset management, hyperparameter control, fine-tuning workflows, model management, model evaluation, model comparison inference, and a modular plugin system.
Technology stack:
DTX is built on cloud-native principles, employing a variety of Operators that consist of distinct Custom Resource Definitions (CRDs) and Controller logic. Developed primarily in Go, the implementation utilizes the operator-sdk toolkit. Operating within a Kubernetes (K8s) environment, DTX relies on the operator pattern for CRD development and management. Furthermore, DTX integrates with kuberay to harness distributed execution and inference capabilities.
Status:
v0.1.0 - Early development phase. CHANGELOG for details on recent updates.
Quick Demo & More Documentation:
- Demo

- Documentation (COMING SOON)
Screenshot:
DTX empowers users with a robust set of features designed for efficient fine-tuning of large language models. Dive into the capabilities that make DTX a versatile platform:
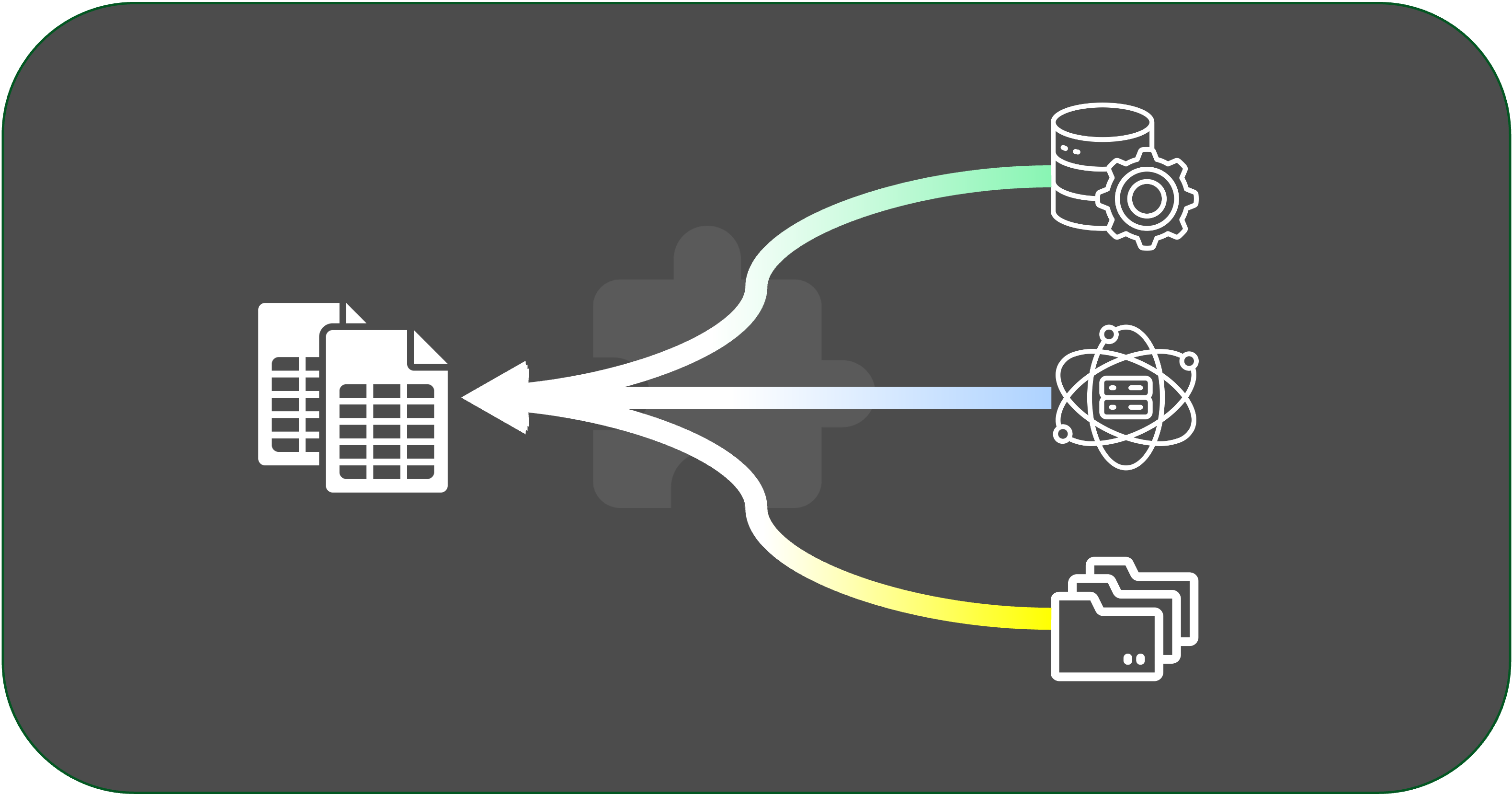
Effortlessly manage datasets by supporting both S3 protocol (http is coming) and local dataset uploads. Datasets are organized with splits such as test, validation, and training. Additionally, feature mapping enhances flexibility for fine-tuning jobs.
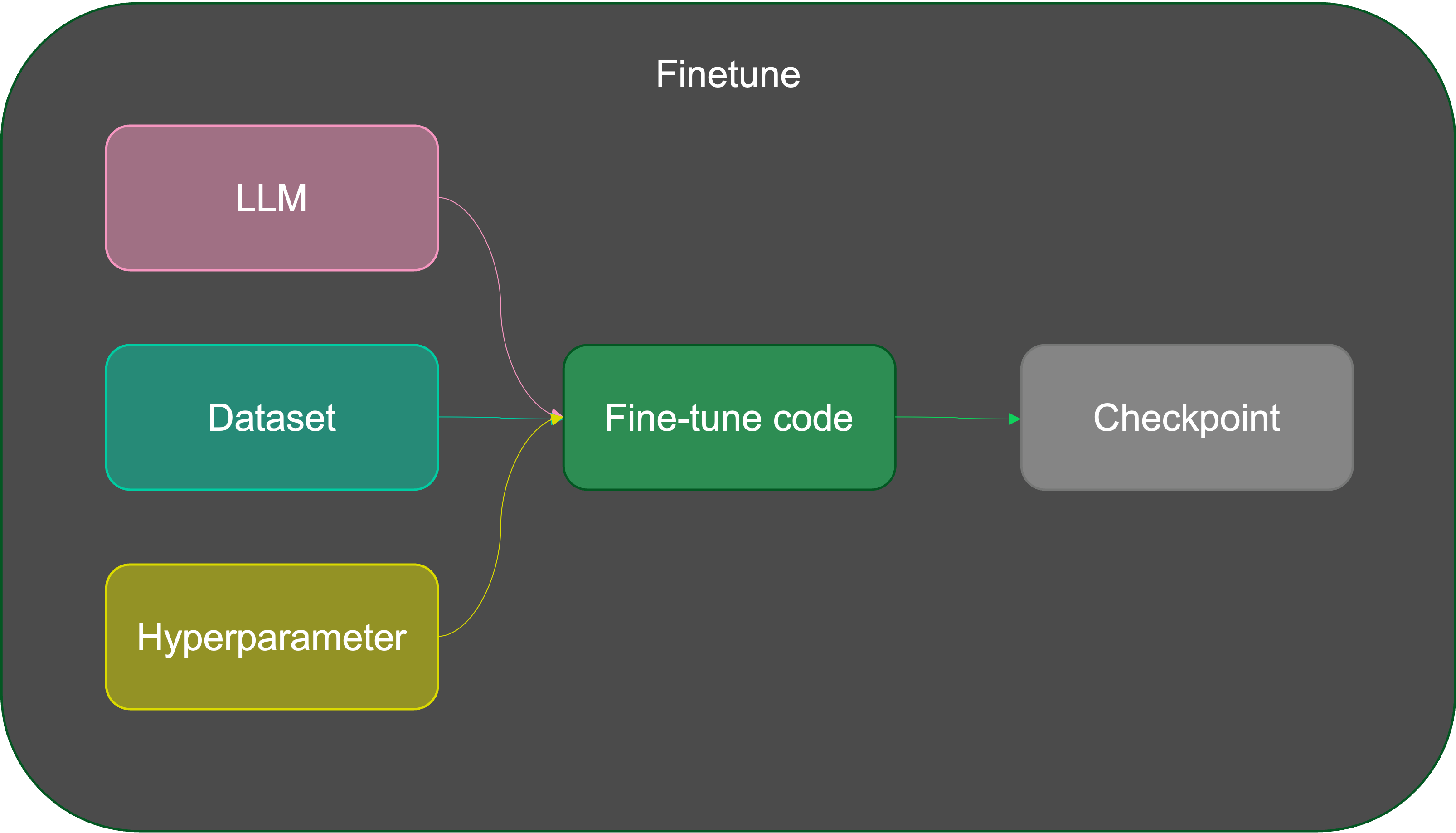
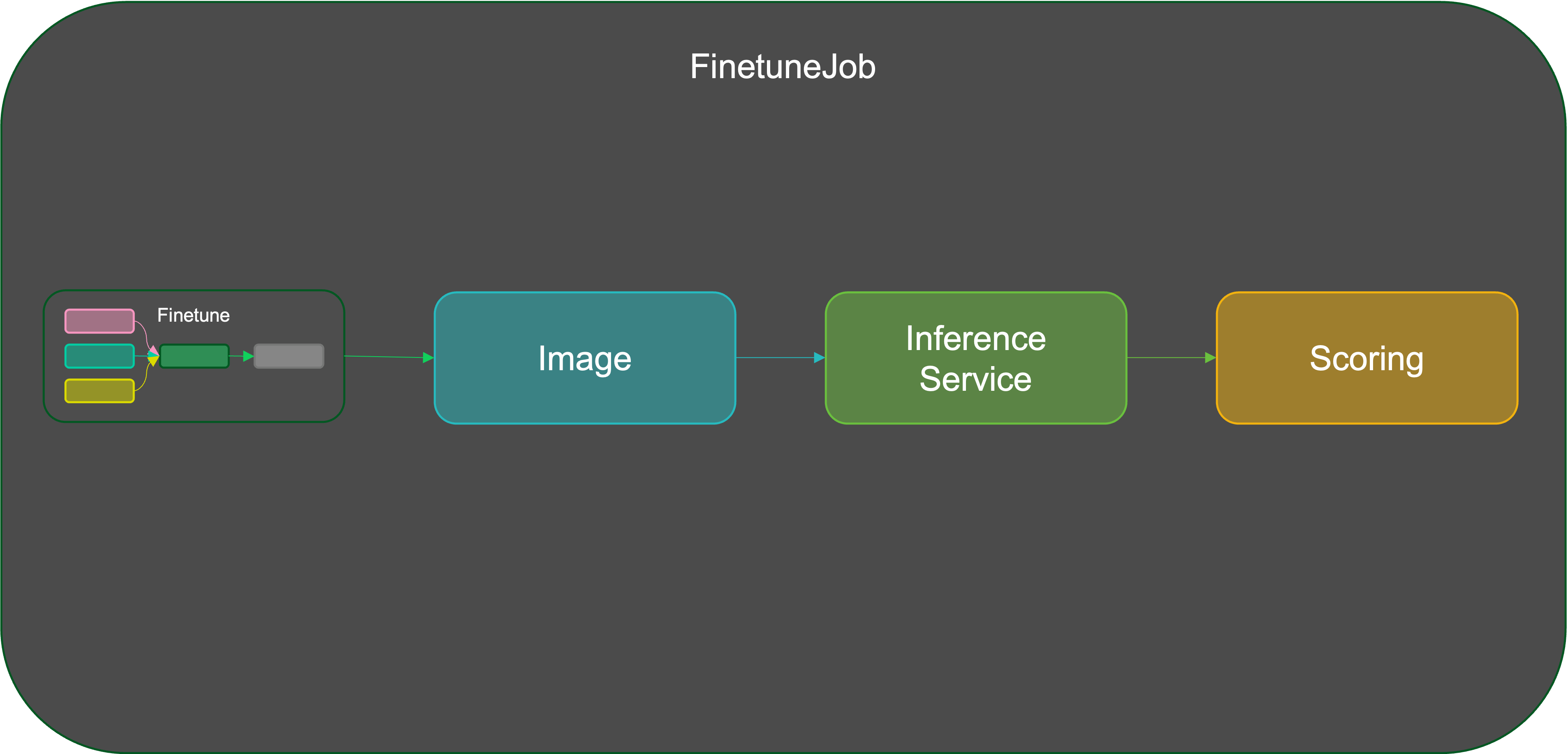
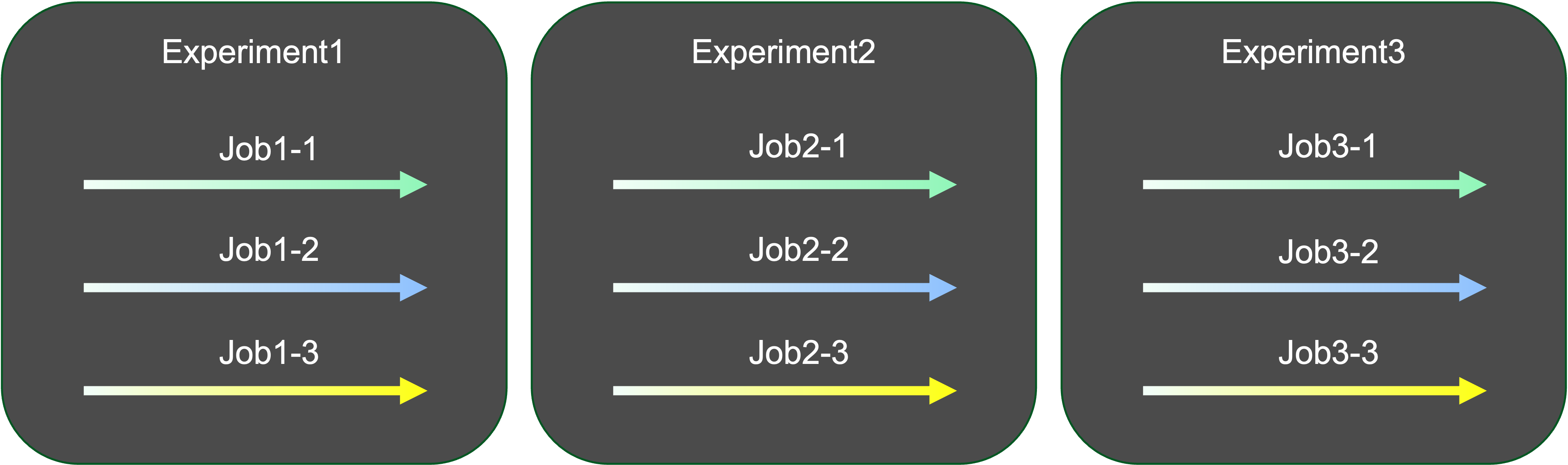
Conduct fine-tuning experiments by creating multiple fine-tuning jobs. Each job can employ different llms, datasets, and hyperparameters. Evaluate the fine-tuned models uniformly through the experiment's evaluation unit to identify the fine-tuning results.
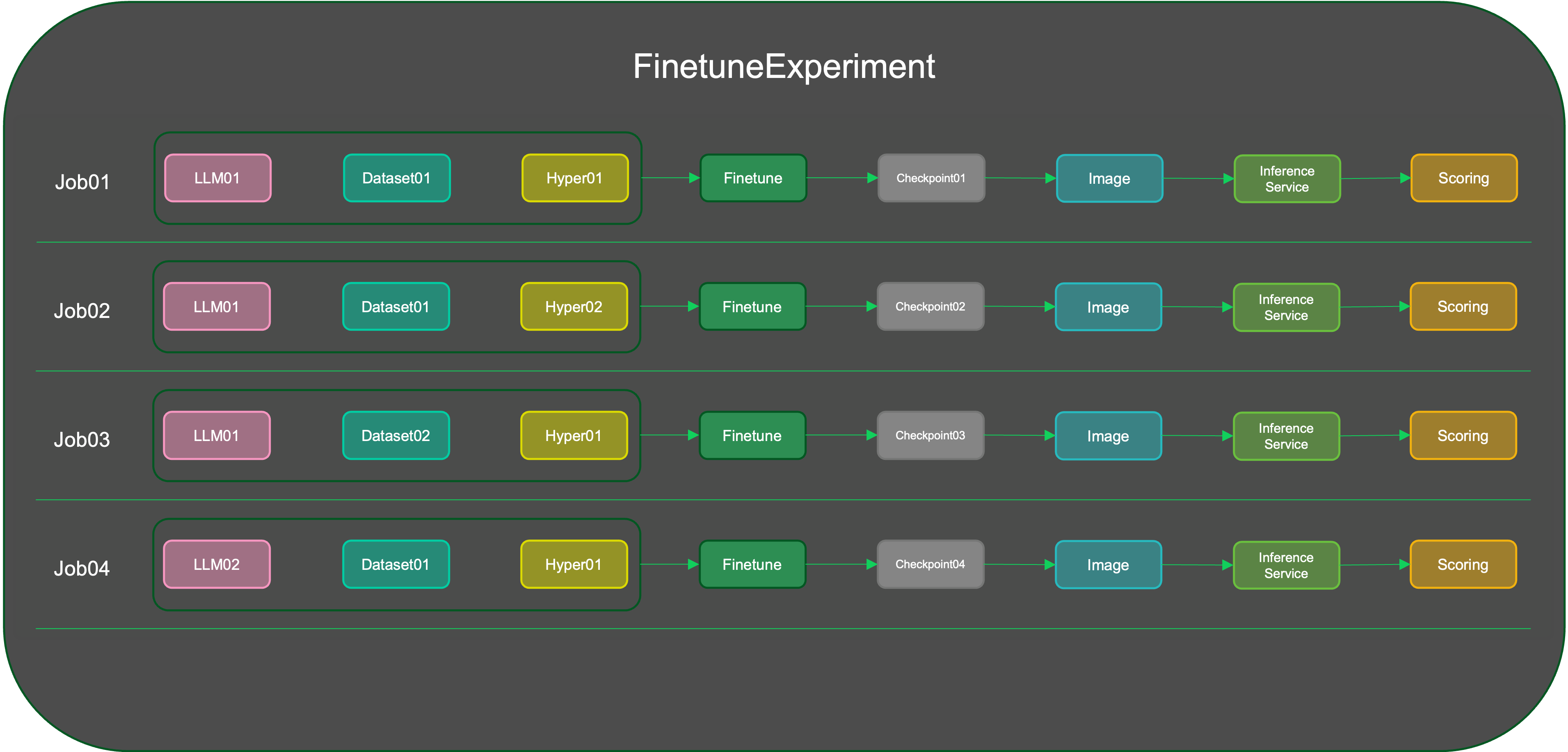
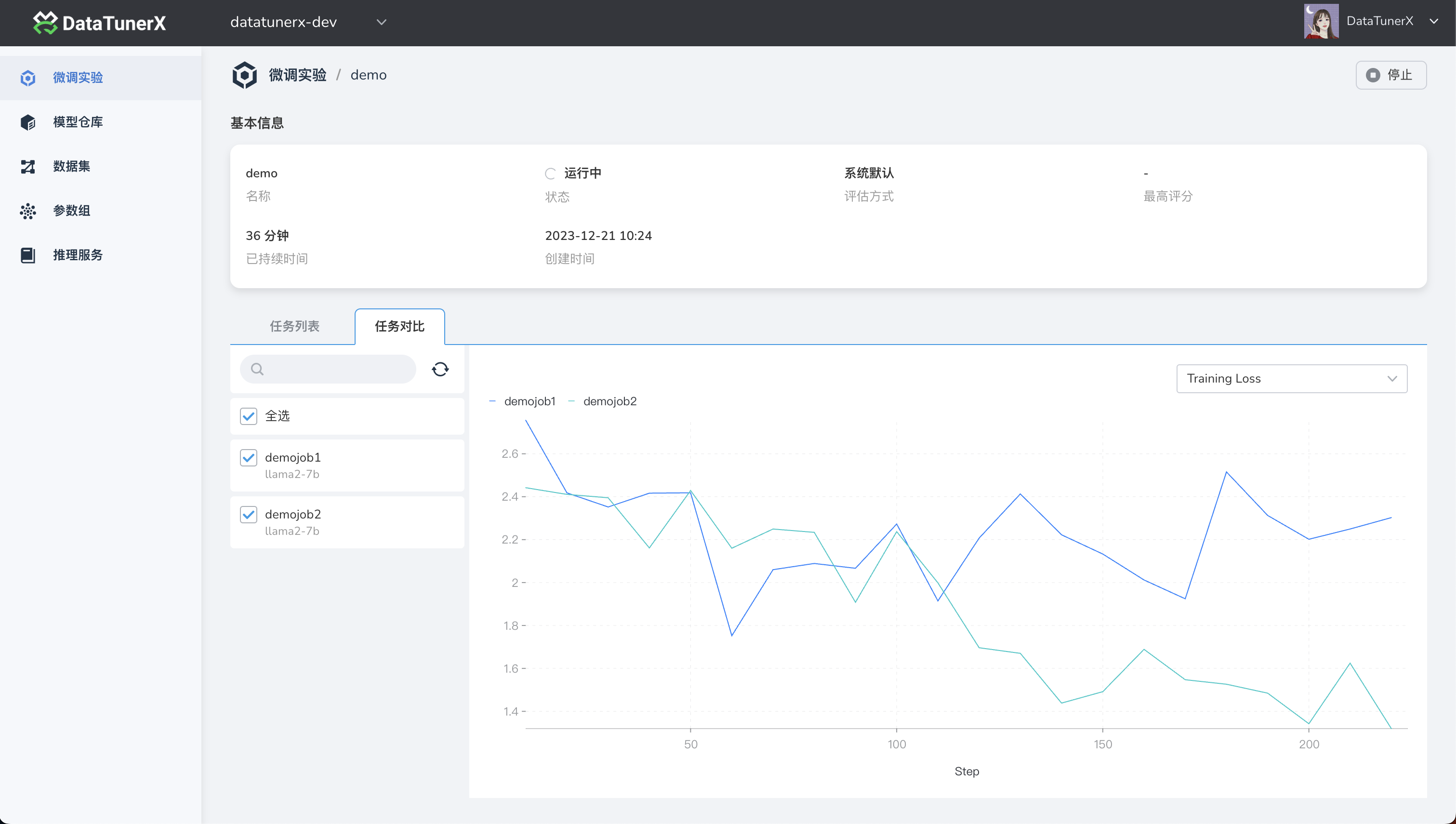
Gain detailed insights into each fine-tuning job within an experiment. Explore job details, logs, and metric visualizations, including learning rate trends, training loss, and more.
Store LLMs in the model repository, facilitating efficient management and deployment of inference services.

Utilize a rich parameter configuration system with support for diverse parameters and template-based differentiation.
Deploy inference services for multiple models simultaneously, enabling straightforward comparison and selection of the best-performing model.
Leverage the plugin system for datasets and evaluation units, allowing users to integrate specialized datasets and evaluation methods tailored to their unique requirements.
DTX offers a comprehensive suite of tools, ensuring a seamless fine-tuning experience with flexibility and powerful functionality. Explore each feature to tailor your fine-tuning tasks according to your specific needs.
DTX stands out as the preferred choice for fine-tuning large language models, offering distinct advantages that address critical challenges in natural language processing:
- Efficient GPU Integration: Seamlessly integrates with distributed computing frameworks, ensuring optimal utilization of scalable GPU resources, even in resource-constrained environments.
- Concurrent Task Execution: Excels in batch fine-tuning, enabling concurrent execution of multiple tasks within a single experiment. This enhances workflow efficiency and overall productivity.
- Diverse Capabilities: From dataset management to model management, DTX provides a comprehensive feature set catering to diverse fine-tuning requirements.
- User-Friendly Experimentation: Empowers users to effortlessly conduct fine-tuning experiments with varying models, datasets, and hyperparameters. This lowers the entry barriers for users with varying skill levels.
In summary, DTX strategically addresses challenges in resource optimization, data management, workflow efficiency, and accessibility, making it an ideal solution for efficient natural language processing tasks.
Introducing the architectural design provides an overview of how DataTunerX is structured. This includes details on key components, their interactions, and how they contribute to the system's functionality.
Detailed instructions on how to install, configure, and run the project are available in the INSTALL document.
Provide clear instructions on how to use the software, including code snippets where appropriate. (COMING SOON)
Document any known significant shortcomings with the software.
If you have questions, concerns, or bug reports, please file an issue in this repository's Issue Tracker.
We welcome contributions! Check out our CONTRIBUTING guidelines to get started. Share your feedback, report bugs, or contribute to ongoing discussions.
-
Kubernetes (k8s):
- Kubernetes: An open-source container orchestration platform for automating the deployment, scaling, and management of containerized applications.
-
Ray:
- Ray Project: An open-source distributed computing framework that makes it easy to scale and parallelize applications.
-
KubeRay:
- KubeRay: An integration of Ray with Kubernetes, enabling efficient distributed computing on Kubernetes clusters.
-
Operator SDK:
- Operator SDK: A toolkit for building Kubernetes Operators, which are applications that automate the management of custom resources in a Kubernetes cluster.
-
LLaMA-Factory:
- LLaMA-Factory: An easy-to-use llm fine-tuning framework.
Feel free to explore these projects to deepen your understanding of the technologies and concepts that may have influenced or inspired this project.