(0.7.150)
beta release
Daylily is a framework for setting up ephemeral AWS clusters optimized for genomics data analysis. It leverages AWS ParallelCluster and provides automated scripts for cluster creation, management, and teardown.

- Introduction
- Installation
- Cluster Setup
- Working with the Cluster
- Costs and Management
- Exporting Data
- Monitoring Tools
- Known Issues
- Future Development
- Contributing
- Versioning
Drafting in progress, with the intention of publishing the results in f1000-research.
In order to demonstrate the capabilities of daylily, I am processing the 7 GIAB datasets vs: 3 aligners, 1 deduper, 5 SNV callers and 3 SV callers (plus generating concordance results and a variety of qc data), for both b37 and hg38, which yields:
- 41 BAMs
- 210 SNV vcfs
- 129 SV vcfs
- 2 multiqc reports (per reference)
- many qc data files
- COST reporting for every task
I will be assessing:
- Infrastructure management aspects of daylily.
- Impact on accuracy and cost of all the combinations of above tools.
- costs (spoiler: best performance is in the $3-4/sample is reasonably to assume) of compute, data transfer, data storage & long term data storage.
- fscore (spoiler: as expected performance acheivable of 0.998+)
- Globally, raising questions about bfx analysis reproducibility, best practices vs. best performance/accuracy, ...
Would you like to lend a hand? contact me
BFAIR: Bioinformatics FAIR Principles
this is a title rough idea! - not likely final, but is the gist of it
Comprehensive Cost Transparency & Predictability (wip: interactive cost calculator is available here)
30x FASTQ->VCF, in 1hr, for
~$3 - $4
Be up and running in a few hours from reading this sentence.
- Have your first GIAB 30x Fastq->VCF (both snv and sv) ~60min later.
- The (onetime) cost of staging data is ~$20, analysis will be
~$3.00 to $5.00(pricing is established dynamically at cluster creation, and you can inspect the max bound on spot prices which are possible, this sets your upper bound... as does complexity of pipeline, but more on that latter).
Time to result, Cost of analysis, Accuracy && Integrated Concordance/Comparison: These are key elements required in making solid analysis decisions, and in setting the stage for analysis decisions which can improve in tandem as the field advances.
Cost Optimization & Predictability: With benchmarked, reproducible analysis on stable and reproducible computing platforms, it is possible to optimze for the most beneficial compute locale && to predict expected (and bound highest) per-sample cost to analyze.
Cost Transparency & Management: IRT views into what is being spent, and where. Not just compute, but data transfer, sroage, and other ALL other costs. No specialized hardware investment needed, no contracts, pay for what you use.
Pro Open Source: All out of the box functionality here is open source, and does not require any investment in software liscneces, etc. This is important for both future proof reproducibility and ongoing cost management. This said, daylily is not hostile to s/w that requires liscences (if selection of closed s/w is made understanding tradeoffs, if any, in long term reproducibility), but you will need to purchase those separately.
- https://github.com/aws/aws-parallelcluster makes the cluster creation/management possible.
- snakemake
- all the tools!

Daylily development has been under development for a number of years & is self-funded work (both time, and AWS costs).
- I am available for consulting engagements if you are interested in extending the work here. My areas of expertise also include cllical diagnostics operations, regulatory and compliance.
as the admin user
From the Iam -> Users console, create a new user.
- Allow the user to access the AWS Management Console.
- Select
I want to create an IAM usernote: the insstructions which follow will probably not work if you create a user with theIdentity Centeroption. - Specify or autogenerate a p/w, note it down.
click next- Skip (for now) attaching a group / copying permissions / attaching policies, and
click next. - Review the confiirmation page, and click
Create user. - On the next page, capture the
Console sign-in URL,username, andpassword. You will need these to log in as thedaylily-serviceuser.
still as the admin user
- Navigate to the
IAM -> Usersconsole, click on thedaylily-serviceuser. - Click on the
Add permissionsbutton, then selectAdd permission. - Search for
AmazonQDeveloperAccess, select and add it.
- Navigate to the
IAM -> Usersconsole, click on thedaylily-serviceuser. - Click on the
Add permissionsbutton, then selectcreate inline policy. - Click on the
JSONbubble button. - Delete the auto-populated json in the editor window, and paste this json into the editor (replace 3 instances of <AWS_ACCOUNT_ID> with your new account number, an integer found in the upper right dropdown).
click next- Name the policy
daylily-service-cluster-policy(not formally mandatory, but advised to bypass various warnings in future steps), then clickCreate policy.
There are a handful of quotas which will greatly limit (or block) your ability to create and run an ephemeral cluster. These quotas are set by AWS and you must request increases. The daylily-cfg=ephemeral-cluster script will check these quotas for you, and warn if it appears they are too low, but you should be aware of them and request increases proactively // these requests have no cost.
dedicated instances pre region quotas
Running Dedicated r7i Hosts>= 1 !!(AWS default is 0) !!Running On-Demand Standard (A, C, D, H, I, M, R, T, Z) instancesmust be >= 9 !!(AWS default is 5) !! just to run the headnode, and will need to be increased further for ANY other dedicated instances you (presently)/(will) run.
spot instances per region quotas
All Standard (A, C, D, H, I, M, R, T, Z) Spot Instance Requestsmust be >= 310 (and preferable >=2958) !!(AWS default is 5) !!
fsx lustre per region quotas
- should minimally allow creation of a FSX Lustre filesystem with >= 4.8 TB storage, which should be the default.
other quotas
May limit you as well, keep an eye on VPC & networking specifically.
The cost management built into daylily requires use of budgets and cost allocation tags. Someone with permissions to do so will need to activate these tags in the billing console. note: if no clusters have yet been created, these tags may not exist to be activeted until the first cluster is running. Activating these tags can happen at any time, it will not block progress on the installation of daylily if this is skipped for now. See AWS cost allocation tags
The tags to activate are:
aws-parallelcluster-jobid
aws-parallelcluster-username
aws-parallelcluster-project
aws-parallelcluster-clustername
aws-parallelcluster-enforce-budget
- The access necesary to view budgets is beyond the scope of this config, please work with your admin to set that up. If you are able to create clusters and whatnot, then the budgeting infrastructure should be working.
- Login to the AWS console as the
daylily-serviceuser using the console URL captured above.
as the daylily-service user
- Click your username in the upper right, select
Security credentials, scroll down toAccess keys, and clickCreate access key(many services will be displaying that they are not available, this is ok). - Choose 'Command Line Interface (CLI)', check
I understandand clickNext. - Do not tag the key, click
Next. IMPORTANT: Download the.csvfile, and store it in a safe place. You will not be able to download it again. This contains youraws_access_key_idandaws_secret_access_keywhich you will need to configure the AWS CLI. You may also copy this info from the confirmation page.
You will use the
aws_access_key_idandaws_secret_access_keyto configure the AWS CLI on your local machine in a future step.
as the daylily-service user
key pairs are region specific, be sure you create a key pair in the region you intend to create an ephemeral cluster in
- Navigate to the
EC2 dashboard, in the left hand menu underNetwork & Security, click onKey Pairs. - CLick
Create Key Pair. - Give it a name, which must include the string
-omics-analysis. So, ie:username-omics-analysis-region. - Choose
Key pair typeofed25519. - Choose
.pemas the file format. - Click
Create key pair. - The
.pemfile will download, and please move it into your~/.sshdir and give it appropriate permissions. you may not download this file again, so be sure to store it in a safe place.
mkdir -p ~/.ssh
chmod 700 ~/.ssh
mv ~/Downloads/<yourkey>.pem ~/.ssh/<yourkey>.pem
chmod 400 ~/.ssh/<yourkey>.pem`You may run in any region or AZ you wish to try. This said, the majority of testing has been done in AZ's us-west-2c & us-west-2d (which have consistently been among the most cost effective & available spot markets for the instance types used in the daylily workflows).
Local machine development has been exclusively on a mac, using the zsh shell (I am moving everything to bash, so there is a mix of bash and zsh at the moment. All . and sourcing that happens on your local machine expects zsh).
suggestion: run things in tmux or screen
Very good odds this will work on any mac and most Linux distros (ubuntu 22.04 are what the cluster nodes run). Windows, I can't say.
Install with brew, conda or apt-get:
python3gitjqwgetawscliAWS CLI docstmux(optional, but suggested)emacs(optional, I guess, but I'm not sure how you live without it)
Create the aws cli files and directories manually.
mkdir ~/.aws
chmod 700 ~/.aws
touch ~/.aws/credentials
chmod 600 ~/.aws/credentials
touch ~/.aws/config
chmod 600 ~/.aws/configEdit ~/.aws/config, which should look like:
[default]
region = us-west-2
output = json
[daylily-service]
region = us-west-2
output = json
Edit ~/.aws/credentials, and add your deets, which should look like:
[default]
aws_access_key_id = <default-ACCESS_KEY>
aws_secret_access_key = <default-SECRET_ACCESS_KEY>
region = <REGION>
[daylily-service]
aws_access_key_id = <daylily-service-ACCESS_KEY>
aws_secret_access_key = <daylily-service-SECRET_ACCESS_KEY>
region = <REGION>- The
defaultprofile is used for general AWS CLI commands,daylily-servicecan be the same as default, best practice to not lean on default, but be explicit with the intended AWS_PROFILE used.
To automatically use a profile other than
default, set theAWS_PROFILEenvironment variable to the profile name you wish to use. ie:export AWS_PROFILE=daylily-service
git clone https://github.com/Daylily-Informatics/daylily.git # or, if you have set ssh keys with github and intend to make changes: git clone git@github.com:Daylily-Informatics/daylily.git
cd daylilyfrom daylily root dir
Install with:
```bash
#!/bin/zsh
source bin/install_miniconda- This will leave you in a terminal with conda activated, indicated by
(base)in the terminal prompt.
from daylily root dir
#!/bin/zsh
source bin/init_daycli
# DAYCLI should now be active... did it work?
colr 'did it work?' 0,100,255 255,100,0
- This will leave you in a terminal with the conda DAYCLI activated, indicated by
(DAYCLI)in the terminal prompt.
daylily-references-public Reference Bucket
- The
daylily-references-publicbucket is preconfigured with all the necessary reference data to run the various pipelines, as well as including GIAB reads for automated concordance. - This bucket will need to be cloned to a new bucket with the name
<YOURPREFIX>-omics-analysis-<REGION>, one for each region you intend to run in. - These S3 buckets are tightly coupled to the
Fsx lustrefilesystems (which allows 1000s of concurrnet spot instances to read/write to the shared filesystem, making reference and data management both easier and highly performant). - Continue for more on this topic,,,.
- This will cost you ~$23 to clone w/in
us-west-2, up to $110 across regions. (one time, per region, cost) - The bust will cost ~$14.50/mo to keep hot in
us-west-2. It is not advised, but you may opt to remove unused reference data to reduce the monthly cost footprint by up to 65%. (monthly ongoing cost)
from your local machine, in the daylily git repo root
You may add/remove/update your copy of the refernces bucket as you find necessary.
YOURPREFIXwill be used as the bucket name prefix. Please keep it short. The new bucket name will beYOURPREFIX-omics-analysis-REGIONand created in the region you specify. You may name the buckets in other ways, but this will block you from using thedaylily-create-ephemeral-clusterscript, which is largely why you're here.- Cloning it will take 1 to many hours.
Use the following script
running in a tmux/screen session is advised as the copy may take 1-many hours
conda activate DAYCLI
# help
bash ./bin/create_daylily_omics_analysis_s3.sh -h
AWS_PROFILE=<your_profile>
BUCKET_PREFIX=<your_prefix>
REGION=us-west-2
# dryrun
bash ./bin/create_daylily_omics_analysis_s3.sh --disable-warn --region $REGION --profile $AWS_PROFILE --bucket-prefix $BUCKET_PREFIX
# run for real
bash ./bin/create_daylily_omics_analysis_s3.sh --disable-warn --region $REGION --profile $AWS_PROFILE --bucket-prefix $BUCKET_PREFIX --disable-dryrun
You may visit the
S3console to confirm the bucket is being cloned as expected. The copy (if w/inus-west-2should take ~1hr, much longer across AZs.
from your local machine, in the daylily git repo root
You may choose any AZ to build and run an ephemeral cluster in (assuming resources both exist and can be requisitioned in the AZ). Run the following command to scan the spot markets in the AZ's you are interested in assessing (reference buckets do not need to exist in the regions you scan, but to ultimately run there, a reference bucket is required):
this command will take ~5min to complete, and much longer if you expand to all possible AZs, run with --help for all flags
conda activate DAYCLI
AWS_PROFILE=daylily-service
REGION=us-west-2
OUT_TSV=./init_daylily_cluster.tsv
./bin/check_current_spot_market_by_zones.py -o $OUT_TSV --profile $AWS_PROFILE 
30.0-cov genome @ vCPU-min per x align: 307.2 vCPU-min per x snvcall: 684.0 vCPU-min per x other: 0.021 vCPU-min per x svcall: 19.0
╒═══════════════════╤════════════╤═══════════╤═══════════╤═══════════╤════════════╤═══════════╤═══════════╤═══════════╤═══════════╤═══════════╤═══════════╤═══════════╤═══════════╤════════════╤════════════╕
│ Region AZ │ # │ Median │ Min │ Max │ Harmonic │ Spot │ FASTQ │ BAM │ CRAM │ snv │ snv │ sv │ Other │ $ per │ ~ EC2 $ │
│ │ Instance │ Spot $ │ Spot │ Spot │ Mean │ Stab- │ (GB) │ (GB) │ (GB) │ VCF │ gVCF │ VCF │ (GB) │ vCPU min │ │
│ │ Types │ │ $ │ $ │ Spot $ │ ility │ │ │ │ (GB) │ (GB) │ (GB) │ │ harmonic │ harmonic │
╞═══════════════════╪════════════╪═══════════╪═══════════╪═══════════╪════════════╪═══════════╪═══════════╪═══════════╪═══════════╪═══════════╪═══════════╪═══════════╪═══════════╪════════════╪════════════╡
│ 1. us-west-2a │ 6 │ 3.55125 │ 2.53540 │ 9.03330 │ 3.63529 │ 6.49790 │ 49.50000 │ 39.00000 │ 13.20000 │ 0.12000 │ 1.20000 │ 0.12000 │ 0.00300 │ 0.00032 │ 9.56365 │
├───────────────────┼────────────┼───────────┼───────────┼───────────┼────────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼────────────┼────────────┤
│ 2. us-west-2b │ 6 │ 2.69000 │ 0.93270 │ 7.96830 │ 2.06066 │ 7.03560 │ 49.50000 │ 39.00000 │ 13.20000 │ 0.12000 │ 1.20000 │ 0.12000 │ 0.00300 │ 0.00018 │ 5.42115 │
├───────────────────┼────────────┼───────────┼───────────┼───────────┼────────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼────────────┼────────────┤
│ 3. us-west-2c │ 6 │ 2.45480 │ 0.92230 │ 5.14490 │ 1.80816 │ 4.22260 │ 49.50000 │ 39.00000 │ 13.20000 │ 0.12000 │ 1.20000 │ 0.12000 │ 0.00300 │ 0.00016 │ 4.75687 │
├───────────────────┼────────────┼───────────┼───────────┼───────────┼────────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼────────────┼────────────┤
│ 4. us-west-2d │ 6 │ 1.74175 │ 0.92420 │ 4.54950 │ 1.71232 │ 3.62530 │ 49.50000 │ 39.00000 │ 13.20000 │ 0.12000 │ 1.20000 │ 0.12000 │ 0.00300 │ 0.00015 │ 4.50474 │
├───────────────────┼────────────┼───────────┼───────────┼───────────┼────────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼────────────┼────────────┤
│ 5. us-east-1a │ 6 │ 3.21395 │ 1.39280 │ 4.56180 │ 2.37483 │ 3.16900 │ 49.50000 │ 39.00000 │ 13.20000 │ 0.12000 │ 1.20000 │ 0.12000 │ 0.00300 │ 0.00021 │ 6.24766 │
├───────────────────┼────────────┼───────────┼───────────┼───────────┼────────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼────────────┼────────────┤
│ 6. us-east-1b │ 6 │ 3.06900 │ 1.01450 │ 6.97430 │ 2.48956 │ 5.95980 │ 49.50000 │ 39.00000 │ 13.20000 │ 0.12000 │ 1.20000 │ 0.12000 │ 0.00300 │ 0.00022 │ 6.54950 │
├───────────────────┼────────────┼───────────┼───────────┼───────────┼────────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼────────────┼────────────┤
│ 7. us-east-1c │ 6 │ 3.53250 │ 1.11530 │ 4.86300 │ 2.69623 │ 3.74770 │ 49.50000 │ 39.00000 │ 13.20000 │ 0.12000 │ 1.20000 │ 0.12000 │ 0.00300 │ 0.00023 │ 7.09320 │
├───────────────────┼────────────┼───────────┼───────────┼───────────┼────────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼────────────┼────────────┤
│ 8. us-east-1d │ 6 │ 2.07570 │ 0.92950 │ 6.82380 │ 1.79351 │ 5.89430 │ 49.50000 │ 39.00000 │ 13.20000 │ 0.12000 │ 1.20000 │ 0.12000 │ 0.00300 │ 0.00016 │ 4.71835 │
├───────────────────┼────────────┼───────────┼───────────┼───────────┼────────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼────────────┼────────────┤
│ 9. ap-south-1a │ 6 │ 1.78610 │ 1.01810 │ 3.51470 │ 1.63147 │ 2.49660 │ 49.50000 │ 39.00000 │ 13.20000 │ 0.12000 │ 1.20000 │ 0.12000 │ 0.00300 │ 0.00014 │ 4.29204 │
├───────────────────┼────────────┼───────────┼───────────┼───────────┼────────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼────────────┼────────────┤
│ 10. ap-south-1b │ 6 │ 1.29050 │ 1.00490 │ 2.24560 │ 1.37190 │ 1.24070 │ 49.50000 │ 39.00000 │ 13.20000 │ 0.12000 │ 1.20000 │ 0.12000 │ 0.00300 │ 0.00012 │ 3.60917 │
├───────────────────┼────────────┼───────────┼───────────┼───────────┼────────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼────────────┼────────────┤
│ 11. ap-south-1c │ 6 │ 1.26325 │ 0.86570 │ 1.42990 │ 1.18553 │ 0.56420 │ 49.50000 │ 39.00000 │ 13.20000 │ 0.12000 │ 1.20000 │ 0.12000 │ 0.00300 │ 0.00010 │ 3.11886 │
├───────────────────┼────────────┼───────────┼───────────┼───────────┼────────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼────────────┼────────────┤
│ 12. ap-south-1d │ 0 │ nan │ nan │ nan │ nan │ nan │ nan │ nan │ nan │ nan │ nan │ nan │ nan │ nan │ nan │
├───────────────────┼────────────┼───────────┼───────────┼───────────┼────────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼────────────┼────────────┤
│ 13. eu-central-1a │ 6 │ 5.88980 │ 2.02420 │ 15.25590 │ 4.32093 │ 13.23170 │ 49.50000 │ 39.00000 │ 13.20000 │ 0.12000 │ 1.20000 │ 0.12000 │ 0.00300 │ 0.00038 │ 11.36744 │
├───────────────────┼────────────┼───────────┼───────────┼───────────┼────────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼────────────┼────────────┤
│ 14. eu-central-1b │ 6 │ 2.00245 │ 1.11620 │ 2.97580 │ 1.72476 │ 1.85960 │ 49.50000 │ 39.00000 │ 13.20000 │ 0.12000 │ 1.20000 │ 0.12000 │ 0.00300 │ 0.00015 │ 4.53746 │
├───────────────────┼────────────┼───────────┼───────────┼───────────┼────────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼────────────┼────────────┤
│ 15. eu-central-1c │ 6 │ 1.90570 │ 1.15920 │ 3.36620 │ 1.71591 │ 2.20700 │ 49.50000 │ 39.00000 │ 13.20000 │ 0.12000 │ 1.20000 │ 0.12000 │ 0.00300 │ 0.00015 │ 4.51419 │
├───────────────────┼────────────┼───────────┼───────────┼───────────┼────────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼────────────┼────────────┤
│ 16. ca-central-1a │ 6 │ 3.89545 │ 3.42250 │ 5.23380 │ 4.04001 │ 1.81130 │ 49.50000 │ 39.00000 │ 13.20000 │ 0.12000 │ 1.20000 │ 0.12000 │ 0.00300 │ 0.00035 │ 10.62839 │
├───────────────────┼────────────┼───────────┼───────────┼───────────┼────────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼────────────┼────────────┤
│ 17. ca-central-1b │ 6 │ 3.81865 │ 3.18960 │ 4.92650 │ 3.86332 │ 1.73690 │ 49.50000 │ 39.00000 │ 13.20000 │ 0.12000 │ 1.20000 │ 0.12000 │ 0.00300 │ 0.00034 │ 10.16355 │
├───────────────────┼────────────┼───────────┼───────────┼───────────┼────────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼───────────┼────────────┼────────────┤
│ 18. ca-central-1c │ 0 │ nan │ nan │ nan │ nan │ nan │ nan │ nan │ nan │ nan │ nan │ nan │ nan │ nan │ nan │
╘═══════════════════╧════════════╧═══════════╧═══════════╧═══════════╧════════════╧═══════════╧═══════════╧═══════════╧═══════════╧═══════════╧═══════════╧═══════════╧═══════════╧════════════╧════════════╛
Select the availability zone by number:
The script will go on to approximate the entire cost of analysis: EC2 costs, data transfer costs and storage cost. Both the active analysis cost, and also the approximate costs of storing analysis results per month.
from your local machine, in the daylily git repo root
Once you have selected an AZ && have a reference bucket ready in the region this AZ exists in, you are ready to proceed to creating an ephemeral cluster.
The following script will check a variety of required resources, attempt to create some if missing and then prompt you to select various options which will all be used to create a new parallel cluster yaml config, which in turn is used to create the cluster via StackFormation. The template yaml file can be checked out here.
#!/bin/zsh
AWS_PROFILE=daylily-service
REGION_AZ=us-west-2c
source bin/daylily-create-ephemeral-cluster --region-az $REGION_AZ --profile $AWS_PROFILE
# And to bypass the non-critical warnings (which is fine, not all can be resolved )
source bin/daylily-create-ephemeral-cluster --region-az $REGION_AZ --profile $AWS_PROFILE --pass-on-warn # If you created an inline policy with a name other than daylily-service-cluster-policy, you will need to acknowledge the warning to proceed (assuming the policy permissions were granted other ways)
The gist of the flow of the script is as follows:
-
Your aws credentials will be auto-detected and used to query appropriate resources to select from to proceed. You will be prompted to:
-
(one per-region) select the full path to your $HOME/.ssh/.pem (from detected .pem files)
-
(one per-region) select the
s3bucket you created and seeded, options presented will be any with names ending in-omics-analysis. Or you may select1and manually enter a s3 url. -
(one per-region-az) select the
Public Subnet IDcreated when the cloudstack formation script was run earlier. if none are detected, this will be auto-created for you via stack formation -
(one per-region-az) select the
Private Subnet IDcreated when the cloudstack formation script was run earlier.from the cloudformation stack output. if none are detected, this will be auto-created for you via stack formation -
(one per-aws-account) select the
Policy ARNcreated when the cloudstack formation script was run earlier. if none are detected, this will be auto-created for you via stack formation -
(one unique name per region)enter a name to asisgn your new ephemeral cluster (ie:
<myorg>-omics-analysis) -
(one per-aws account) You will be prompted to enter info to create a
daylily-globalbudget (allowed user-strings:daylily-service, alert email:your@email, budget amount:100) -
(one per unique cluster name) You will be prompted to enter info to create a
daylily-ephemeral-clusterbudget (allowed user-strings:daylily-service, alert email:your@email, budget amount:100) -
Enforce budgets? (default is no, yes is not fully tested)
-
Choose the cloudstack formation
yamltemplate (default isprod_cluster.yaml) -
Choose the FSx size (default is 4.8TB)
-
Opt to store detailed logs or not (default is no)
-
Choose if you wish to AUTO-DELETE the root EBS volumes on cluster termination (default is NO be sure to clean these up if you keep this as no)
-
Choose if you wish to RETAIN the FSx filesystem on cluster termination (default is YES be sure to clean these up if you keep this as yes)
The script will take all of the info entered and proceed to:
-
Run a process will run to poll and populate maximum spot prices for the instance types used in the cluster.
-
A
CLUSTERNAME_cluster.yamlandCLUSTERNAME_cluster_init_vals.txtfile are created in~/.config/daylily/, -
First, a dryrun cluster creation is attempted. If successful, creation proceeds. If unsuccessful, the process will terminate.
-
The ephemeral cluster creation will begin and a monitoring script will watch for its completion. this can take from 20m to an hour to complete, depending on the region, size of Fsx requested, S3 size, etc. There is a max timeout set in the cluster config yaml of 1hr, which will cause a failure if the cluster is not up in that time.
The terminal will block, a status message will slowly scroll by, and after ~20m, if successful, the headnode config will begin (you may be prompted to select the cluster to config if there are multiple in the AZ. The headnode confiig will setup a few final bits, and then run a few tests (you should see a few magenta success bars during this process).
If all is well, you will see the following message:
You can now SSH into the head node with the following command:
ssh -i /Users/daylily/.ssh/omics-analysis-b.pem ubuntu@52.24.138.65
Once logged in, as the 'ubuntu' user, run the following commands:
cd ~/projects/daylily
source dyinit
source dyinit --project PROJECT
dy-a local
dy-g hg38
dy-r help
"Would you like to start building various caches needed to run jobs? [y/n]"
-
(optional), you may select
yornto begin building the cached environments on the cluster. The caches will be automatically created if missing whenever a job is submitted. They should only need to be created once per ephemeral cluster (the compute nodes all share the caches w/the headnode). The build can take 15-30m the first time. -
You are ready to roll.
During cluster creation, and especially if you need to debug a failure, please go to the
CloudFormationconsole and look at theCLUSTER-NAMEstack. TheEventstab will give you a good idea of what is happening, and theOutputstab will give you the IP of the headnode, and theResourcestab will give you the ARN of the FSx filesystem, which you can use to look at the FSx console to see the status of the filesystem creation.
#!/bin/zsh
source ./bin/daylily-run-ephemeral-cluster-remote-tests $pem_file $region $AWS_PROFILEA successful test will look like this:

You may confirm the cluster creation was successful with the following command (alternatively, use the PCUI console).
pcluster list-clusters --region $REGIONSee the instructions here to confirm the headnode is configured and ready to run the daylily pipeline.
Every resource created by daylily is tagged to allow in real time monitoring of costs, to whatever level of granularity you desire. This is intended as a tool for not only managing costs, but as a very important metric to track in assessing various tools utility moving ahead (are the costs of a tool worth the value of the data produced by it, and how does this tool compare with others in the same class?)
During setup of each ephemeral cluster, each cluster can be configured to enforce budgets. Meaning, job submission will be blocked if the budget specifiecd has been exceeded.
For default configuration, once running, the hourly cost will be ~ $1.68 (note: the cluster is intended to be up only when in use, not kept hot and inactive). The cost drivers are:
r7i.2xlargeon-demand headnode =$0.57 / hr.fsxfilesystem =$1.11 / hr(for 4.8TB, which is the default size for daylily. You do not pay by usage, but by size requested).- No other EC2 or storage (beyond the s3 storage used for the ref bucket and your sample data storage) costs are incurred.
There is the idle hourly costs, plus...
For v192 spots, the cost is generally $1 to $3 per hour (if you are discriminating in your AZ selection, the cost should be closer to $1/hr).
- You pay for spot instances as they spin up and until they are shut down (which all happens automatically). The max spot price per resource group limits the max costs (as does the max number of instances allowed per group, and your quotas).
There are no anticipated or observed costs in runnin the default daylily pipeline, as all data is already located in the same region as the cluster. The cost to reflect data from Fsx back to S3 is effectively $0.
Depending on your data management strategy, these costs will be zero or more than zero.
- You can use Fsx to bounce results back to the mounted S3 bucket, then move the results elsewhre, or move them from the cluster to another bucket (the former I know has no impact on performance, the latter might interfere with network latency?).
- You are paying for the fsx filesystem, which are represented in the idle cluster hourly cost. There are no costs beyond this for storage.
- HOWEVER, you are responsible for sizing the Fsx filesystem for your workload, and to be on top of moving data off of it as analysis completes. Fsx is not intended as a long term storage location, but is very much a high performance scratch space.
If its not being used, there is no cost incurred.
- The reference bucket will cost ~$14.50/mo to keep available in
us-west-2, and one will be needed in any AZ you intend to run in. - You should not store your sample or analysis data here long term.
- I argue that it is unecessary to store
fastqfiles once bams are (properly) created, as the bam can reconstitute the fastq. So, the cost of storing fastqs beyond initial analysis, should be$0.00.
I suggest:
- CRAM (which is ~1/3 the size of BAM, costs correspondingly less in storage and transfer costs).
- gvcf.gz, which are bigger than vcf.gz, but contain more information, and are more useful for future analysis. note, bcf and vcf.gz sizes are effectively the same and do not justify the overhad of managing the additional format IMO.
Install instructions here, launch it using the public subnet created in your cluster, and the vpcID this public net belongs to. These go in the ImageBuilderVpcId and ImageBuilderSubnetId respectively.
You should be sure to enable SSM which allows remote access to the nodes from the PCUI console. https://docs.aws.amazon.com/systems-manager/latest/userguide/session-manager-getting-started-ssm-user-permissions.html
Use a preconfigured template in the region you have built a cluster in, they can be found here.
You will need to enter the following (all other params may be left as default):
Stack name: parallelcluster-uiAdmin's Email: your email ( a confirmation email will be sent to this address with the p/w for the UI, and can not be re-set if lost ).ImageBuilderVpcId: the vpcID of the public subnet created in your cluster creation, visit the VPC console and look for a name likedaylily-cs-<REGION-AZ>#AZ is digested to text, us-west-2d becomes us-west-twodImageBuilderSubnetId: the subnetID of the public subnet created in your cluster creation, visit the VPC console to find this (possibly navigate from the EC2 headnode to this).- Check the 2 acknowledgement boxes, and click
Create Stack.
This will boot you to cloudformation, and will take ~10m to complete. Once complete, you will receive an email with the password to the PCUI console.
To find the PCUI url, visit the Outputs tab of the parallelcluster-ui stack in the cloudformation console, the url for ParallelClusterUIUrl is the one you should use. You use the entered email and the password emailed to login the first time.
The PCUI stuff is not required, but very VERY awesome.
AND, it seems there is a permissions problem with the
daylily-serviceuser, as it is setup right now... the stack is failing. Permissions are likely missing...
Visit your url created when you built a PCUI
conda activate DAYCLIWARNING: you are advised to run aws configure set region <REGION> to set the region for use with the pcluster CLI, to avoid the errors you will cause when the --region flag is omitted.
pcluster -h
usage: pcluster [-h]
{list-clusters,create-cluster,delete-cluster,describe-cluster,update-cluster,describe-compute-fleet,update-compute-fleet,delete-cluster-instances,describe-cluster-instances,list-cluster-log-streams,get-cluster-log-events,get-cluster-stack-events,list-images,build-image,delete-image,describe-image,list-image-log-streams,get-image-log-events,get-image-stack-events,list-official-images,configure,dcv-connect,export-cluster-logs,export-image-logs,ssh,version}
...
pcluster is the AWS ParallelCluster CLI and permits launching and management of HPC clusters in the AWS cloud.
options:
-h, --help show this help message and exit
COMMANDS:
{list-clusters,create-cluster,delete-cluster,describe-cluster,update-cluster,describe-compute-fleet,update-compute-fleet,delete-cluster-instances,describe-cluster-instances,list-cluster-log-streams,get-cluster-log-events,get-cluster-stack-events,list-images,build-image,delete-image,describe-image,list-image-log-streams,get-image-log-events,get-image-stack-events,list-official-images,configure,dcv-connect,export-cluster-logs,export-image-logs,ssh,version}
list-clusters Retrieve the list of existing clusters.
create-cluster Create a managed cluster in a given region.
delete-cluster Initiate the deletion of a cluster.
describe-cluster Get detailed information about an existing cluster.
update-cluster Update a cluster managed in a given region.
describe-compute-fleet
Describe the status of the compute fleet.
update-compute-fleet
Update the status of the cluster compute fleet.
delete-cluster-instances
Initiate the forced termination of all cluster compute nodes. Does not work with AWS Batch clusters.
describe-cluster-instances
Describe the instances belonging to a given cluster.
list-cluster-log-streams
Retrieve the list of log streams associated with a cluster.
get-cluster-log-events
Retrieve the events associated with a log stream.
get-cluster-stack-events
Retrieve the events associated with the stack for a given cluster.
list-images Retrieve the list of existing custom images.
build-image Create a custom ParallelCluster image in a given region.
delete-image Initiate the deletion of the custom ParallelCluster image.
describe-image Get detailed information about an existing image.
list-image-log-streams
Retrieve the list of log streams associated with an image.
get-image-log-events
Retrieve the events associated with an image build.
get-image-stack-events
Retrieve the events associated with the stack for a given image build.
list-official-images
List Official ParallelCluster AMIs.
configure Start the AWS ParallelCluster configuration.
dcv-connect Permits to connect to the head node through an interactive session by using NICE DCV.
export-cluster-logs
Export the logs of the cluster to a local tar.gz archive by passing through an Amazon S3 Bucket.
export-image-logs Export the logs of the image builder stack to a local tar.gz archive by passing through an Amazon S3 Bucket.
ssh Connects to the head node instance using SSH.
version Displays the version of AWS ParallelCluster.
For command specific flags, please run: "pcluster [command] --help"
pcluster list-clusters --region us-west-2pcluster describe-cluster -n $cluster_name --region us-west-2ie: to get the public IP of the head node.
pcluster describe-cluster -n $cluster_name --region us-west-2 | grep 'publicIpAddress' | cut -d '"' -f 4From your local shell, you can ssh into the head node of the cluster using the following command.
ssh -i $pem_file ubuntu@$cluster_ip_address AWS_PROFILE=<profile_name>
bin/daylily-ssh-into-headnode
Is daylily CLI Available & Working
cd ~/projects/daylily
. dyinit # inisitalizes the daylily cli
dy-a local # activates the local config
dy-g hg38 # sets the genome to hg38if
. dyinitworks, butdy-a localfails, trydy-b BUILD
This should produce a magenta WORKFLOW SUCCESS message and RETURN CODE: 0 at the end of the output. If so, you are set. If not, see the next section.
If there is no ~/projects/daylily directory, or the dyinit command is not found, the headnode configuration is incomplete.
Attempt To Complete Headnode Configuration From your remote terminal that you created the cluster with, run the following commands to complete the headnode configuration.
conda activate DAYCLI
source ./bin/daylily-cfg-headnode $PATH_TO_PEM $CLUSTER_AWS_REGION $AWS_PROFILEIf the problem persists, ssh into the headnode, and attempt to run the commands as the ubuntu user which are being attempted by the
daylily-cfg-headnodescript.
Confirm /fsx/ directories are present
ls -lth /fsx/
total 130K
drwxrwxrwx 3 root root 33K Sep 26 09:22 environments
drwxr-xr-x 5 root root 33K Sep 26 08:58 data
drwxrwxrwx 5 root root 33K Sep 26 08:35 analysis_results
drwxrwxrwx 3 root root 33K Sep 26 08:35 resourcesinit daylily, activate an analysis profile, set genome, stage an analysis_manigest.csv and run a test workflow.
. dyinit --project PROJECT
dy-a local
dy-g hg38 # the other option: b37 ( or set via config command line below)
head -n 2 .test_data/data/giab_30x_hg38_analysis_manifest.csv
dy-r produce_deduplicated_bams -p -j 2 --config genome_build=hg38 aligners=['bwa2a','sent'] dedupers=['dppl'] -n # dry run
dy-r produce_deduplicated_bams -p -j 2 --config genome_build=hg38 aligners=['bwa2a','sent'] dedupers=['dppl'] The -j flag specified in dy-r limits the number of jobs submitted to slurm. For out of the box settings, the advised range for -j is 1 to 10. You may omit this flag, and allow submitting all potnetial jobs to slurm, which slurm, /fsx, and the instances can handle growing to the 10s or even 100 thousands of instances... however, various quotas will begin causing problems before then. The local defauly is set to -j 1 and slurm is set to -j 10, -j may be set to any int > 0.
This will produce a job plan, and then begin executing. The sample manifest can be found in .test_data/data/0.01x_3_wgs_HG002.samplesheet.csv (i am aware this is not a .tsv :-P ). Runtime on the default small test data runnin locally on the default headnode instance type should be ~5min.
NOTE! NOTE !! NOTE !!! ---- The Undetermined Sample Is Excluded. Set --config keep_undetermined=1 to process it.
Building DAG of jobs...
Creating conda environment workflow/envs/vanilla_v0.1.yaml...
Downloading and installing remote packages.
Environment for /home/ubuntu/projects/daylily/workflow/rules/../envs/vanilla_v0.1.yaml created (location: ../../../../fsx/resources/environments/conda/ubuntu/ip-10-0-0-37/f7b02dfcffb9942845fe3a995dd77dca_)
Creating conda environment workflow/envs/strobe_aligner.yaml...
Downloading and installing remote packages.
Environment for /home/ubuntu/projects/daylily/workflow/rules/../envs/strobe_aligner.yaml created (location: ../../../../fsx/resources/environments/conda/ubuntu/ip-10-0-0-37/a759d60f3b4e735d629d60f903591630_)
Using shell: /usr/bin/bash
Provided cores: 16
Rules claiming more threads will be scaled down.
Provided resources: vcpu=16
Job stats:
job count min threads max threads
------------------------- ------- ------------- -------------
doppelmark_dups 1 16 16
pre_prep_raw_fq 1 1 1
prep_results_dirs 1 1 1
produce_deduplicated_bams 1 1 1
stage_supporting_data 1 1 1
strobe_align_sort 1 16 16
workflow_staging 1 1 1
total 7 1 16
This should exit with a magenta success message and
RETURN CODE: 0. Results can be found inresults/day/{hg38,b37}.
The following will submit jobs to the slurm scheduler on the headnode, and spot instances will be spun up to run the jobs (modulo limits imposed by config and quotas).
First, create a working directory on the /fsx/ filesystem.
init daylily, activate an analysis profile, set genome, stage an analysis_manigest.csv and run a test workflow.
# create a working analysis directory
mkdir -p /fsx/analysis_results/ubuntu/init_test
cd /fsx/analysis_results/ubuntu/init_test
git clone https://github.com/Daylily-Informatics/daylily.git # or, if you have set ssh keys with github and intend to make changes: git clone git@github.com:Daylily-Informatics/daylily.git
cd daylily
# prepare to run the test
tmux new -s slurm_test
. dyinit
dy-a slurm
dy-g hg38
# create a test manifest for one giab sample only, which will run on the 0.01x test dataset
head -n 2 .test_data/data/0.01xwgs_HG002_hg38.samplesheet.csv > config/analysis_manifest.csv
# run the test, which will auto detect the analysis_manifest.csv file & will run this all via slurm
dy-r produce_snv_concordances -p -k -j 2 --config genome_build=hg38 aligners=['bwa2a'] dedupers=['dppl'] snv_callers=['deep'] -nWhich will produce a plan that looks like.
Job stats:
job count min threads max threads
-------------------------- ------- ------------- -------------
deep_concat_fofn 1 2 2
deep_concat_index_chunks 1 4 4
deepvariant 24 64 64
doppelmark_dups 1 192 192
dv_sort_index_chunk_vcf 24 4 4
pre_prep_raw_fq 1 1 1
prep_deep_chunkdirs 1 1 1
prep_for_concordance_check 1 32 32
prep_results_dirs 1 1 1
produce_snv_concordances 1 1 1
stage_supporting_data 1 1 1
strobe_align_sort 1 192 192
workflow_staging 1 1 1
total 59 1 192
Run the test with:
dy-r produce_snv_concordances -p -k -j 6 --config genome_build=hg38 aligners=['bwa2a'] dedupers=['dppl'] snv_callers=['deep'] # -j 6 will run 6 jobs in parallel max, which is done here b/c the test data runs so quickly we do not need to spin up one spor instance per deepvariant job & since 3 dv jobs can run on a 192 instance, this flag will limit creating only 2 instances at a time.note1: the first time you run a pipeline, if the docker images are not cached, there can be a delay in starting jobs as the docker images are cached. They are only pulled 1x per cluster lifetime, so subsequent runs will be faster.
note2: The first time a cold cluster requests spot instances, can take some time (~10min) to begin winning spot bids and running jobs. Hang tighe, and see below for monitoring tips.
ALERT The analysis_manifest.csv is being re-worked to be more user friendly. The following will continue to work, but will be repleaced with a less touchy method soon.
You may repeat the above, and use the pre-existing analysis_manifest.csv template .test_data/data/giab_30x_hg38_analysis_manifest.csv.
tmux new -s slurm_test_30x_single
mkdir /fsx/analysis_results/ubuntu/slurm_single
cd /fsx/analysis_results/ubuntu/slurm_single
git clone https://github.com/Daylily-Informatics/daylily.git # or, if you have set ssh keys with github and intend to make changes: git clone git@github.com:Daylily-Informatics/daylily.git
cd daylily
. dyinit --project PROJECT
dy-a slurm
dy-g hg38
# TO create a single sample manifest
head -n 2 .test_data/data/giab_30x_hg38_analysis_manifest.csv > config/analysis_manifest.csv
dy-r produce_snv_concordances -p -k -j 10 --config genome_build=hg38 aligners=['bwa2a'] dedupers=['dppl'] snv_callers=['deep'] -n # dry run
dy-r produce_snv_concordances -p -k -j 10 --config genome_build=hg38 aligners=['bwa2a'] dedupers=['dppl'] snv_callers=['deep'] # run jobs, and wait for completionSpecify A Multi-Sample Manifest (in this case, all 7 GIAB samples) - 2 aligners, 1 deduper, 2 snv callers
tmux new -s slurm_test_30x_multi
mkdir /fsx/analysis_results/ubuntu/slurm_multi_30x_test
cd /fsx/analysis_results/ubuntu/slurm_multi_30x_test
git clone https://github.com/Daylily-Informatics/daylily.git # or, if you have set ssh keys with github and intend to make changes: git clone git@github.com:Daylily-Informatics/daylily.git
cd daylily
. dyinit --project PROJECT
dy-a slurm
dy-g hg38
# copy full 30x giab sample template to config/analysis_manifest.csv
cp .test_data/data/giab_30x_hg38_analysis_manifest.csv config/analysis_manifest.csv
dy-r produce_snv_concordances -p -k -j 10 --config genome_build=hg38 aligners=['strobe,'bwa2a'] dedupers=['dppl'] snv_callers=['oct','deep'] -n # dry run
dy-r produce_snv_concordances -p -k -j 10 --config genome_build=hg38 aligners=['strobe','bwa2a'] dedupers=['dppl'] snv_callers=['oct','deep']
max_snakemake_tasks_active_at_a_time=2 # for local headnode, maybe 400 for a full cluster
dy-r produce_snv_concordances produce_manta produce_tiddit produce_dysgu produce_kat produce_multiqc_final_wgs -p -k -j $max_snakemake_tasks_active_at_a_time --config genome_build=hg38 aligners=['strobe','bwa2a','sent'] dedupers=['dppl'] snv_callers=['oct','sentd','deep','clair3','lfq2'] sv_callers=['tiddit','manta','dysgu'] -nThe analysis_manifest.csv file is required to run the daylily pipeline. It should only be created via the helper script ./bin/daylily-analysis-samples-to-manifest.
this script is still in development, more docs to come, run with -h for now and see the example etc/analysis_samples.tsv template file for the format of the analysis_samples.tsv file. You also need to have a valid ephemeral cluster available.
Once jobs begin to be submitted, you can monitor from another shell on the headnode(or any compute node) with:
# The compute fleet, only nodes in state 'up' are running spots. 'idle' are defined pools of potential spots not bid on yet.
sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
i8* up infinite 12 idle~ i8-dy-gb64-[1-12]
i32 up infinite 24 idle~ i32-dy-gb64-[1-8],i32-dy-gb128-[1-8],i32-dy-gb256-[1-8]
i64 up infinite 16 idle~ i64-dy-gb256-[1-8],i64-dy-gb512-[1-8]
i96 up infinite 16 idle~ i96-dy-gb384-[1-8],i96-dy-gb768-[1-8]
i128 up infinite 28 idle~ i128-dy-gb256-[1-8],i128-dy-gb512-[1-10],i128-dy-gb1024-[1-10]
i192 up infinite 1 down# i192-dy-gb384-1
i192 up infinite 29 idle~ i192-dy-gb384-[2-10],i192-dy-gb768-[1-10],i192-dy-gb1536-[1-10]
# running jobs, usually reflecting all running node/spots as the spot teardown idle time is set to 5min default.
squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
1 i192 D-strobe ubuntu PD 0:00 1 (BeginTime)
# ST = PD is pending
# ST = CF is a spot has been instantiated and is being configured
# PD and CF sometimes toggle as the spot is configured and then begins running jobs.
squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
1 i192 D-strobe ubuntu R 5:09 1 i192-dy-gb384-1
# ST = R is running
# Also helpful
watch squeue
# also for the headnode
glancesYou can not access compute nodes directly, but can access them via the head node. From the head node, you can determine if there are running compute nodes with squeue, and use the node names to ssh into them.
ssh i192-dy-gb384-1warning: this will delete all resources created for the ephemeral cluster, importantly, including the fsx filesystem. You must export any analysis results created in /fsx/analysis_results from the fsx filesystem back to s3 before deleting the cluster.
- During cluster config, you will choose if Fsx and the EBS volumes auto-delete with cluster deletion. If you disable auto-deletion, these idle volumes can begin to cost a lot, so keep an eye on this if you opt for retaining on deletion.
Run:
./bin/daylily-export-fsx-to-s3 <cluster_name> <region> <export_path:analysis_results>- export_path should be
analysis_resultsor a subdirectory ofanalysis_results/*to export successfully. - The script will run, and report status until complete. If interrupted, the export will not be halted.
- You can visit the FSX console, and go to the Fsx filesystem details page to monitor the export status in the data repository tab.
- Go to the 'fsx' AWS console and select the filesystem for your cluster.
- Under the
Data Repositoriestab, select thefsxfilesystem and clickExport to S3. Export can only currently be carried out back to the same s3 which was mounted to the fsx filesystem. - Specify the export path as
analysis_results(or be more specific to ananalysis_results/subdir), the path you enter is named relative to the mountpoint of the fsx filesystem on the cluster head and compute nodes, which is/fsx/. Start the export. This can take 10+ min. When complete, confirm the data is now visible in the s3 bucket which was exported to. Once you confirm the export was successful, you can delete the cluster (which will delete the fsx filesystem).
note: this will not modify/delete the s3 bucket mounted to the fsx filesystem, nor will it delete the policyARN, or private/public subnets used to config the ephemeral cluster.
the headnode /root volume and the fsx filesystem will be deleted if not explicitly flagged to be saved -- be sure you have exported Fsx->S3 before deleting the cluster
pcluster delete-cluster-instances -n <cluster-name> --region us-west-2
pcluster delete-cluster -n <cluster-name> --region us-west-2- You can monitor the status of the cluster deletion using
pcluster list-clusters --region us-west-2and/orpcluster describe-cluster -n <cluster-name> --region us-west-2. Deletion can take ~10min depending on the complexity of resources created and fsx filesystem size.
... For real, use it!
(also, can be done via pcui)
bin/daylily-ssh-into-headnode
alias it for your shell: alias goday="source ~/git_repos/daylily/bin/daylily-ssh-into-headnode"
- The AWS Cloudwatch console can be used to monitor the cluster, and the resources it is using. This is a good place to monitor the health of the cluster, and in particular the slurm and pcluster logs for the headnode and compute fleet.
- Navigate to your
cloudwatchconsole, then selectdashboardsand there will be a dashboard named for the name you used for the cluster. Follow this link (be sure you are in theus-west-2region) to see the logs and metrics for the cluster. - Reports are not automaticaly created for spot instances, but you may extend this base report as you like. This dashboard is automatically created by
pclusterfor each new cluster you create (and will be deleted when the cluster is deleted).
Daylily relies on a variety of pre-built reference data and resources to run. These are stored in the daylily-references-public bucket. You will need to clone this bucket to a new bucket in your account, once per region you intend to operate in.
This is a design choice based on leveraging the
FSXfilesystem to mount the data to the cluster nodes. Reference data in this S3 bucket are auto-mounted an available to the head and all compute nodes (Fsx supports 10's of thousands of concurrent connections), further, as analysis completes on the cluster, you can choose to reflect data back to this bucket (and then stage elsewhere). Having these references pre-arranged aids in reproducibility and allows for the cluster to be spun up and down with negligible time required to move / create refernce data.
BONUS: the 7 giab google brain 30x ILMN read sets are included with the bucket to standardize benchmarking and concordance testing.
You may add / edit (not advised) / remove data (say, if you never need one of the builds, or don't wish to use the GIAB reads) to suit your needs.
Onetime cost of between ~$27 to ~$108 per region to create bucket.
monthly S3 standard cost of ~$14/month to continue hosting it.
- Size: 617.2GB, and contains 599 files.
- Source bucket region:
us-west-2 - Cost to store S3 (standard: $14.20/month, IA: $7.72/month, Glacier: $2.47 to $0.61/month)
- Data transfer costs to clone source bucket
- within us-west-2: ~$3.40
- to other regions: ~$58.00
- Accelerated transfer is used for the largest files, and adds ~$24.00 w/in
us-west-2and ~$50 across regions. - Cloning w/in
us-west-2will take ~2hr, and to other regions ~7hrs. - Moving data between this bucket and the FSX filesystem and back is not charged by size, but by number of objects, at a cost of
$0.005 per 1,000 PUT. The cost to move 599 objecsts back and forth once to Fsx is$0.0025(you do pay for Fsx when it is running, which is only when you choose to run analysus).
- Your new bucket name needs to end in
-omics-analysis-REGIONand be unique to your account. - One bucket must be created per
REGIONyou intend to run in. - The reference data version is currently
0.7, and will be replicated correctly using the script below. - The total size of the bucket will be 779.1GB, and the cost of standard S3 storage will be ~$30/mo.
- Copying the daylily-references-public bucket will take ~7hrs using the script below.
hg38andb37reference data files (including supporting tool specific files).- 7 google-brain ~
30xIllunina 2x150fastq.gzfiles for all 7 GIAB samples (HG001,HG002,HG003,HG004,HG005,HG006,HG007). - snv and sv truth sets (
v4.2.1) for all 7 GIAB samples in bothb37andhg38. - A handful of pre-built conda environments and docker images (for demonstration purposes, you may choose to add to your own instance of this bucket to save on re-building envs on new eclusters).
- A handful of scripts and config necessary for the ephemeral cluster to run.
note: you can choose to eliminate the data for b37 or hg38 to save on storage costs. In addition, you may choose to eliminate the GIAB fastq files if you do not intend to run concordance or benchmarking tests (which is advised against as this framework was developed explicitly to facilitate these types of comparisons in an ongoing way).
See the secion on shared Fsx filesystem for more on hos this bucket interacts with these ephemeral cluster region specific S3 buckets.
.
├── cluster_boot_config # used to configure the head and compute nodes in the ephemeral cluster, is not mounted to cluster nodes
└── data # this directory is mounted to the head and compute nodes under /fsx/data as READ-ONLY. Data added to the S3 bucket will become available to the fsx mount, but can not be written to via FSX
├── cached_envs
│ ├── conda
│ └── containers
├── genomic_data
│ ├── organism_annotations
│ │ └── H_sapiens
│ │ ├── b37
│ │ └── hg38
│ ├── organism_reads
│ │ └── H_sapiens
│ │ └── giab
│ └── organism_references
│ └── H_sapiens
│ ├── b37
│ └── hg38
└── tool_specific_resources
└── verifybam2
├── exome
└── test
Are region specific, and may only intereact with S3 buckets in the same region as the filesystem. There are region specific quotas to be aware of.
- Fsx filesystems are extraordinarily fast, massively scallable (both in IO operations as well as number of connections supported -- you will be hard pressed to stress this thing out until you have 10s of thousands of concurrent connected instances). It is also a pay-to-play product, and is only cost effective to run while in active use.
- Daylily uses a
scratchtype instance, which auto-mounts the region specifics3://PREFIX-omics-analysis-REGION/datadirectory to the fsx filesystem as/fsx/data./fsxis available to the head node and all compute nodes. - When you delete a cluster, the attached
Fsx Lustrefilesystem will be deleted as well. -
BE SURE YOU REFLECT ANALYSIS REUSLTS BACK TO S3 BEFORE DELETING YOUR EPHEMERAL CLUSTER ... do this via the Fsx dashboard and create a data export task to the same s3 bucket you used to seed the fsx filesystem ( you will probably wish to define exporting
analysis_results, which will export back tos3://PREFIX-omics-analysis-REGION/FSX-export-DATETIME/everything in/fsx/analysis_resultsto this new FSX-export directory. do not export the entire/fsxmount, this is not tested and might try to duplicate your reference data as well! ). This can take 10+ min to complete, and you can monitor the progress in the fsx dashboard & delete your cluster once the export is complete. - Fsx can only mount one s3 bucket at a time, the analysis_results data moved back to S3 via the export should be moved again to a final destination (w/in the same region ideally) for longer term storage.
- All of this handling of data is amendable to being automated, and if someone would like to add a cluster delete check which blocks deletion if there is unexported data still on /fsx, that would be awesome.
- Further, you may write to any path in
/fsxfrom any instance it is mounted to, except/fsx/datawhich is read only and will only update if data mounted from thes3://PREFIX-omics-analysis-REGION/datais added/deleted/updated (not advised).
The following directories are created and accessible via /fsx on the headnode and compute nodes.
/fsx/
├── analysis_results
│ ├── cromwell_executions ## in development
│ ├── daylily ## deprecated
│ └── ubuntu ## <<<< run all analyses here <<<<
├── data ## mounted to the s3 bucket PREFIX-omics-analysis-REGION/data
│ ├── cached_envs
│ ├── genomic_data
│ └── tool_specific_resources
├── miners ## experimental & disabled by default
├── resources
│ └── environments ## location of cached conda envs and docker images. so they are only created/pulled once per cluster lifetime.
├── scratch ## scratch space for high IO tools
└── tmp ## tmp used by slurm by default
- I have a demo lisc, and old working workflows (but they are ~2yrs out of date at this point). I will be updating these workflows and including them in the benchmarking results.
- The aligner is already included, but I have not been running it as my $ resources are v. limited.
- Rough draft script is running already, with best guesses for things like compute time per-x coverage, etc.
- The
daylilyrepo grew from an analysis pipeline, and has co-mingled the ephmeral cluster infrastructure (which is not tied to any particular pipeline orchestrator). Breaking it into 2 parts will make things more modular and easier to maintain.
- A branch has been started for this work, which is reasonably straightforward. Tasks include:
- The AWS parallel cluster slurm snakemake executor, pcluster-slurm is written, but needs some additional features and to be tested at scale.
- Migrate from the current
daylilyanalysis_manifest.csvto the snakemakev8.*config/samples/unitsformat (which is much cleaner than the current manifest). - The actual workflow files should need very little tweaking.
- Running Cromwell WDL's is in early stages, and preliminary & still lightly documented work can be found here ( using the https://github.com/wustl-oncology as starting workflows ).
Before getting into the cool informatics business going on, there is a boatload of complex ops systems running to manage EC2 spot instances, navigate spot markets, as well as mechanisms to monitor and observe all aspects of this framework. AWS ParallelCluster is the glue holding everything together, and deserves special thanks.
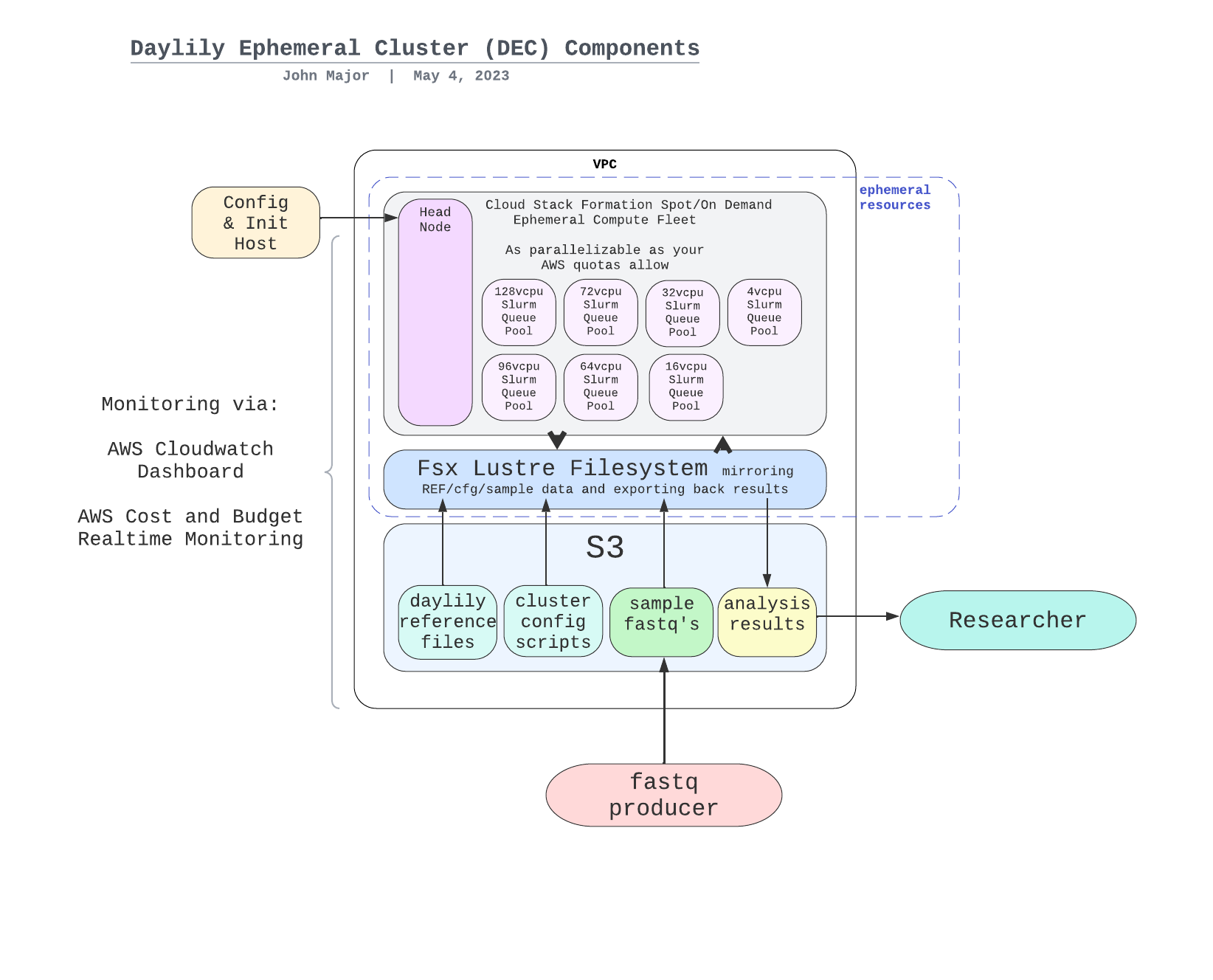
The system is designed to be robust, secure, auditable, and should only take a matter of days to stand up. Please contact me for further details.
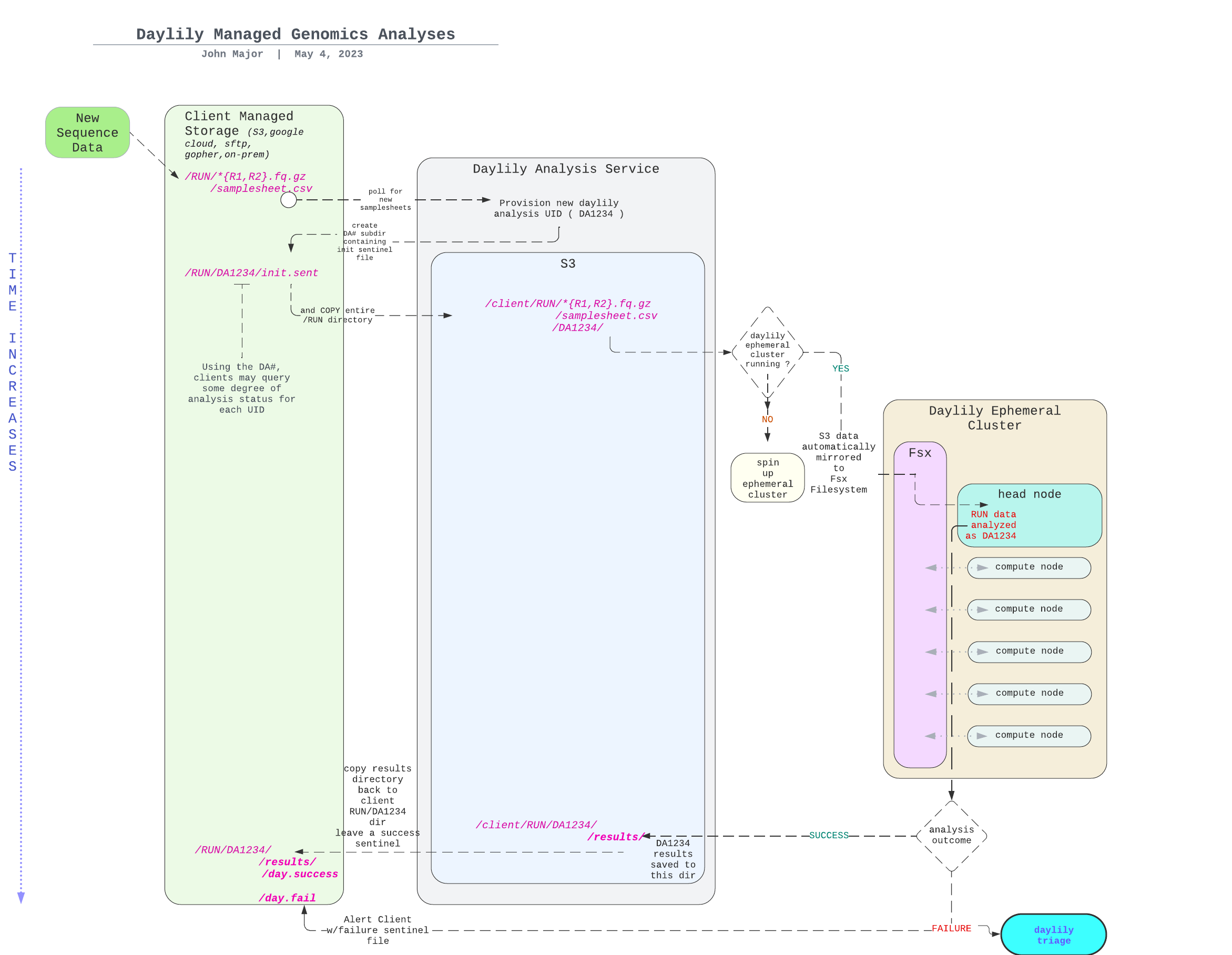
The DAG For 1 Sample Running Through The BWA-MEM2ert+Doppelmark+Deepvariant+Manta+TIDDIT+Dysgu+Svaba+QCforDays Pipeline
NOTE: each node in the below DAG is run as a self-contained job. Each job/n ode/rule is distributed to a suitable EC2 spot(or on demand if you prefer) instance to run. Each node is a packaged/containerized unit of work. This dag represents jobs running across sometimes thousands of instances at a time. Slurm and Snakemake manage all of the scaling, teardown, scheduling, recovery and general orchestration: cherry on top: killer observability & per project resource cost reporting and budget controls!

-
The above is actually a compressed view of the jobs managed for a sample moving through this pipeline. This view is of the dag which properly reflects parallelized jobs.


The batch is comprised of google-brain Novaseq 30x HG002 fastqs, and again downsampling to: 25,20,15,10,5x.
Example report.


- A visualization of just the directories (minus log dirs) created by daylily b37 shown, hg38 is supported as well

- [with files](docs/ops/tree_full.md
Reported faceted by: SNPts, SNPtv, INS>0-<51, DEL>0-51, Indel>0-<51. Generated when the correct info is set in the analysis_manifest.
Picture and list of tools





{kind=link}
To make informed decisions about choosing an analysis pipeline, there are four key metrics to consider: accuracy(as generally measured via Fscore), user run time, cost of analysis and reproducibility. Further consideration should then be given to the longevity of results (how results are stored, costs associated with storage, and the ease of access to results). All of these can not be optimized simultaneously, and trade-offs must be made. Making these tradeoffs with intention is the primary goal of the daylily framework.
- what is the pipelines perofrmance?
- how long does it take to run the pipeline?
- is
- is
- is
- is
- is
- what is the asserted reproducibility of the pipeline? For 1 month? 1 year? 5 years? 20 years?
- And how is this tested?
- how are results stored? What are the costs and access mechanisms for these results?
To activate sentieon bwa and sentieon DNA scope, edit the config/day_profiles/{local,slurm}/templates/rule_config.yaml file to uncomment the following:
active_snv_callers:
- deep
# - sentd
active_aligners:
- bwa2a:
mkdup: dppl
# - sent: # uncomment to run aligner (same deduper must be used presently in all aligner outputs, unless bundled into the align rule)
# mkdup: dppl # One ddup'r per analysis run. dppl and sent currently are active
# - strobe:
- This will enable running these two tools. You will also need a liscence file from sentieon in order to run these tools.
- Please contact them to obtain a valid liscense .
- Once you have a lisence file, edit the
dyinitfile to include the /fsx/ relative path to this file whereexport SENTIEON_LICENSE=is found. - Save the liscence file in the each region specific S3 reference bucket, ie:
s3://PREFIX-omics-analysis-REGION/data/cached_envs/. When this bucket is mounted to the fsx filesystem, the liscence file will be available to all instances at/fsx/data/cached_envs/.
Daylily uses Semantic Versioning. For the versions available, see the tags on this repository.
If the S3 bucket mounted to the FSX filesystem is too large (the default bucket is close to too large), this can cause Fsx to fail to create in time for pcluster, and pcluster time out fails. The wait time for pcluster is configured to be much longer than default, but this can still be a difficult to identify reason for cluster creation failure. Probability for failure increases with S3 bucket size, and also if the imported directories are being changed during pcluster creation. Try again, try with a longer timeount, and try with a smaller bucket (ie: remove one of the human reference build data sets, or move to a different location in the bucket not imported by Fsx)
The command bin/init_cloudstackformation.sh ./config/day_cluster/pcluster_env.yml "$res_prefix" "$region_az" "$region" $AWS_PROFILE does not yet gracefully handle being run >1x per region. The yaml can be edited to create the correct scoped resources for running in >1 AZ in a region (this all works fine when running in 1AZ in >1 regions), or you can manually create the pub/private subnets, etc for running in multiple AZs in a region. The fix is not difficult, but is not yet automated.
Is largely in your hands. AWS Parallel Cluster is as secure or insecure as you set it up to be. https://docs.aws.amazon.com/parallelcluster/v2/ug/security-compliance-validation.html
daylib: python library code. and: ...
named in honor of Margaret Oakley Dahoff