{kind=link}
{kind=link}
Daily Mental consists of an AI-powered application that will help you understand your feelings and thoughts but more importantly alert you in case of a serious issue to seek medical help.
With only a couple of seconds of your time each day, your mind will be put at ease knowing that our platform is analyzing your moods and behaviors and keeping track of any minor or major setbacks.
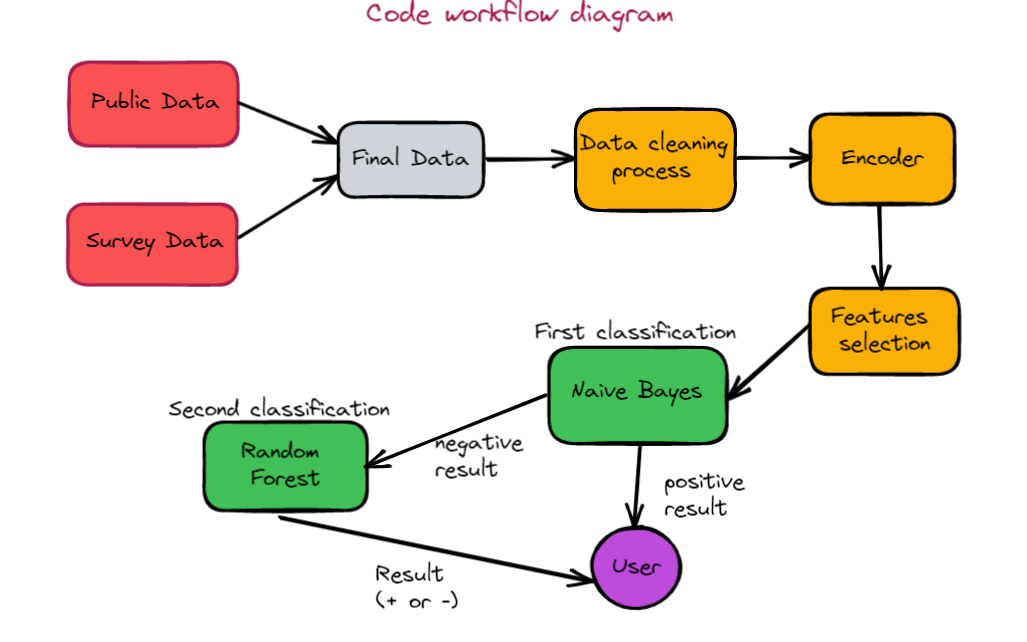
We will be using the following workflow:
We have 2 different datasets :
- Public Data from kaggle : https://www.kaggle.com/datasets/aditiharsh/mental-health-dataset
- Data collected from a survey via social media
We will start by preparing and cleaning each dataset than merge them together.
Then we will encode the resulting dataset.
Finnaly, we will analyze the weights of the features in the dataset through a HeatMap in order to select the features we will be using in our first Model.
We will thus obtain two files : data_for_model1.csv and data_for_model2.csv
After importing the file created previously, we will scale and split our dataset into train and test data with 80/20.
Then, we will build 6 different supervised ML models (Logistic Regression, Support Vector Machines, Decision Trees, Random Forest, Naive Bayes and K-Nearest Neighbors).
We will evaluate them by their recall because we want to correctly classify if a user may have a mental health issue.
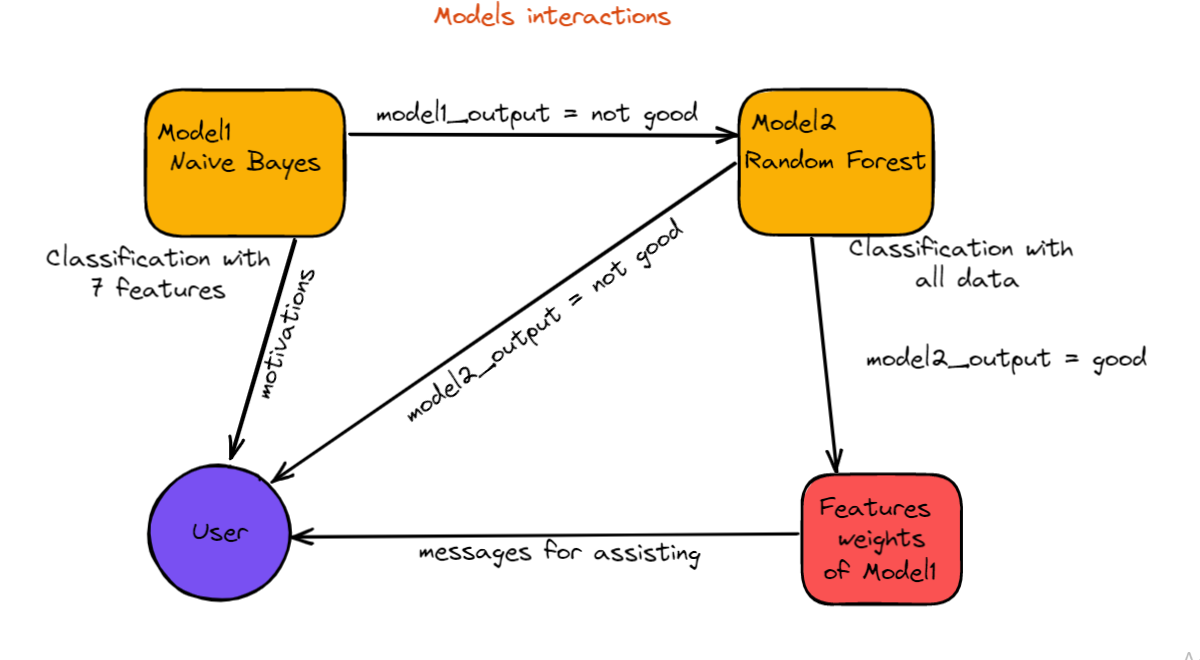
We ended up choosing Naive Bayes Model with 0.923 recall.
We will also build a DL model with 3 hidden layers. The model has 0.92 f1-score.
We decided to go with the Naive Bayes because we discovered that the DL Model is overfitting.
We will do the same steps as for the first model.
Here we decided to use the Random Forest Model with 0.928 recall.
We will also build a DL model with 3 hidden layers. The model has 0.9289 f1-score.
We will be using the Naive Bayes Model as the first Model then we will be using the Random Forest Model as our second model.