GitHub: https://github.com/HendrikStrobelt/miniClip
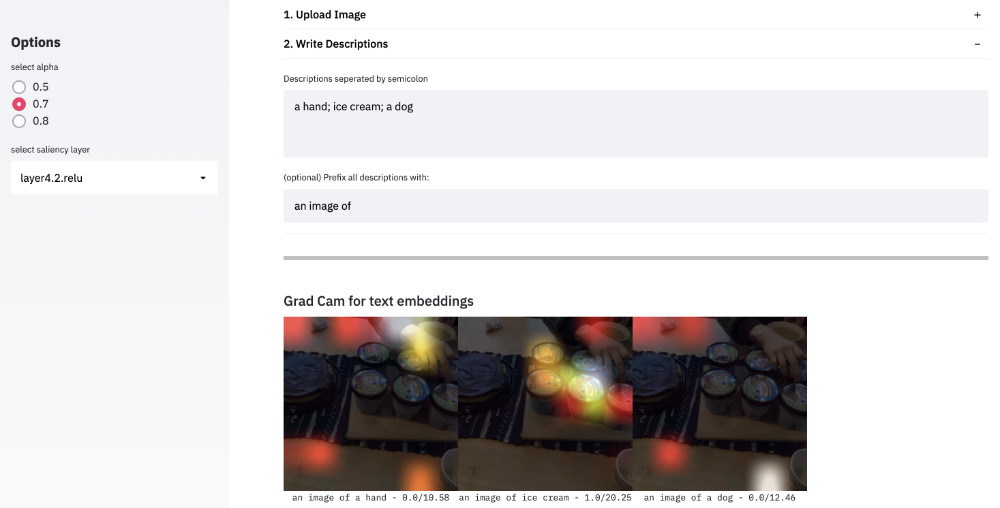
This demo app uses the OpenAI Clip (Resnet50) model. You can upload an image and test your text descriptions to observe:
- How similar are the embeddings of your descriptions to the image embeddings under the Clip model?
- What is the salience map when using the text-embeddings of your descriptions as logits for the image model part of Clip?
By playing around with the demo several observations can be made that enable more tangible access to the clip model.
Recently, a use case etsblished for Clip to use the model for zero-shot classification. Here we want to make the case that when you are in control of the description text it will become prevalent how close the relation to language models is. Synonyms or properties of objects have a similar response in the text embeddings which results in similar probability to the same image embedding. The example below shows how "wood" and "barrel" seem to trigger a similar response - not only in logits/softmax but also in saliency. The room below is full of items that all can be identified by saliency maps:

Another example of how well saliency maps capture the objects of interest. Even abstract descriptions like "covid 19 protection" seem to point towards the mask of the person in front.

Using a prime like "an image of" can change the similarity of close descriptions and image embeddings. The phrase "a barrel and a chair" without prefix seems is slightly more similar to the image embedding. The difference for "some clothes" with and without prefix are more significant. Independent of the prefix, the saliency maps seem to point to the same objects.

It seems that text labels on top of an images are dominant over image content. In the following example, we observe a very strong focus on the word "pharao" which is completely outside of the image context. Even small sub-phrases, like "ph" or "pha" already guide the saliency strictly towards the text label.

Here is an example to show how dominant text is - even in presence of visual objects of the same type in a scene image:

Trying to uncover how visual and textual embeddings merge into one amalgamation of modalities can be truly fascinating. Please clone the repo and try the demo on your GPU (or even CPU) machine.
To prepare environment and install dependencies:
$ git clone https://github.com/HendrikStrobelt/miniClip.git
$ cd miniClip
$ conda create -n miniclip python=3.8
$ conda activate miniclip
$ pip install -r requirements.txtand then run:
$ streamlit run app.py
Demo and text are created by Hendrik Strobelt who is the Explainability Lead at the MIT-IBM Watson AI Lab. Thanks go to David Bau who helped through great conversations and to the creators of streamlit and torchray for great open source software.
Please cite if you used the demo to generate novel hypothesis and ideas:
@misc{HenMiniClip2021,
author = {Strobelt, Hendrik},
title = {MiniClip},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/HendrikStrobelt/miniClip}}
}MiniClip uses an Apache 2 License. A list of dependencies can be found here.