{kind=link}
在学习大学英语、阅读英文文献的时候,大量的生词是影响阅读效率的一大因素。一个一个地查阅生词是一个极其繁琐的事情,这将会耗费大量时间,严重影响学习效率。正是有如此的困扰,我想实现一个功能:我在txt文件里一次性输入所有我需要查阅的生词,Python来自动给我查阅完成并形成一个pdf文件。这个仓库就是实现这个功能的。
使用这个脚本需要一定的python基础知识,至少你要会使用pip或conda安装一些库。这个脚本对python的要求有:
python 3pylatexurllibhtmllxml
除了Python3和这些库,请在电脑里安装texlive。如果你并没有安装texlive,请不要直接生成pdf文件,否则会报错。没有安装texlive的朋友,可以选择生成tex文件,然后在overleaf网站上上传并编译这个tex文件就能获得相应的pdf文件了。
-
- 请下载这个仓库;
-
- 请在
Words and Notebooks文件夹下创建一个文件夹,并记住文件夹名,比如“College English”、“CET-6”等。最好不要夹杂中文。
- 请在
-
- 在上面创建的这个文件夹下创建一个
.txt文件,这是你之后写生词的文件;
- 在上面创建的这个文件夹下创建一个
-
- 在这个txt文件里输入你要查的生词,每一个生词之间用一个逗号隔开,注意使用英文逗号。
-
- 使用编辑器打开
main.py。注意是编辑器,可以是记事本或者IDLE。
- 使用编辑器打开
-
- 修改
main.py的第13行和第14行的代码。将第二步创建的文件名赋给变量foldname,将第三步创建的txt文件名付给变量filename。filename一定包括拓展名.txt.
- 修改
-
- 保存修改并运行
main.py。
- 保存修改并运行
-
- 在foldname下就能找到需要的
pdf文件或tex文件了。
- 在foldname下就能找到需要的
-
- 如果你的电脑里没有安装texlive,请生成
tex文件。将生成的文件上传到overleaf编译,生成pdf文件。具体操作请自行百度。
- 如果你的电脑里没有安装texlive,请生成
如图,左边是形成的LaTeX文本,右边是编译后的pdf文件
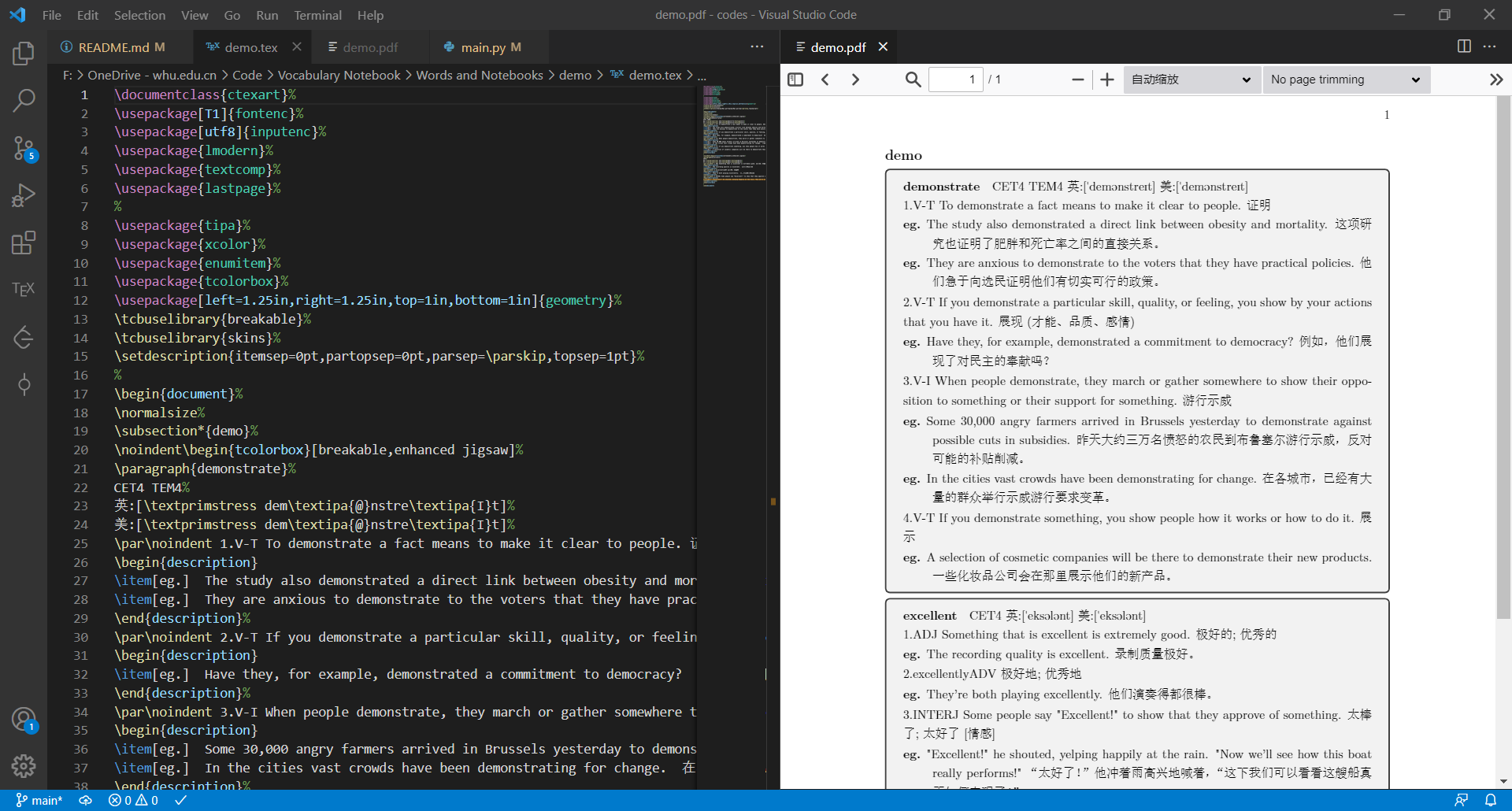
在get_word.py里面对HTML文件的解析是一步一步试出来,这是因为本人还没有去学习正则表达式,不能运用这一工具来解决。我希望后面会改进这一部分内容。本人水平有限,程序中有很多粗鄙的地方,欢迎各种友善意见。
[1] 如何利用Python + Latex完成每日实验记录?https://zhuanlan.zhihu.com/p/364018866
[2] 利用PYTHON 爬虫爬出自己的英语单词库.https://www.jianshu.com/p/8a93198316ed
[3] 使用LaTeX编辑英文国际音标.https://zhuanlan.zhihu.com/p/199284523