Update dependency vllm to v0.8.5 [SECURITY] #2
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
This PR contains the following updates:
==0.6.3.post1->==0.8.5GitHub Vulnerability Alerts
CVE-2025-24357
Description
The vllm/model_executor/weight_utils.py implements hf_model_weights_iterator to load the model checkpoint, which is downloaded from huggingface. It use torch.load function and weights_only parameter is default value False. There is a security warning on https://pytorch.org/docs/stable/generated/torch.load.html, when torch.load load a malicious pickle data it will execute arbitrary code during unpickling.
Impact
This vulnerability can be exploited to execute arbitrary codes and OS commands in the victim machine who fetch the pretrained repo remotely.
Note that most models now use the safetensors format, which is not vulnerable to this issue.
References
CVE-2025-25183
Summary
Maliciously constructed prompts can lead to hash collisions, resulting in prefix cache reuse, which can interfere with subsequent responses and cause unintended behavior.
Details
vLLM's prefix caching makes use of Python's built-in hash() function. As of Python 3.12, the behavior of hash(None) has changed to be a predictable constant value. This makes it more feasible that someone could try exploit hash collisions.
Impact
The impact of a collision would be using cache that was generated using different content. Given knowledge of prompts in use and predictable hashing behavior, someone could intentionally populate the cache using a prompt known to collide with another prompt in use.
Solution
We address this problem by initializing hashes in vllm with a value that is no longer constant and predictable. It will be different each time vllm runs. This restores behavior we got in Python versions prior to 3.12.
Using a hashing algorithm that is less prone to collision (like sha256, for example) would be the best way to avoid the possibility of a collision. However, it would have an impact to both performance and memory footprint. Hash collisions may still occur, though they are no longer straight forward to predict.
To give an idea of the likelihood of a collision, for randomly generated hash values (assuming the hash generation built into Python is uniformly distributed), with a cache capacity of 50,000 messages and an average prompt length of 300, a collision will occur on average once every 1 trillion requests.
References
CVE-2025-29770
Impact
The outlines library is one of the backends used by vLLM to support structured output (a.k.a. guided decoding). Outlines provides an optional cache for its compiled grammars on the local filesystem. This cache has been on by default in vLLM. Outlines is also available by default through the OpenAI compatible API server.
The affected code in vLLM is vllm/model_executor/guided_decoding/outlines_logits_processors.py, which unconditionally uses the cache from outlines. vLLM should have this off by default and allow administrators to opt-in due to the potential for abuse.
A malicious user can send a stream of very short decoding requests with unique schemas, resulting in an addition to the cache for each request. This can result in a Denial of Service if the filesystem runs out of space.
Note that even if vLLM was configured to use a different backend by default, it is still possible to choose outlines on a per-request basis using the
guided_decoding_backendkey of theextra_bodyfield of the request.This issue applies to the V0 engine only. The V1 engine is not affected.
Patches
The fix is to disable this cache by default since it does not provide an option to limit its size. If you want to use this cache anyway, you may set the
VLLM_V0_USE_OUTLINES_CACHEenvironment variable to1.Workarounds
There is no way to workaround this issue in existing versions of vLLM other than preventing untrusted access to the OpenAI compatible API server.
References
GHSA-ggpf-24jw-3fcw
Description
GHSA-rh4j-5rhw-hr54 reported a vulnerability where loading a malicious model could result in code execution on the vllm host. The fix applied to specify
weights_only=Trueto calls totorch.load()did not solve the problem prior to PyTorch 2.6.0.PyTorch has issued a new CVE about this problem: GHSA-53q9-r3pm-6pq6
This means that versions of vLLM using PyTorch before 2.6.0 are vulnerable to this problem.
Background Knowledge
When users install VLLM according to the official manual

But the version of PyTorch is specified in the requirements. txt file
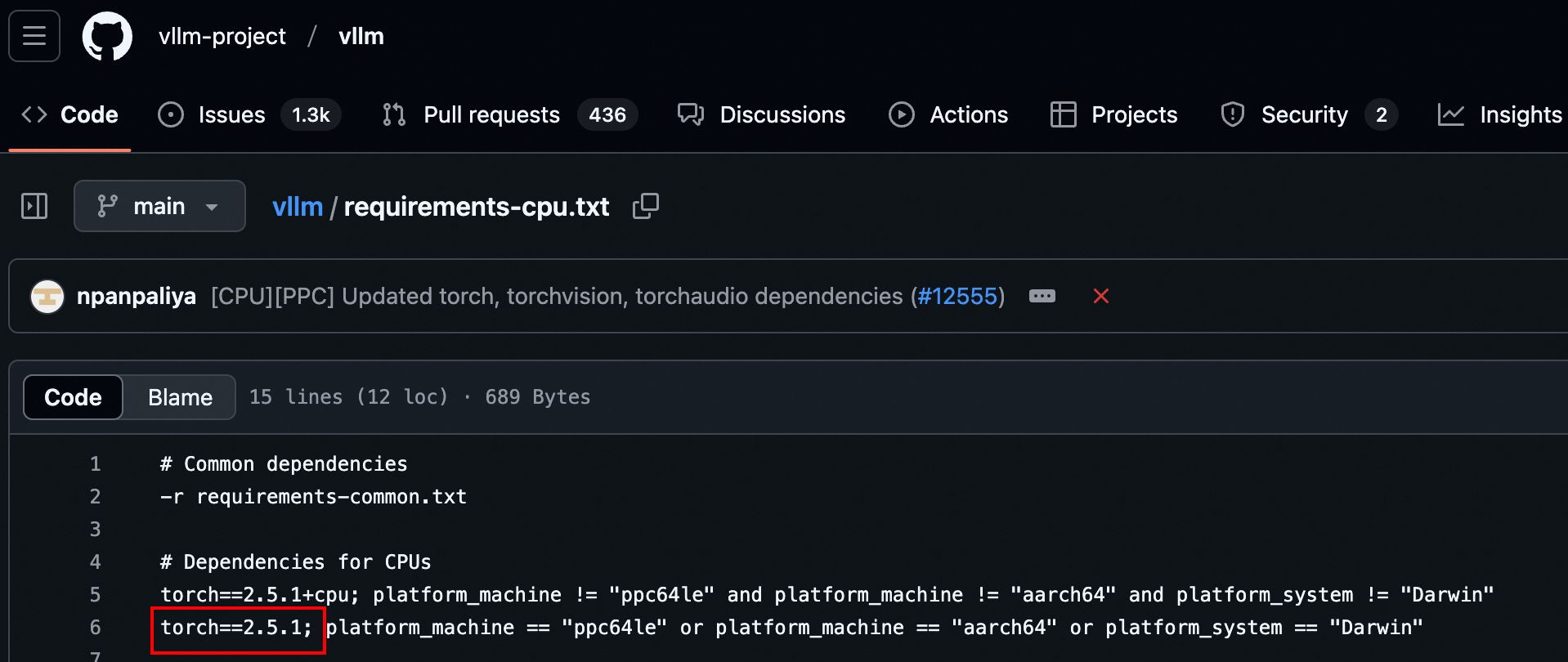
So by default when the user install VLLM, it will install the PyTorch with version 2.5.1

In CVE-2025-24357, weights_only=True was used for patching, but we know this is not secure.
Because we found that using Weights_only=True in pyTorch before 2.5.1 was unsafe
Here, we use this interface to prove that it is not safe.

Fix
update PyTorch version to 2.6.0
Credit
This vulnerability was found By Ji'an Zhou and Li'shuo Song
CVE-2025-30202
Impact
In a multi-node vLLM deployment, vLLM uses ZeroMQ for some multi-node communication purposes. The primary vLLM host opens an
XPUBZeroMQ socket and binds it to ALL interfaces. While the socket is always opened for a multi-node deployment, it is only used when doing tensor parallelism across multiple hosts.Any client with network access to this host can connect to this
XPUBsocket unless its port is blocked by a firewall. Once connected, these arbitrary clients will receive all of the same data broadcasted to all of the secondary vLLM hosts. This data is internal vLLM state information that is not useful to an attacker.By potentially connecting to this socket many times and not reading data published to them, an attacker can also cause a denial of service by slowing down or potentially blocking the publisher.
Detailed Analysis
The
XPUBsocket in question is created here:https://github.com/vllm-project/vllm/blob/c21b99b91241409c2fdf9f3f8c542e8748b317be/vllm/distributed/device_communicators/shm_broadcast.py#L236-L237
Data is published over this socket via
MessageQueue.enqueue()which is called byMessageQueue.broadcast_object():https://github.com/vllm-project/vllm/blob/790b79750b596043036b9fcbee885827fdd2ef3d/vllm/distributed/device_communicators/shm_broadcast.py#L452-L453
https://github.com/vllm-project/vllm/blob/790b79750b596043036b9fcbee885827fdd2ef3d/vllm/distributed/device_communicators/shm_broadcast.py#L475-L478
The
MessageQueue.broadcast_object()method is called by theGroupCoordinator.broadcast_object()method inparallel_state.py:https://github.com/vllm-project/vllm/blob/790b79750b596043036b9fcbee885827fdd2ef3d/vllm/distributed/parallel_state.py#L364-L366
The broadcast over ZeroMQ is only done if the
GroupCoordinatorwas created withuse_message_queue_broadcasterset toTrue:https://github.com/vllm-project/vllm/blob/790b79750b596043036b9fcbee885827fdd2ef3d/vllm/distributed/parallel_state.py#L216-L219
The only case where
GroupCoordinatoris created withuse_message_queue_broadcasteris the coordinator for the tensor parallelism group:https://github.com/vllm-project/vllm/blob/790b79750b596043036b9fcbee885827fdd2ef3d/vllm/distributed/parallel_state.py#L931-L936
To determine what data is broadcasted to the tensor parallism group, we must continue tracing.
GroupCoordinator.broadcast_object()is called byGroupCoordinator.broadcoast_tensor_dict():https://github.com/vllm-project/vllm/blob/790b79750b596043036b9fcbee885827fdd2ef3d/vllm/distributed/parallel_state.py#L489
which is called by
broadcast_tensor_dict()incommunication_op.py:https://github.com/vllm-project/vllm/blob/790b79750b596043036b9fcbee885827fdd2ef3d/vllm/distributed/communication_op.py#L29-L34
If we look at
_get_driver_input_and_broadcast()in the V0worker_base.py, we'll see how this tensor dict is formed:https://github.com/vllm-project/vllm/blob/790b79750b596043036b9fcbee885827fdd2ef3d/vllm/worker/worker_base.py#L332-L352
but the data actually sent over ZeroMQ is the
metadata_listportion that is split from thistensor_dict. The tensor parts are sent viatorch.distributedand only metadata about those tensors is sent via ZeroMQ.https://github.com/vllm-project/vllm/blob/54a66e5fee4a1ea62f1e4c79a078b20668e408c6/vllm/distributed/parallel_state.py#L61-L83
Patches
Workarounds
Prior to the fix, your options include:
XPUBsocket. Note that port used is random.References
Release Notes
vllm-project/vllm (vllm)
v0.8.5Compare Source
This release contains 310 commits from 143 contributors (55 new contributors!).
Highlights
This release features important multi-modal bug fixes, day 0 support for Qwen3, and xgrammar's structure tag feature for tool calling.
Model Support
V1 Engine
structural_tagsupport using xgrammar (#17085)Features
v1/audio/transcriptionsendpoint (#16591)vllm bench [latency, throughput]CLI commands (#16508)Performance
Hardwares
Documentation
Security and Dependency Updates
Build and testing
Breaking changes 🚨
--enable-chunked-prefill,--multi-step-stream-outputs,--disable-chunked-mm-inputcan no longer explicitly be set toFalse. Instead, addno-to the start of the argument (i.e.--enable-chunked-prefilland--no-enable-chunked-prefill) (https://github.com/vllm-project/vllm/pull/16533)What's Changed
SchedulerConfigby @hmellor in https://github.com/vllm-project/vllm/pull/16533max-num-batched-tokensis not a power of 2 by @NickLucche in https://github.com/vllm-project/vllm/pull/16596pyzmqversion by @taneem-ibrahim in https://github.com/vllm-project/vllm/pull/16549vllm bench [latency, throughput]CLI commands by @mgoin in https://github.com/vllm-project/vllm/pull/16508compressed-tensorsWNA16 to support zero-points by @dsikka in https://github.com/vllm-project/vllm/pull/14211backend_xgrammar.pyby @shen-shanshan in https://github.com/vllm-project/vllm/pull/16578additional_dependencies: [toml]for pre-commit yapf hook by @yankay in https://github.com/vllm-project/vllm/pull/16405TokenizerPoolConfig+DeviceConfigby @hmellor in https://github.com/vllm-project/vllm/pull/16603max-num-batched-tokensis not even by @NickLucche in https://github.com/vllm-project/vllm/pull/16726--compilation-configby @DarkLight1337 in https://github.com/vllm-project/vllm/pull/16729_validate_structured_output()by @shen-shanshan in https://github.com/vllm-project/vllm/pull/16748MultiModalConfig+PoolerConfig+DecodingConfigby @hmellor in https://github.com/vllm-project/vllm/pull/16789nullable_kvsfallback by @hmellor in https://github.com/vllm-project/vllm/pull/16837v1/audio/transcriptionsendpoint by @NickLucche in https://github.com/vllm-project/vllm/pull/16591CacheConfigby @hmellor in https://github.com/vllm-project/vllm/pull/16835_update_statesfor GPU model runner by @SnowCharmQ in https://github.com/vllm-project/vllm/pull/16910SpeculativeConfigby @hmellor in https://github.com/vllm-project/vllm/pull/16971collective_rpctimeout by @njhill in https://github.com/vllm-project/vllm/pull/17000tests/kernels/based on kernel type by @mgoin in https://github.com/vllm-project/vllm/pull/16799pidpassed tokill_process_treeisintformypyby @hmellor in https://github.com/vllm-project/vllm/pull/17051Configuration
📅 Schedule: Branch creation - "" (UTC), Automerge - At any time (no schedule defined).
🚦 Automerge: Disabled by config. Please merge this manually once you are satisfied.
♻ Rebasing: Whenever PR becomes conflicted, or you tick the rebase/retry checkbox.
🔕 Ignore: Close this PR and you won't be reminded about this update again.
This PR was generated by Mend Renovate. View the repository job log.