{kind=link}
A mini-project to make a deep RL agent to play pong in the openAI gym. This was made in the summer school CCNSS.
Training of the RL agent using policy gradients.
Trainig was done in OpenAI Gym environment with Python 2.7
Used packages:
- OpenAI Gym
- Keras (TF backend)

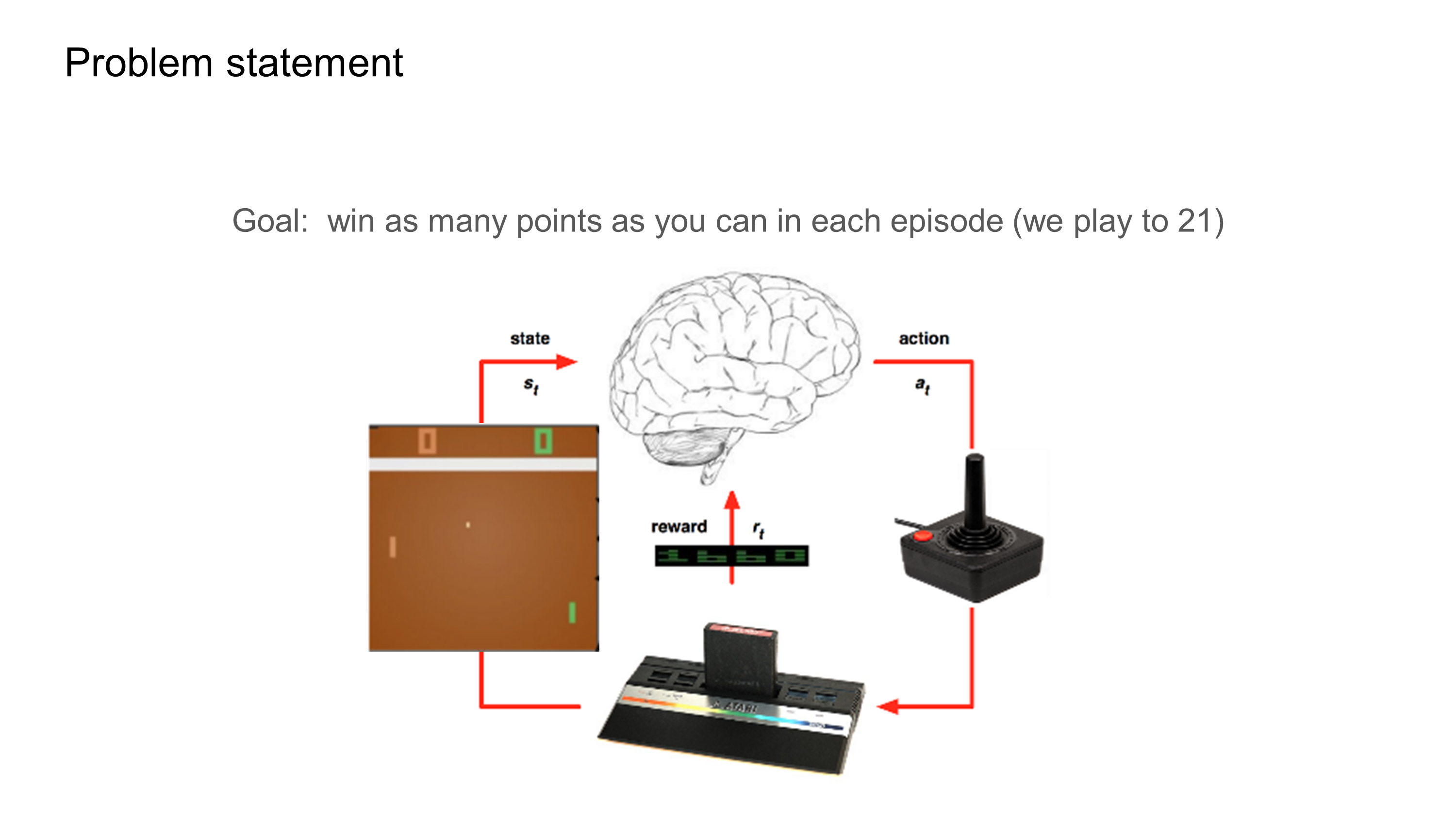 We would like to train an RL agent to win at Pong game
We would like to train an RL agent to win at Pong game
 A. Karpathy introduced a policy gradient algorith for training an RL agent. The agent learns by processing pixel information from each frame of the game. The optimal policy (prob(action|image)) is calculated by adding a reward function to the neural network gradient.
A. Karpathy introduced a policy gradient algorith for training an RL agent. The agent learns by processing pixel information from each frame of the game. The optimal policy (prob(action|image)) is calculated by adding a reward function to the neural network gradient.
 As an alternative to policy gradients we looked at the deep Q-learning algorithm.
As an alternative to policy gradients we looked at the deep Q-learning algorithm.
 One of our best models (Policy gradient, MLP 1 hidden layer, 200 hidden units, relu activation) learnt to beat the built-in AI agent in OpenAI Pong environment.
One of our best models (Policy gradient, MLP 1 hidden layer, 200 hidden units, relu activation) learnt to beat the built-in AI agent in OpenAI Pong environment.
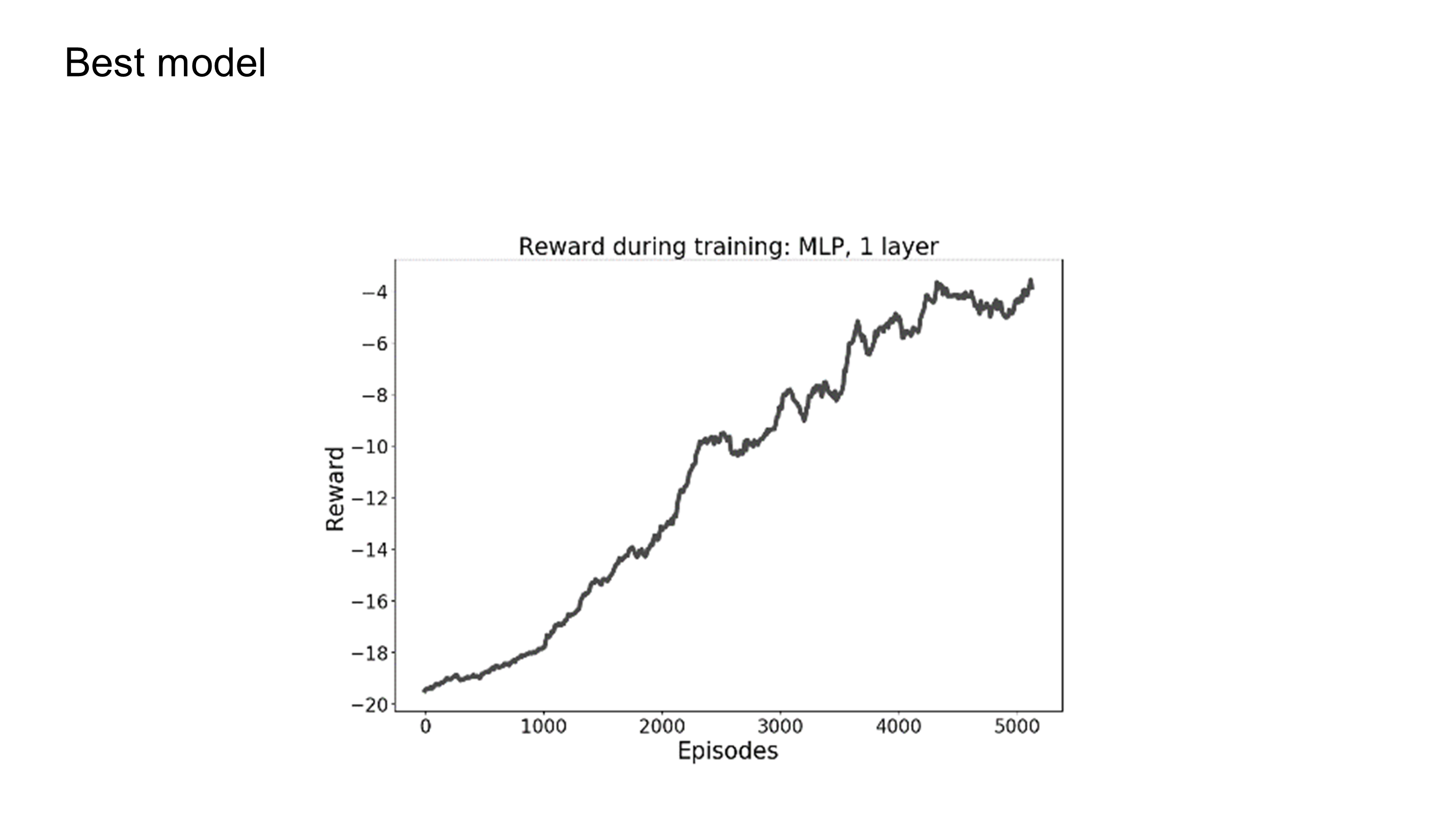 The policy gradient model was trained on ~5000 episodes and almost reached 0-reward.
The policy gradient model was trained on ~5000 episodes and almost reached 0-reward.
 We did some preliminary model comparison and observed that shallower models (1-layer) converged faster (final performance subject to number of training episodes). We also saw that policy gradient training resulted in faster and more graduate training compared to deep Q-learning.
We did some preliminary model comparison and observed that shallower models (1-layer) converged faster (final performance subject to number of training episodes). We also saw that policy gradient training resulted in faster and more graduate training compared to deep Q-learning.
 Our final note concerned GPU vs CPU computational time differences. We report that smaller networks are trained faster on a CPU unit.
Our final note concerned GPU vs CPU computational time differences. We report that smaller networks are trained faster on a CPU unit.