

Scrapping the movie review ✏️ using python programming language💻.
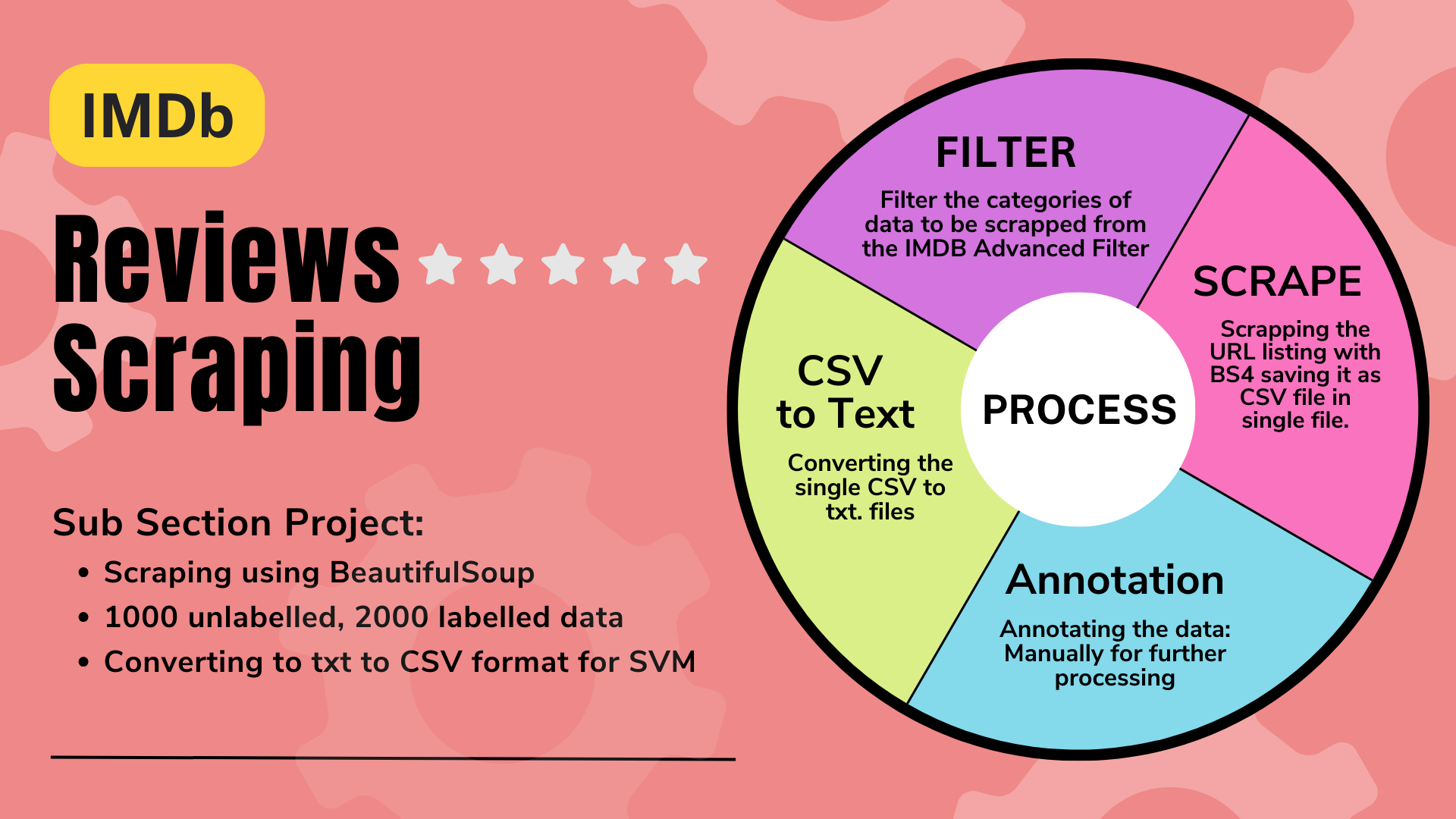
🔍Welcome to the IMDb Movie Review Scraper project! 🌟 This Python script is designed to scrape movie reviews from IMDb, providing valuable data for analysis and research purposes. The IMDb Movie Review Scraping project aims to gather a new dataset by automatically extracting movie reviews from IMDb. This dataset will support various natural language processing tasks, including sentiment analysis and recommendation systems. Using web scraping techniques, such as Beautiful Soup, movie reviews are collected, preprocessed, and structured into a CSV format suitable for analysis, including Support Vector Machine classification. 📈
Semi-supervised-sequence-learning-Project : replication process is done over here and for further analysis creation of new data is required.
- Scraping Movie Reviews 🕵️♂️
Movie_review_imdb_scrapping.ipynb- The script fetches user reviews from IMDb, providing access to a diverse range of opinions and feedback for different movies. It utilizes BeautifulSoup, a powerful Python library for web scraping, to extract data from IMDb's web pages efficiently and accurately. 🎥🔎
- Customizable Scraper 🛠️
rename_files.ipynb- Users can customize the scraper to target specific time periods, ratings, and other parameters, enabling focused data collection based on their requirements. This flexibility allows researchers, analysts, and enthusiasts to tailor the scraping process to their specific needs.

- CSV Output 📁
convert_texts_to_csv.ipynb- The scraped data is saved into a CSV file, allowing for easy import into data analysis software or further processing. The CSV format ensures compatibility with a wide range of tools and platforms, making it convenient to incorporate the scraped data into various workflows and projects. 💾💼
Dependencies
Make sure you have the following dependencies installed:
- Python 3.x
- BeautifulSoup (Install using
pip install beautifulsoup4 - Pandas (Install using
pip install pandas
Installation
-
Fork the
Semi-supervised-sequence-learning-Project/repository Link to `Semi-supervised-sequence-learning-Project' Follow these instructions on how to fork a repository -
Clone the Repository to your local machine
- using SSH:
git clone git@github.com:your-username/Semi-supervised-sequence-learning-Project.git - Or using HTTPS:
git clone https://github.com/your-username/Semi-supervised-sequence-learning-Project.git
- using SSH:
-
Navigate to the project directory.
cd Semi-supervised-sequence-learning-Project
Starting the Streamlit app
- Navigate to the Web_app directory
cd Web_app
- Install requirements with pip
pip install -r requirements.txt
- Run the Streamlit app
streamlit run streamlit_app.py
Uploading the CSV file
When prompted by the app, upload a CSV (comma separated value) file containing the reviews.
Demo Link
Streamlit app link: https://scrape-review-analysis.streamlit.app



{kind=link}
{kind=link}
{kind=link}
🔬Here is the Link to Final Dataset: Drive Link containing the scraped IMDb movie reviews. This dataset can be used for analysis, research, or any other purposes you require. 📦
