An extension of AiCoverGen, which provides several new features and improvements, enabling users to generate song covers using RVC with ease. Ideal for people who want to incorporate singing functionality into their AI assistant/chatbot/vtuber, or for people who want to hear their favourite characters sing their favourite song.

Ultimate RVC is under constant development and testing, but you can try it out right now locally or on Google Colab!
- Easy and automated setup using launcher scripts for both windows and Debian-based linux systems
- Caching system which saves intermediate audio files as needed, thereby reducing inference time as much as possible. For example, if song A has already been converted using model B and now you want to convert song A using model C, then vocal extraction can be skipped and inference time reduced drastically
- Ability to listen to intermediate audio files in the UI. This is useful for getting an idea of what is happening in each step of the song cover generation pipeline
- A "multi-step" song cover generation tab: here you can try out each step of the song cover generation pipeline in isolation. For example, if you already have extracted vocals available and only want to convert these using your voice model, then you can do that here. Besides, this tab is useful for experimenting with settings for each step of the song cover generation pipeline
- An overhaul of the song input component for the song cover generation pipeline. Now cached input songs can be selected from a dropdown, so that you don't have to supply the Youtube link of a song each time you want to convert it.
- A new "manage models" tab, which collects and revamps all existing functionality for managing voice models, as well as adds some new features, such as the ability to delete existing models
- A new "manage audio" tab, which allows you to interact with all audio generated by the app. Currently, this tab supports deleting audio files.
- Lots of visual and performance improvements resulting from updating from Gradio 3 to Gradio 4 and from python 3.9 to python 3.12
For those without a powerful enough NVIDIA GPU, you may try Ultimate RVC out using Google Colab.
For those who want to run the Ultimate RVC project locally, follow the setup guide below.
The Ultimate RVC project currently supports Windows and Debian-based Linux distributions, namely Ubuntu 22.04 and Ubuntu 24.04. Support for other platforms is not guaranteed.
To setup the project follow the steps below and execute the provided commands in an appropriate terminal. On windows this terminal should be powershell, while on Debian-based linux distributions it should be a bash-compliant shell.
Follow the instructions here to install Git on your computer.
To execute the subsequent commands on Windows, it is necessary to first grant powershell permission to run scripts. This can be done at a user level as follows:
Set-ExecutionPolicy RemoteSigned -Scope CurrentUsergit clone https://github.com/JackismyShephard/ultimate-rvc
cd ultimate-rvc./urvc install Note that on Linux, this command will install the CUDA 12.4 toolkit system-wide, if it is not already available. In case you have problems, you may need to install the toolkit manually.
./urvc runOnce the following output message Running on local URL: http://127.0.0.1:7860 appears, you can click on the link to open a tab with the web app.
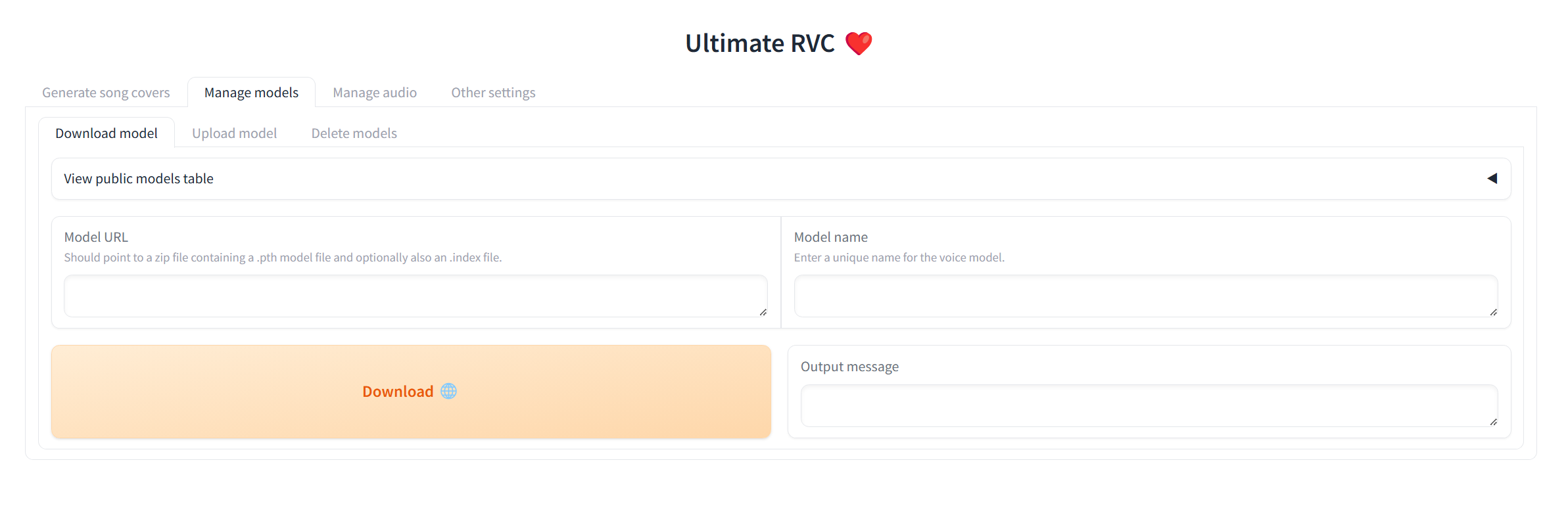
Navigate to the Download model subtab under the Manage models tab, and paste the download link to an RVC model and give it a unique name.
You may search the AI Hub Discord where already trained voice models are available for download.
The downloaded zip file should contain the .pth model file and an optional .index file.
Once the 2 input fields are filled in, simply click Download! Once the output message says [NAME] Model successfully downloaded!, you should be able to use it in the Generate song covers tab!
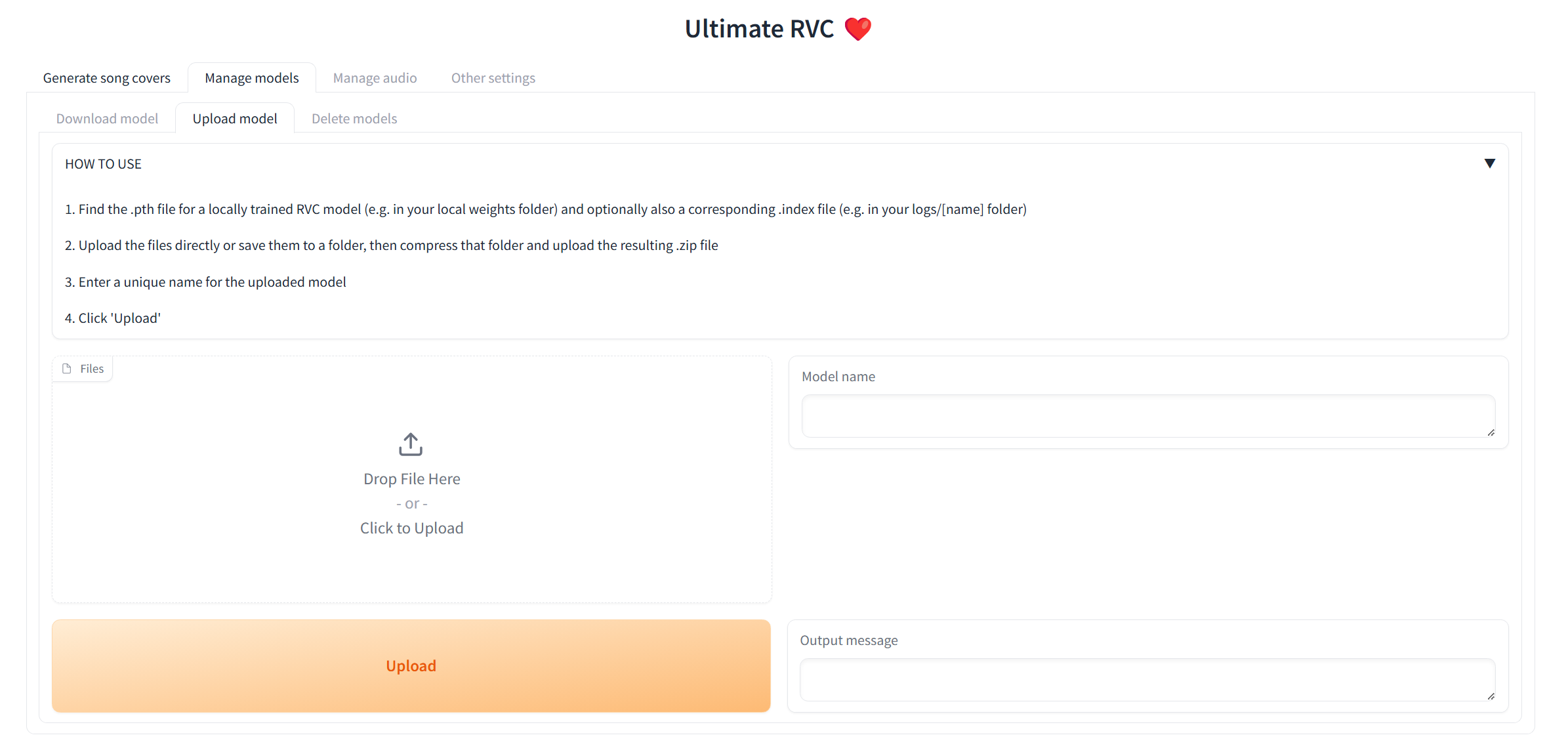
For people who have trained RVC v2 models locally and would like to use them for AI cover generations.
Navigate to the Upload model subtab under the Manage models tab, and follow the instructions.
Once the output message says Model with name [NAME] successfully uploaded!, you should be able to use it in the Generate song covers tab!
TBA
- From the Voice model dropdown menu, select the voice model to use.
- In the song input field, copy and paste the link to any song on YouTube, the full path to a local audio file, or select a cached input song.
- Pitch should be set to either -12, 0, or 12 depending on the original vocals and the RVC AI modal. This ensures the voice is not out of tune.
- Other advanced options for vocal conversion, audio mixing and etc. can be viewed by clicking the appropriate accordion arrow to expand.
Once all options are filled in, click Generate and the AI generated cover should appear in a less than a few minutes depending on your GPU.
TBA
Unzip (if needed) and transfer the .pth and .index files to a new folder in the rvc models directory. Each folder should only contain one .pth and one .index file.
The directory structure should look something like this:
├── models
| ├── audio_separator
| ├── rvc
│ ├── John
│ │ ├── JohnV2.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ ├── May
│ │ ├── May.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ └── hubert_base.pt
├── notebooks
├── notes
└── src
./urvc cli song-cover run-pipeline [OPTIONS] SOURCE MODEL_NAME SOURCE: A Youtube URL, the path to a local audio file or the path to a song directory. [required]MODEL_NAME: The name of the voice model to use for vocal conversion. [required]
--n-octaves INTEGER: The number of octaves to pitch-shift the converted vocals by.Use 1 for male-to-female and -1 for vice-versa. [default: 0]--n-semitones INTEGER: The number of semi-tones to pitch-shift the converted vocals, instrumentals, and backup vocals by. Altering this slightly reduces sound quality [default: 0]--f0-method [rmvpe|mangio-crepe]: The method to use for pitch detection during vocal conversion. Best option is RMVPE (clarity in vocals), then Mangio-Crepe (smoother vocals). [default: rmvpe]--index-rate FLOAT RANGE: A decimal number e.g. 0.5, Controls how much of the accent in the voice model to keep in the converted vocals. Increase to bias the conversion towards the accent of the voice model. [default: 0.5; 0<=x<=1]--filter-radius INTEGER RANGE: A number between 0 and 7. If >=3: apply median filtering to the pitch results harvested during vocal conversion. Can help reduce breathiness in the converted vocals. [default: 3; 0<=x<=7]--rms-mix-rate FLOAT RANGE: A decimal number e.g. 0.25. Controls how much to mimic the loudness of the input vocals (0) or a fixed loudness (1) during vocal conversion. [default: 0.25; 0<=x<=1]--protect FLOAT RANGE: A decimal number e.g. 0.33. Controls protection of voiceless consonants and breath sounds during vocal conversion. Decrease to increase protection at the cost of indexing accuracy. Set to 0.5 to disable. [default: 0.33; 0<=x<=0.5]--hop-length INTEGER: Controls how often the CREPE-based pitch detection algorithm checks for pitch changes during vocal conversion. Measured in milliseconds. Lower values lead to longer conversion times and a higher risk of voice cracks, but better pitch accuracy. Recommended value: 128. [default: 128]--room-size FLOAT RANGE: The room size of the reverb effect applied to the converted vocals. Increase for longer reverb time. Should be a value between 0 and 1. [default: 0.15; 0<=x<=1]--wet-level FLOAT RANGE: The loudness of the converted vocals with reverb effect applied. Should be a value between 0 and 1 [default: 0.2; 0<=x<=1]--dry-level FLOAT RANGE: The loudness of the converted vocals wihout reverb effect applied. Should be a value between 0 and 1. [default: 0.8; 0<=x<=1]--damping FLOAT RANGE: The absorption of high frequencies in the reverb effect applied to the converted vocals. Should be a value between 0 and 1. [default: 0.7; 0<=x<=1]--main-gain INTEGER: The gain to apply to the post-processed vocals. Measured in dB. [default: 0]--inst-gain INTEGER: The gain to apply to the pitch-shifted instrumentals. Measured in dB. [default: 0]--backup-gain INTEGER: The gain to apply to the pitch-shifted backup vocals. Measured in dB. [default: 0]--output-sr INTEGER: The sample rate of the song cover. [default: 44100]--output-format [mp3|wav|flac|ogg|m4a|aac]: The audio format of the song cover. [default: mp3]--output-name TEXT: The name of the song cover.--help: Show this message and exit.
./urvc updateWhen developing new features or debugging, it is recommended to run the app in development mode. This enables hot reloading, which means that the app will automatically reload when changes are made to the code.
./urvc devThe Ultimate RVC project is also available as a distributable package on PyPI.
The package can be installed with pip in a Python 3.12-based environment. To do so requires first installing PyTorch with Cuda support:
pip install torch==2.4.1+cu124 torchaudio==2.4.1+cu124 --index-url https://download.pytorch.org/whl/cu124Additionally, on Windows the diffq package must be installed manually as follows:
pip install https://huggingface.co/JackismyShephard/ultimate-rvc/resolve/main/diffq-0.2.4-cp312-cp312-win_amd64.whlThe Ultimate RVC project package can then be installed as follows:
pip install ultimate-rvcThe ultimate-rvc package exposes two commands:
urvc-webwhich starts a local instance of the Ultimate RVC web applicationurvcwhich exposes a traditional CLI application allowing the user to generate song covers directly from their terminal.
For more information on either command supply the option --help.
The behaviour of the Ultimate RVC package can be customized via a number of environment variables. Currently these environment variables control only logging behaviour. They are as follows:
URVC_CONSOLE_LOG_LEVEL: The log level for console logging. If not set, defaults toERROR.URVC_FILE_LOG_LEVEL: The log level for file logging. If not set, defaults toINFO.URVC_LOGS_DIR: The directory in which log files will be stored. If not set, logs will be stored in alogsdirectory in the current working directory.URVC_NO_LOGGING: If set to1, logging will be disabled.
The use of the converted voice for the following purposes is prohibited.
-
Criticizing or attacking individuals.
-
Advocating for or opposing specific political positions, religions, or ideologies.
-
Publicly displaying strongly stimulating expressions without proper zoning.
-
Selling of voice models and generated voice clips.
-
Impersonation of the original owner of the voice with malicious intentions to harm/hurt others.
-
Fraudulent purposes that lead to identity theft or fraudulent phone calls.
I am not liable for any direct, indirect, consequential, incidental, or special damages arising out of or in any way connected with the use/misuse or inability to use this software.