Service Worker
Service Worder 是用来代替 manifest,用来生成缓存的效果的。以前吭哧吭哧的学 manifest 的时候,就发现 MD 好难用。而且 MDN 特意告诉你,manifest 有毒,请不要乱用,保不定后面不支持。今儿,我看了下兼容性,呵呵~
人生苦短,及时享乐,前端真坑,不敢乱学。
前方高能,如果觉得生活没有趣味可以继续看下去,会让你的人生更没有趣味。如果觉得凑合能过,请 ctrl/command + w。
继续~
Service Worker 讲道理是由两部分构成,一部分是 cache,还有一部分则是 Worker。所以,SW(Service Worker) 本身的执行,就完全不会阻碍当前 js 进程的执行,确保性能第一。那 SW 到底是怎么工作的呢?
- 后台进程: SW 就是一个 worker 独立于当前网页进程。
- 网络代理: SW 可以用来代理请求,缓存文件
- 灵活触发: 需要的时候吊起,不需要的时候睡眠(这个是个坑)
- 异步控制: SW 内部使用 promise 来进行控制。
我们先来看看 SW 比较坑的地方,它的 lifecycle
首先,SW 并不是你网页加载就与生俱来的。如果,你需要使用 SW,你首先需要注册一个 SW,让浏览器为你的网页分配一块内存空间来。并且,你能否注册成功,还需要看你缓存的资源量决定(有可能失败,真的有可能)。如果,你需要缓存的静态资源全部保存成功,那么恭喜您,SW 安装成功。如果,其中有一个资源下载失败并且无法缓存,那么这次吊起就是失败的。不过,SW 是由重试机制的,这点也不算特别坑。
当安装成功之后,此时 SW 就进入了激活阶段(activation)。然后,你可以选择性的检查以前的文件是否过期等。
检查完之后,SW 就进入待机状态。此时,SW 有两种状态,一种是 active,一种是 terminated。就是激活/睡眠。激活是为了工作,睡眠则为了节省内存。这是一开始设计的初衷。如果,SW 已经 OK,那么,你网页的资源都会被 SW 控制,当然,SW 第一次加载除外。 简单的流程图,可以参考一下 google的:

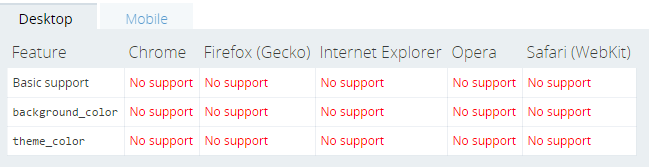
上面简单介绍了 SW 的基本生命周期(实际上,都是废话),讲点实在的,它的兼容性咋样?

基本上手机端是能用的。
现在,开发一个网站没用 HTTPS,估计都没好意思放出自己的域名(太 low)。HTTPS 不仅仅可以保证你网页的安全性,还可以让一些比较敏感的 API 完美的使用。值得一提的是,SW 是基于 HTTPS 的,所以,如果你的网站不是 HTTPS,那么基本上你也别想了 SW。这估计造成了一个困难,即,我调试 SW 的时候咋办?
解决办法也是有的,使用 charles 或者 fildder 完成域名映射即可。
下面,我们仔细介绍下,SW 的基本使用。
SW 实际上是挂载到 navigator 下的对象。在使用之前,我们需要先检查一下是否可用:
if ('serviceWorker' in navigator) {
// ....
}
如果可用,我们就要使用 SW 进行路由的注册缓存文件了。不过,这里有点争议。啥时候开始执行 SW 的注册呢?上面说过,SW 就是一个网络代理,用来捕获你网页的所有 fetch 请求。那么,是不是可以这么写?
window.addEventListener('DOMContentLoaded', function() {
// 执行注册
navigator.serviceWorker.register('/sw.js').then(function(registration) {
}).catch(function(err) {
});
});
这样理解逻辑上是没有任何问题的,关键在于,虽然 SW 是 worker ,但浏览器的资源也是有限的,浏览器分配给你网页的内存就这么多,你再开个 SW(这个很大的。。。),没有 jank 才怪嘞,而且如果你网页在一开始加载的时候有动画展示的话,那么这种方式基本上就 GG 了。
另外,如果算上用户第一次加载,那么这个卡顿或者延时就很大了。
当然,W3C 在制定相关规范时,肯定考虑到这点,实际上 SW 在你网页加载完成同样也能捕获已经发出的请求。所以,为了减少性能损耗,我们一般直接在 onload 事件里面注册 SW 即可。GOOGLE Jeff Posnick 针对这个加载,专门讨论了一下,有兴趣的可以参考一下。(特别提醒,如果想要测试注册 SW 可以使用隐身模式调试!!!)
那当我注册成功时,怎样查看我注册的 SW 呢?
这很简单,直接打开 chrome://inspect/#service-workers 就可以查看,在当前浏览器中,正在注册的 SW。另外,还有一个 chrome://serviceworker-internals,用来查看当前浏览器中,所有注册好的 SW。
使用 SW 进行注册时,还有一个很重要的特性,即,SW 的作用域不同,监听的 fetch 请求也是不一样的。
例如,我们将注册路由换成: /example/sw.js
window.addEventListener('DOMContentLoaded', function() {
// 执行注册
navigator.serviceWorker.register('/example/sw.js').then(function(registration) {
}).catch(function(err) {
});
});
那么,SW 后面只会监听 /example 路由下的所有 fetch 请求,而不会去监听其他,比如 /jimmy,/sam 等路径下的。
从这里开始,我们就正式进入 SW 编程。记住,下面的部分是在另外一个 js 中的脚本,使用的是 worker 的编程方法。如果,有同学还不理解 worker 的话,可以先去学习一下,这样在后面的学习中才不会踩很深的坑。 监听安装 SW 的代码也很简单:
self.addEventListener('install', function(event) {
// Perform install steps
});
当安装成功后,我们能使用 SW 做什么呢? 那就开始缓存文件了呗。简单的例子为:
self.addEventListener('install', function(event) {
event.waitUntil(
caches.open('mysite-static-v1').then(function(cache) {
return cache.addAll([
'/css/whatever-v3.css',
'/css/imgs/sprites-v6.png',
'/css/fonts/whatever-v8.woff',
'/js/all-min-v4.js'
]);
})
);
});
此时,SW 会检测你制定文件的缓存问题,如果,已经都缓存了,那么 OK,SW 安装成功。如果查到文件没有缓存,则会发送请求去获取,并且会带上 cache-bust 的 query string,来表示缓存的版本问题。当然,这只针对于第一次加载的情况。当所有的资源都已经下载成功,那么恭喜你可以进行下一步了。大家可以参考一下 google demo。
这里,我简单说一下上面的过程,首先 event.waitUntil 你可以理解为 new Promise,它接受的实际参数只能是一个 promise,因为,caches 和 cache.addAll 返回的都是 Promise,这里就是一个串行的异步加载,当所有加载都成功时,那么 SW 就可以下一步。另外,event.waitUntil 还有另外一个重要好处,它可以用来延长一个事件作用的时间,这里特别针对于我们 SW 来说,比如我们使用 caches.open 是用来打开指定的缓存,但开启的时候,并不是一下就能调用成功,也有可能有一定延迟,由于系统会随时睡眠 SW,所以,为了防止执行中断,就需要使用 event.waitUntil 进行捕获。另外,event.waitUntil 会监听所有的异步 promise,如果其中一个 promise 是 reject 状态,那么该次 event 是失败的。这就导致,我们的 SW 开启失败。
不过,如果其中一个文件下载失败的话,那么这次你的 SW 启动就告吹了,即,如果其中有一个 Promise 是使用 reject 的话,那就代表着--您这次启动是 GG 的。那,有没有其他办法在保证一定稳定性的前提下,去加载比较大的文件呢? 有的,那你别返回 cache.addAll 就ok了。什么个意思呢? 就这样:
self.addEventListener('install', function(event) {
event.waitUntil(
caches.open('mygame-core-v1').then(function(cache) {
// 不稳定文件或大文件加载
cache.addAll(
//...
);
// 稳定文件或小文件加载
return cache.addAll(
// core assets & levels 1-10
);
})
);
});
这样,第一个 cache.addAll 是不会被捕获的,当然,由于异步的存在,这毋庸置疑会有一些问题。比如,当大文件还在加载的时候,SW 断开,那么这次请求就是无效的。不过,你这样写本来就算是一个 trick,这种情况在制定方案的时候,肯定也要考虑进去的。整个步骤,我们可以用下图表示:
FROM GOOGLE

该阶段就是事关整个网页能否正常打开的一个阶段--非常关键。在这一阶段,我们将学会,如何让 web 使用缓存,如何做向下兼容。 先看一个简单的格式:
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.match(event.request)
.then(function(response) {
// Cache hit - return response
if (response) {
return response;
}
return fetch(event.request);
}
)
);
});
首先看一下,第一个方法--event.respondWith,用来包含响应主页面请求的代码。当接受到 fetch 请求时,会直接返回 event.respondWith Promise 结果。我们在 worker 中,捕获页面所有的 fetch 请求。可以看到 event.request ,这个就是 fetch 的 request 流。我们通过 caches.match 捕获,然后返回 Promise 对象,用来进行响应的处理。大家看这段代码时,可能会有很多的疑惑,是的,一开始我看的时候也是,因为,根本没注释,有些 name 实际上是内核自带的。上面的就有:
- caches: 这是用来控制缓存专门分离出来的一个对象。可以参考: caches
- fetch: 是现代浏览器用来代替 XMLHttpRequest 专门开发出的 ajax 请求。可以参考: fetch 通信
简单来说,caches.match 根据 event.request,在缓存空间中查找指定路径的缓存文件,如果匹配到,那么 response 是有内容的。如果没有的话,则再通过 fetch 进行捕获。整个流图如下:
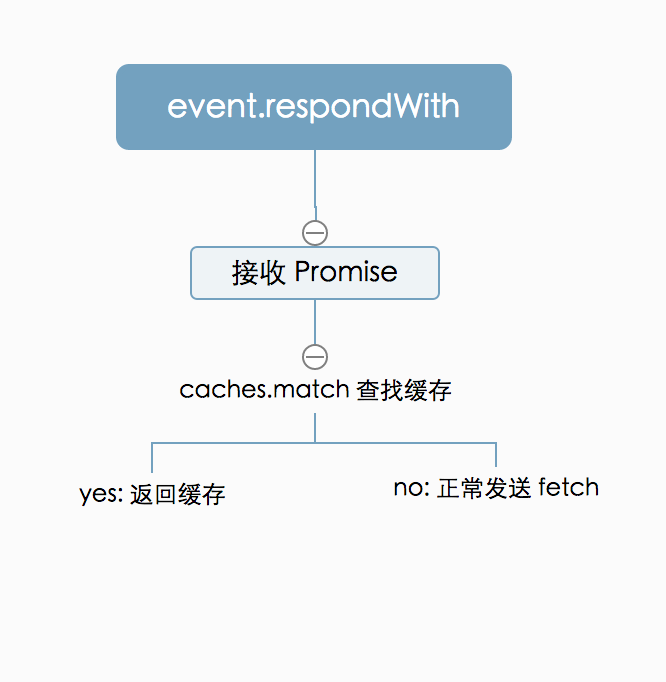
OK,那现在有个问题,如果没有找到缓存,那么应该怎么做呢?
- 啥都不做,等下一次 SW 自己根据路由去缓存。
- 没找到,我手动 fetch 然后添加进缓存。
那怎么手动添加呢?
很简单,自己发送 fetch,然后使用 caches 进行缓存即可。不过,这里又涉及到另外一个概念,Request 和 Response 流。这是在 fetch 通信方式 很重要的两个概念。fetch 不仅分装了 ajax,而且在通信方式上也做了进一步的优化,同 node 一样,使用流来进行重用。众所周知,一个流一般只能使用一次,可以理解为喝矿泉水,只能喝一次,不过,如果我知道了该水的配方,那么我就可以量产该水,这就是流的复制。下面代码也基本使用到这两个概念,基本代码为:
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.match(event.request)
.then(function(response) {
if (response) {
return response;
}
// 因为 event.request 流已经在 caches.match 中使用过一次,
// 那么该流是不能再次使用的。我们只能得到它的副本,拿去使用。
var fetchRequest = event.request.clone();
// fetch 的通过信方式,得到 Request 对象,然后发送请求
return fetch(fetchRequest).then(
function(response) {
// 检查是否成功
if(!response || response.status !== 200 || response.type !== 'basic') {
return response;
}
// 如果成功,该 response 一是要拿给浏览器渲染,而是要进行缓存。
// 不过需要记住,由于 caches.put 使用的是文件的响应流,一旦使用,
// 那么返回的 response 就无法访问造成失败,所以,这里需要复制一份。
var responseToCache = response.clone();
caches.open(CACHE_NAME)
.then(function(cache) {
cache.put(event.request, responseToCache);
});
return response;
}
);
})
);
});
那么整个流图变为:

而里面最关键的地方就是 stream 这是现在浏览器操作数据的一个新的标准。为了避免将数据一次性写入内存,我们这里引入了 stream,相当于一点一点的吐。这个和 nodeJS 里面的 stream 是一样的效果。你用上述哪个流图,这估计得取决于你自己的业务。
在 SW 中的更新涉及到两块,一个是基本静态资源的更新,还有一个是 SW.js 文件的更新。这里,我们先说一下比较坑的 SW.js 的更新。
SW.js 的更新不仅仅只是简单的更新,为了用户可靠性体验,里面还是有很多门道的。
- 首先更新 SW.js 文件,这是最主要的。只有更新 SW.js 文件之后,之后的流程才能触发。SW.js 的更新也很简单,直接改动 SW.js 文件即可。浏览器会自动检查差异性(就算只有 1B 的差异也行),然后进行获取。
- 新的 SW.js 文件开始下载,并且
install事件被触发 - 此时,旧的 SW 还在工作,新的 SW 进入
waiting状态。注意,此时并不存在替换 - 现在,两个 SW 同时存在,不过还是以前的 SW 在掌管当前网页。只有当 old SW 不工作,即,被
terminated后,新的 SW 才会发生作用。具体行为就是,该网页被关闭一段时间,或者手动的清除service worker。然后,新的 SW 就度过可waiting的状态。 - 一旦新的 SW 接管,则会触发
activate事件。
整个流程图为:
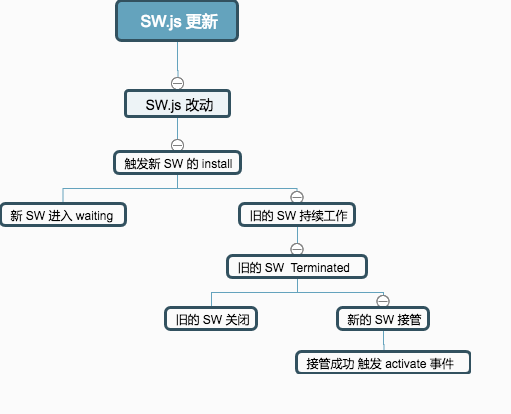
如果上述步骤成功后,原来的 SW.js 就会被清除。但是,以前版本 SW.js 缓存文件没有被删除。针对于这一情况,我们可以在新的 SW.js 里面监听 activate 事件,进行相关资源的删除操作。当然,这里主要使用到的 API 和 caches 有很大的关系(因为,现在所有缓存的资源都在 caches 的控制下了)。比如,我以前的 SW 缓存的版本是 v1,现在是 v2。那么我需要将 v1 给删除掉,则代码为:
self.addEventListener('activate', function(event) {
var cacheWhitelist = ['v1'];
event.waitUntil(
// 遍历 caches 里所有缓存的 keys 值
caches.keys().then(function(cacheNames) {
return Promise.all(
cacheNames.map(function(cacheName) {
if (cacheWhitelist.includes(cacheName)) {
// 删除 v1 版本缓存的文件
return caches.delete(cacheName);
}
})
);
})
);
});
另外,我那么你不经仅可以用来作为版本的更新,还可以作为缓存目录的替换。比如,我想直接将 site-v1的缓存文件,替换为 ajax-v1 和 page-v1。则,我们一是需要先在 install 事件里面将 ajajx-v1 和 page-v1 缓存套件给注册了,然后,在 activate 里面将 site-v1 缓存给删除,实际代码和上面其实是一样的:
self.addEventListener('activate', function(event) {
var cacheWhitelist = ['site-v1'];
event.waitUntil(
// 遍历 caches 里所有缓存的 keys 值
caches.keys().then(function(cacheNames) {
return Promise.all(
cacheNames.map(function(cacheName) {
if (cacheWhitelist.includes(cacheName)) {
// 删除 v1 版本缓存的文件
return caches.delete(cacheName);
}
})
);
})
);
});
不过,sw.js 文件的更新是一个非常坑爹的过程。因为,它的替换是当 older SW 不工作的时候,new SW 才能发生作用。并且,浏览器何时关闭对应的 SW 又是一个未知数。不过,Service Worker 本身就是这么设计的,╮(╯▽╰)╭ (;′⌒`)
那有没有什么办法能够让 new SW 立即生效呢?有的,可以在 install 阶段使用 self.skipWaiting(); API。因为上面说到 new SW 加载后会触发 install 然后进入 waiting 状态。那么,我们可以直接在 install 阶段跳过等待,直接让 new SW 进行接管。
self.addEventListener('install', event => {
self.skipWaiting();
event.waitUntil(
// caching etc
);
});
不过,这样有个弊端是,此时用户正在当前网页中,此时,older SW 会触发 activate 事件,删除相关的资源,这样会造成资源丢失,只能通过网络获取。并且后面的网络请求都会交给 new SW 进行捕获和处理。所以,用不用还得根据具体业务来看。
上面的 SW 更新都是在一开始加载的时候进行的,那么,如果用户需要长时间停留在你的网页上,有没有什么手段,在间隔时间检查更新呢?
有的,可以使用 registration.update() 来完成。
navigator.serviceWorker.register('/sw.js').then(reg => {
// sometime later…
reg.update();
});
另外,如果你一旦用到了 sw.js 并且确定路由之后,请千万不要在更改路径了,因为,浏览器判断 sw.js 是否更新,是根据 sw.js 的路径来的。如果你修改的 sw.js 路径,而以前的 sw.js 还在作用,那么你新的 sw 永远无法工作。除非你手动启用 update 进行更新。
对于文件更新来说,整个机制就显得很简单了。可以说,你想要一个文件更新,只需要在 SW 的 fetch 阶段使用 caches 进行缓存即可。实际操作也很简单,一开始我们的 install 阶段的代码为:
self.addEventListener('install', function(event) {
event.waitUntil(
caches.open('mysite-static-v1').then(function(cache) {
return cache.addAll([
'/css/whatever-v3.css',
'/css/imgs/sprites-v6.png',
'/css/fonts/whatever-v8.woff',
'/js/all-min-v4.js'
]);
})
);
});
我们只需要在这里简单的写下一下 prefetch 代码即可。
self.addEventListener('install', function(event) {
var now = Date.now();
// 事先设置好需要进行更新的文件路径
var urlsToPrefetch = [
'static/pre_fetched.txt',
'static/pre_fetched.html',
'https://www.chromium.org/_/rsrc/1302286216006/config/customLogo.gif'
];
event.waitUntil(
caches.open(CURRENT_CACHES.prefetch).then(function(cache) {
var cachePromises = urlsToPrefetch.map(function(urlToPrefetch) {
// 使用 url 对象进行路由拼接
var url = new URL(urlToPrefetch, location.href);
url.search += (url.search ? '&' : '?') + 'cache-bust=' + now;
// 创建 request 对象进行流量的获取
var request = new Request(url, {mode: 'no-cors'});
// 手动发送请求,用来进行文件的更新
return fetch(request).then(function(response) {
if (response.status >= 400) {
// 解决请求失败时的情况
throw new Error('request for ' + urlToPrefetch +
' failed with status ' + response.statusText);
}
// 将成功后的 response 流,存放在 caches 套件中,完成指定文件的更新。
return cache.put(urlToPrefetch, response);
}).catch(function(error) {
console.error('Not caching ' + urlToPrefetch + ' due to ' + error);
});
});
return Promise.all(cachePromises).then(function() {
console.log('Pre-fetching complete.');
});
}).catch(function(error) {
console.error('Pre-fetching failed:', error);
})
);
});
当成功获取到缓存之后, SW 并不会直接进行替换,他会等到用户下一次刷新页面过后,使用新的缓存文件。
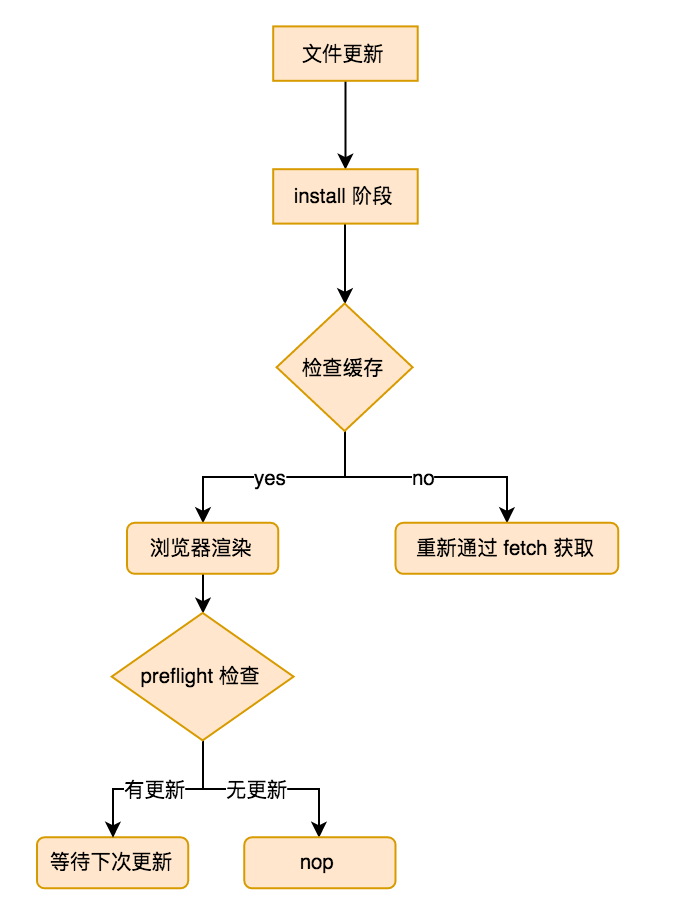
不过,这里请注意,我并没有说,我们更新缓存只能在 install 里更新,事实上,更新缓存可以在任何地方执行。它主要的目的是用来更新 caches 里面缓存套件。我们提取一下代码:
// 找到缓存套件并打开
caches.open(CURRENT_CACHES.prefetch).then(function(cache) {
// 根据事先定义的路由开始发送请求
var cachePromises = urlsToPrefetch.map(function(urlToPrefetch) {
// 执行 fetch
return fetch(request).then(function(response) {
// 缓存请求到的资源
return cache.put(urlToPrefetch, response);
}).catch(function(error) {
console.error('Not caching ' + urlToPrefetch + ' due to ' + error);
});
});
// 使用 promise.all 进行全部捕获
return Promise.all(cachePromises).then(function() {
console.log('Pre-fetching complete.');
});
}).catch(function(error) {
console.error('Pre-fetching failed:', error);
})
现在,我们已经拿到了核心代码,那有没有什么简便的办法,让我们少写一些配置项,直接对每一个文件进行文件更新教研。
有的!!!
还记得上面的 fetch 事件吗?我们简单回顾一下它的代码:
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.match(event.request)
.then(function(response) {
// Cache hit - return response
if (response) {
return response;
}
return fetch(event.request);
}
)
);
});
实际上,我们可以将上面的核心代码做一些变化直接用上:
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.open('mysite-dynamic').then(function(cache) {
return cache.match(event.request).then(function(response) {
var fetchPromise = fetch(event.request).then(function(networkResponse) {
cache.put(event.request, networkResponse.clone());
return networkResponse;
})
return response || fetchPromise;
})
})
);
});
这里比较难的地方在于,我们并没有去捕获 fetch(fetchRequest)... 相关内容。也就是说,这一块是完全独立于我们的主体业务的。他的 fetch 只是用更新文件而已。我们可以使用一个流图进行表示:
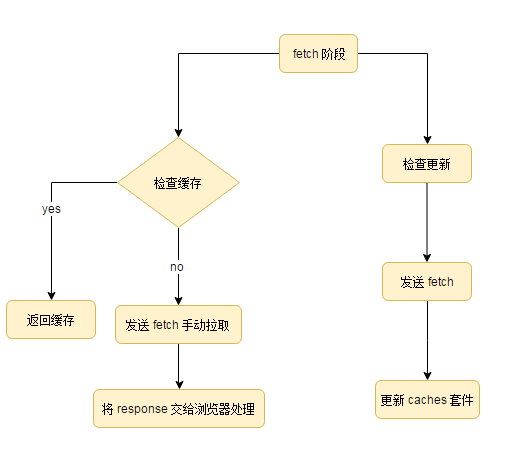
现在,为了更好的用户体验,我们可以做的更尊重用户一些。可以设置一个 button,告诉用户是否选择缓存指定文件。有同学可能会想到使用 postmessage API,来告诉 SW 执行相关的缓存信息。不过事实上,还有更简单的办法来完成,即,直接使用 caches 对象。caches 和 web worker 类似。都是直接挂载到 window 对象上的。所以,我们可以直接使用 caches 这个全局变量来进行搜索。那么该环节就不需要直接通过 SW,这个流程图可以画为:

代码可以参考:
document.querySelector('.cache-article').addEventListener('click', function(event) {
event.preventDefault();
var id = this.dataset.articleId;
// 创建 caches 套件
caches.open('mysite-article-' + id).then(function(cache) {
fetch('/get-article-urls?id=' + id).then(function(response) {
// 返回 json 对象
return response.json();
}).then(function(data) {
// 缓存指定路由
cache.addAll(data);
});
});
});
不过上述的弊端也是有的,你把缓存的更新交给前台来做,实际上是增加的 js 主线程的负担,所以,按照一般的思路,我们是需要通过 message 来触发 service worker 的文件更新。
这里,我们简单介绍一下, client 和 service worker 相互通信。首先, service worker 向 client 发送消息很容易。
self.addEventListener('message', function(event){
console.log("SW Received Message: " + event.data);
event.ports[0].postMessage("SW Says 'Hello back!'");
});
其中 event.ports 是根据 messageChannel API 构造出来的。该 API 的用法大家 MDN 一下吧。我们主要来看一下,如何在 clients 端,向 service worker 传递信息。这里就要借由:ServiceWorkerContainer 这个对象在 navigator 上获取。
navigator.serviceWorker === ServiceWorkerContainer
在该 API 上挂载了一些方法和属性,用来获取 service worker 上的相关状态。来看一下:

其中和通信相关的就两个,一个是 controller,一个是 onmessage 事件。
- controller: 通过其上挂载的 postMessage API 向 Service worker 发送信息。
- onmessage: 接受 Service worker 发送的消息
即:
function send_message_to_sw(msg){
navigator.serviceWorker.controller.postMessage("Client 1 says '"+msg+"'");
}
而 Service Worker 只要负责接收即可:
self.addEventListener('message',event =>{
console.log("receive message" + event.data);
});
该方法常常用于,用来更新根目录的 html 文档,因为 SW 在更新的时候,并不会对根目录下的 HTML 文档进行更新。那么综上所述,一般而言,除了根文件而言,其他文件只要根据 hash 值来跟新即可。我们看一下整个的写法:
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.match(event.request).then(function(resp) {
fetchList.push(event.request.url);
return resp || fetch(event.request).then(function(response) {
return caches.open(CURRENT_CACHES.prefetch).then(function(cache) {
console.log('update files like' + event.request.url);
cache.put(event.request, response.clone());
return response;
});
});
})
);
});
self.addEventListener('message',event =>{
console.log("receive message" + event.data);
// 更新根目录下的 html 文件。
var url = event.data;
console.log("update root file " + url);
event.waitUntil(
caches.open(CURRENT_CACHES.prefetch).then(cache=>{
return fetch(url)
.then(res=>{
cache.put(url,res);
})
})
)
});
然后,在 index.js 中,添加 postMessage API。记住,每次网页打开时,并不会每次都触发 register,因为你已经接受 SW,所以,我们需要做额外的判断,来检测是否发送相关的消息。那么我们在代码中就可以添加如下内容:
var SW = navigator.serviceWorker;
SW.register('sw.js').then(function(registration) {
//...
}).catch(function(err) {
});
if(SW.controller){
console.log('send message ::');
SW.controller.postMessage(location.href)
}
如果想更深入了解 Message 的相关处理,可以参考:sendMessage
上面大致了解了一下关于 SW 的基本流程,不过说到底,SW 只是一个容器,它的内涵只是一个驻留后台进程。我们想关心的是,在这进程里面,我们可以做些什么?
最主要的应该有两个东西,缓存和推送。这里我们主要讲解一下缓存。不过在SW 中,我们一般只能缓存 POST
上面在文件更新里面也讲了几个更新的方式。简单来说:

简单的情形上面已经说了,我这里专门将一下比较复杂的内容。
这种情形一般是用来装逼的,一方面检查请求,一方面有检查缓存,然后看两个谁快,就用谁,我这里直接上代码吧:
function promiseAny(promises) {
return new Promise((resolve, reject) => {
// 通过 promise 的 resolve 特性来决定谁快
promises = promises.map(p => Promise.resolve(p));
// 这里调用外层的 resolve
promises.forEach(p => p.then(resolve));
// 如果其中有一方出现 error,则直接挂掉
promises.reduce((a, b) => a.catch(() => b))
.catch(() => reject(Error("All failed")));
});
};
self.addEventListener('fetch', function(event) {
event.respondWith(
promiseAny([
caches.match(event.request),
fetch(event.request)
])
);
});
这里就和我们在后台配置的 Last-Modifier || Etag 一样,询问更新的文件内容,然后执行更新:
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.open('mysite-dynamic').then(function(cache) {
return fetch(event.request).then(function(response) {
cache.put(event.request, response.clone());
return response;
});
})
);
});
这应该是目前为止最佳的体验,返回的时候不会影响正在发送的请求,而接受到的新的请求后,最新的文件会替换旧的文件。(这个就是前面写的代码):
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.open('mysite-dynamic').then(function(cache) {
return cache.match(event.request).then(function(response) {
var fetchPromise = fetch(event.request).then(function(networkResponse) {
cache.put(event.request, networkResponse.clone());
return networkResponse;
})
return response || fetchPromise;
})
})
);
});
上面说的哪几种都有某一方面的缺陷,那如果才能实现一种比较靠谱的缓存方案呢?我们借鉴一下上面提到的 message 通信方式,方案为:

我们对资源做的主要工作就是如果处理好 fetch 事件中的相关资源。这里,我们简单的通过文件类型这个点来进行划分,优先情况是缓存 js/css 文件。那在 fetch 事件中,我们就需要写为:
var CURRENT_CACHES = {
prefetch: 'prefetch-cache-v' + 1;
};
var FILE_LISTS = ['js','css','png'];
var goSaving = function(url){
for(var file of FILE_LISTS){
if(url.endsWith(file)) return true;
}
return false;
}
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.match(event.request).then(function(resp) {
return resp || fetch(event.request).then(function(response) {
// 检查是否需要缓存
var url = event.request.url;
if(!goSaving(url))return response;
console.log('save file:' + url);
// 需要缓存,则将资源放到 caches Object 中
return caches.open(CURRENT_CACHES.prefetch).then(function(cache) {
console.log('update files like' + event.request.url);
cache.put(event.request, response.clone());
return response;
});
});
})
);
});
这样通过在 FILE_LISTS 添加想要缓存的文件类型即可。之后,我们只要在 message 中更新原来的 document 即可。
self.addEventListener('message',event =>{
console.log("receive message" + event.data);
// 更新根目录下的 html 文件。
var url = event.data;
console.log("update root file " + url);
event.waitUntil(
caches.open(CURRENT_CACHES.prefetch).then(cache=>{
return fetch(url)
.then(res=>{
cache.put(url,res);
})
})
)
});
接下来,我们来详细了解一下关于 Cache Object 相关的内容。加深印象:
Cache 虽然是在 SW 中定义的,但是我们也可以直接在 window 域下面直接使用它。它通过 Request/Response 流(就是 fetch)来进行内容的缓存。每个域名可以有多个 Cache Object,具体我们可以在控制台中查看:
并且 Cache Object 是懒更新,实际上,就可以把它比喻为一个文件夹。如果你不自己亲自更新,系统是不会帮你做任何事情的。对于删除也是一样的道理,如果你不显示删除,它会一直存在的。不过,浏览器对于每个域名的 Cache Object 数量是有限制的,并且,会周期性的删掉一些缓存信息。最好的办法,是我们自己管理资源,官方给出的建议是: 使用版本号进行资源管理。上面我也展示过,删除特定版本的缓存资源:
self.addEventListener('activate', function(event) {
var cacheWhitelist = ['v2'];
event.waitUntil(
caches.keys().then(function(keyList) {
return Promise.all(keyList.map(function(key) {
if (cacheWhitelist.indexOf(key) === -1) {
return caches.delete(key);
}
}));
})
);
});
这里,我们就可以将 Cache Object 理解为一个持久性数据库,那么针对于数据库来说,简单的操作就是 CRUD。而 Cache Object 也提供了这几个接口,并且接口结果都是通过 Promise 对象返回的,成功返回对应结果,失败则返回 undefined:
- Cache.match(request, options): 成功时,返回对应的响应流--response。当然,查找的时候使用的是正则匹配,表示是否含有某个具体字段。
- options:
- ignoreSearch[boolean]:是否忽略 querystring 的查找。即,我们查找的区域不包括 qs。比如:
http://foo.com/?value=bar,我们不会再搜索?value=bar这几个字符。 - ignoreMethod[boolean]:当设置为 true 时,会防止 Cache 验证 http method,默认情况下,只有 GET 和 HEAD 能够通过。默认值为 false。
- ignoreVary[boolean]:当设置为 true 时,表示不对 vary 响应头做验证。即, Cache 只需要通过 URL 做匹配即可,不需要对响应头 vary 做验证。默认值为 false。
- cacheName[String]: 自己设置的缓存名字。一般用不到,match 会自动忽略。
- ignoreSearch[boolean]:是否忽略 querystring 的查找。即,我们查找的区域不包括 qs。比如:
- options:
cache.match(request,{options}).then(function(response) {
//do something with the response
});
- Cache.matchAll(request, options): 成功时,返回一个数组,包含所有匹配到的响应流。options 和上面的一样,这里就不多说了。
cache.matchAll(request,{options}).then(function(response) {
response.forEach(function(element, index, array) {
cache.delete(element);
});
});
- Cache.add(url): 这实际上就是一个语法糖。fetch + put。即,它会自动的向路由发起请求,然后缓存获取到的内容。
cache.add(url).then(function() {
// 请求的资源被成功缓存
});
# 等同于
fetch(url).then(function (response) {
if (!response.ok) {
throw new TypeError('bad response status');
}
return cache.put(url, response);
})
.then(res=>{
// 成功缓存
})
- Cache.addAll(requests):这个就是上面 cache.add 的 Promise.all 实现方式。接受一个 Urls 数组,然后发送请求,缓存上面所有的资源。
this.addEventListener('install', function(event) {
event.waitUntil(
caches.open('v1').then(function(cache) {
return cache.addAll([
'/public/',
'/public/index.html',
'/public/style.css',
'/public/app.js'
]);
})
);
});
- Cache.put(request, response): 将请求的资源以 req/res 键值对的形式进行缓存。如果,之前已经存在对应的 req(即,key 值),那么以前的值将会被新值覆盖。
cache.put(request, response).then(function() {
// 成功缓存
});
- Cache.delete(request, options): 用来删除指定的 cache。如果你不删除,该资源会永远存在(除非电脑自动清理)。
- Cache.keys(request, options): 返回当前缓存资源的所有 key 值。
cache.keys().then(function(keys) {
keys.forEach(function(request, index, array) {
cache.delete(request);
});
});
可以查看到上面的参数都共同的用到了 request 这就是 fetch 套件里面的请求流,具体,可以参考一下前面的代码。上面所有方法都是返回一个 Promise 对象,用来进行异步操作。
上面简单介绍了一下 Cache Object,但实际上,Cache 的管理方式是两级管理。即,最外层是 Cache Storage,下一层是 Cache Object。
浏览器会给每个域名预留一个 Cache Storage(只有一个)。然后,剩下的缓存资源,全部都存在下面。我们可以理解为,这就是一个顶级缓存目录管理。而我们获取 Cache Object 的唯一途径,就是通过 caches.open() 进行获取。这里,我们就可以将 open 方法理解为 没有已经存在的 Cache Object 则新建,否则直接打开。它的相关操作方法也有很多:
- CacheStorage.match(request,{options}):在所有的 Cache Object 中进行缓存匹配。返回值为 Promise
caches.match(event.request).then(function(resp) {
return resp || fetch(event.request).then(function(r) {
caches.open('v1').then(function(cache) {
cache.put(event.request, r);
});
return r.clone();
});
});
- CacheStorage.has(cacheName): 用来检查是否存在指定的 Cache Object。返回 Boolean 代表是否存在。
caches.has('v1').then(function(hasCache) {
// 检测是否存在 Cache Object Name 为 v1 的缓存内容
if (!hasCache) {
// 没存在
} else {
//...
}
}).catch(function() {
// 处理异常
});
- CacheStorage.open(cacheName): 打开指定的 Cache Object。并返回 Cache Object。
caches.open('v1').then(function(cache) {
cache.add('/index.html');
});
- CacheStorage.delete(cacheName): 用来删除指定的 Cache Object,返回值为 Boolean:
caches.delete(cacheName).then(function(isDeleted) {
// 检测是否删除成功
});
# 通过,可以通过 Promise.all 的形式来删除多个 cache object
Promise.all(keyList.map(function(key) {
if (cacheList.indexOf(key) === -1) {
return caches.delete(keyList[i]);
}
});
- CacheStorage.keys(): 以数组的形式,返回当前 Cache Storage 保存的所有 Cache Object Name。
event.waitUntil(
caches.keys().then(function(keyList) {
return Promise.all(keyList.map(function(key) {
if (['v1','v2'].indexOf(key) === -1) {
return caches.delete(keyList[i]);
}
});
})
);
上面就是关于 Cache Storage 的所有内容。
这里放一张自己写的总结图吧:

{kind=link}