Clean up and optimize crc32c #22385
Clean up and optimize crc32c #22385
Conversation
test/misc.jl
Outdated
| unsafe_crc32c_sw(a, n, crc) = | ||
| ccall(:jl_crc32c_sw, UInt32, (UInt32, Ptr{UInt8}, Csize_t), crc, a, n) | ||
| crc32c_sw(a::Union{Array{UInt8},Base.FastContiguousSubArray{UInt8,N,<:Array{UInt8}} where N}, | ||
| crc::UInt32=0x00000000) = unsafe_crc32c_sw(a, length(a), crc) |
5f6b8ef to
e6bc9b1
Compare
|
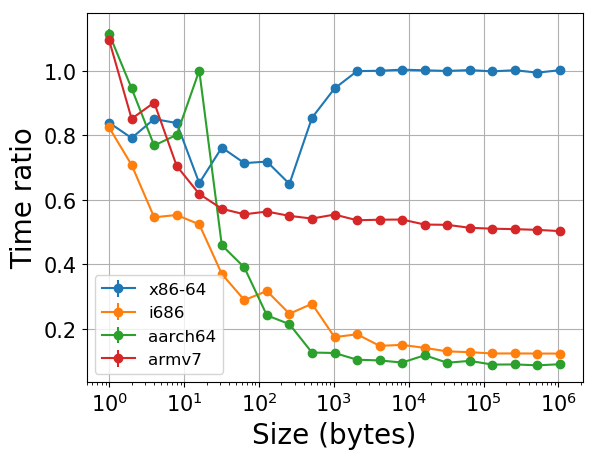
Added another optimization for 32bit arch and here's the benchmark result. A ratio smaller than 1 represent speed up.
The only slow down comes from single byte crc32c on arm and aarch64. Unclear what's causing that but it probably doesn't matter..... The speed up on x64 only comes from reducing fixed overhead (which is measureable all the way to ~1kB size) and the speed up for other archs comes from algorithm optimizations/use of hardware instructions. |
|
@jlbuild !filter=arm,aarch64,ppc |
| @@ -0,0 +1,590 @@ | |||
| /* crc32c.c -- compute CRC-32C using software table or available hardware instructions | |||
There was a problem hiding this comment.
adjust the path to this file in the exceptions list in contrib/add_license_to_files.jl
d5bc370 to
7af464f
Compare
| @@ -783,9 +783,9 @@ function crc32c end | |||
| unsafe_crc32c(a, n, crc) = ccall(:jl_crc32c, UInt32, (UInt32, Ptr{UInt8}, Csize_t), crc, a, n) | |||
|
|
|||
| crc32c(a::Union{Array{UInt8},FastContiguousSubArray{UInt8,N,<:Array{UInt8}} where N}, crc::UInt32=0x00000000) = | |||
| unsafe_crc32c(a, length(a), crc) | |||
| unsafe_crc32c(a, length(a) % Csize_t, crc) | |||
There was a problem hiding this comment.
What is this for? Maybe you should just add an unsafe_crc32c(a, n::Int, crc) method for this if it is important?
There was a problem hiding this comment.
Remove overflow check.
src/crc32c.c
Outdated
| } | ||
|
|
||
| #if (defined(_CPU_X86_64_) || defined(_CPU_X86_)) && !defined(_COMPILER_MICROSOFT_) | ||
| #ifdef _CPU_X86_64_ |
There was a problem hiding this comment.
Indent nested preprocessor statements, e.g. # ifdef (keeping # at the start of the line)?
| @@ -58,7 +58,7 @@ const skipfiles = [ | |||
| "../src/support/tzfile.h", | |||
| "../src/support/utf8.c", | |||
| "../test/perf/micro/randmtzig.c", | |||
| "../src/support/crc32c.c", | |||
| "../src/crc32c.c", | |||
There was a problem hiding this comment.
Did you forget to do a git mv for this file? The diff is confusing because it as if you removed the file and added it elsewhere.
There was a problem hiding this comment.
No. The commit changes the file enough that git may not show them as the same file. Also there isn't anything different between git mv and remove + add in general.
src/crc32c.c
Outdated
|
|
||
| #if (defined(_CPU_X86_64_) || defined(_CPU_X86_)) && !defined(_COMPILER_MICROSOFT_) | ||
| #ifdef _CPU_X86_64_ | ||
| #define CRC32_PTR "crc32q" |
There was a problem hiding this comment.
CRC32_ASM or CRC32_INSTRUCTION?
There was a problem hiding this comment.
The PTR is the important part since it is the instruction that operates on uintptr_t.
| } | ||
| // For ifdef detection below | ||
| # define crc32c_dispatch() crc32c_dispatch(getauxval(AT_HWCAP)) | ||
| # define crc32c_dispatch_ifunc "crc32c_dispatch" |
There was a problem hiding this comment.
Since crc32c_dispatch_ifunc is always the same (when it is defined), do we really need a #define for it?
There was a problem hiding this comment.
I'd rather not make that assumption.
There was a problem hiding this comment.
I don't see much of an improvement from "assume the implementation defines a function called crc32_dispatch" to "assume that the implementation #defines a symbol named crc32c_dispatch_ifunc". What do you gain by allowing different names for the actual function, since only one can be defined at a time?
There was a problem hiding this comment.
The error can be easier to catch.
|
The benchmarks here may also be interesting: https://github.com/htot/crc32c (cc @htot). They found that Intel's hand-coded asm implementation is a factor of 2 faster than Adler's code. (I'm not sure that we actually care that much about CRC32c speed, but Intel's ASM code appears to 3-clause BSD if we want it.) |
|
Adler's code is very fast and so is Intel's assembly version. Differences occur at different buffer lengths due to the way of recombining the crc on the buffer parts. The intel method also elegantly makes use of the pclmuldq instruction to simplify the code. See also here https://www.intel.com/content/dam/www/public/us/en/documents/white-papers/crc-iscsi-polynomial-crc32-instruction-paper.pdf If you have a fixed buffer length that is unequal to 4048 you can use my repo to test which is fastest. My work was only to port back the assembly code to C and make that run on 32 bit as well. |
* Skip runtime dispatch if required features are available at compile time * Use lazy dispatch * Remove jl_crc32c_init and change how sw version is tested * Remove uneeded ifdef * Use ifunc when available
|
This PR is actually centered around making the hardware accelerated version working on AArch64 including the cleanup to get it working with minimum ifdef's. Given this is pretty big as it is, I'll probably leave the pclmuldq change to another PR. (ARMv8 also have pmul so I wonder if that can be applied too.) |
|
I have tried, but haven't been to figure out the math behind pclmuldq. I just replaced all asm by C, then carefully verified the resulting compiled code with -O2/3 is similar and same speed as the original. Of course for some instructions that is not possible, hence the inline asm. |
This is split out of #21849. A summary of the changes (should be all in commit messages)
Move
crc32cso that it can use logic injulia_internal.handlibjulia. (the latter will be useful for ARM)Improve CPU dispatch, remove
jl_crc32c_init.On new enough glibc+gcc/clang no dispatch will be needed thanks to ifunc
Implement hardware accelerated crc32c on AArch64 and 32bit X86
32bit ARMv8 should work too but hardware feature detection is much harder (due to old glibc version support) so that'll wait until Implement function multi versioning in sysimg #21849 is merged.
I'll probably post some benchmarks later.