ImaginaryNLP is python library for long-short term dialogue planning and efficient abstract sequence modeling of dialogues. It is based upon Curved Contrastive Learning from the paper Imagination Is All You Need! (presented at ACL 2023 in Toronto, Canada) and utilizes Sentence Transformers.
Download and install ImaginaryNLP by running:
python -m pip install imaginaryNLPfrom imaginaryNLP.ImaginaryEmbeddingsForSequenceModeling import ImaginaryEmbeddingsForSequenceModeling
# Load the model
seq = ImaginaryEmbeddingsForSequenceModeling('Justus-Jonas/Imaginary-Embeddings-SpeakerTokens', speaker_token=True)
# add candidates and context
seq.load_candidates_from_strings(["I'm fine, thanks. How are you?", "Where did you go?", "ACL is an interesting conference"])
seq.create_context(["Hi!",'Hey, how are you?'], precompute_top_p=0.8)
# pre-compute and keep 80% of utterances
seq.sequence_modeling_with_precompute("I am doing good. Today I went for a walk. ")from imaginaryNLP.ImaginaryEmbeddingsForLTP import ImaginaryEmbeddingsForLTP
ltp = ImaginaryEmbeddingsForLTP('Justus-Jonas/Imaginary-Embeddings-SpeakerTokens', speaker_token=True)
# add a contex
ltp.create_context([' Hello', 'Hi , great to meet you ! '])
# add goals
ltp.add_goal(" great to hear that ! ")
ltp.add_goal(" Want to go for a walk ? ")
ltp.add_goal(" Bye !")
# greedy curving
ltp.greedy_curving()
# imaginary embedding chains
ltp.imaginary_embedding_chains()
# imaginary embedding chains with curving
ltp.imaginary_embedding_chains_with_curving()from imaginaryNLP.ImaginaryEmbeddingsForSTP import ImaginaryEmbeddingsForSTP
# Load the model
stp = ImaginaryEmbeddingsForSTP('Justus-Jonas/Imaginary-Embeddings-SpeakerTokens-STP')
candidates = ['Want to eat something out ?',
'Want to go for a walk ?']
goal = ' I am hungry.'
stp.short_term_planning(candidates, goal)from imaginaryNLP.trainer import ImaginaryEmbeddingTrainer
from datasets import load_dataset
trainer = ImaginaryEmbeddingTrainer(base_model_name_or_path="roberta-base",
batch_size=64,
observation_window=5,
speaker_token=True,
num_epochs=10,
warmup_steps=10000)
dataset = load_dataset("daily_dialog")
trainer.generate_datasets(
dataset["train"]["dialog"],
dataset["validation"]["dialog"],
dataset["test"]["dialog"],
)
trainer.train("output/path/to/save/model")as an example we use the DailyDialog dataset. For your own data make sure to pass a List[List[str]] to the functions.
from datasets import load_dataset
from imaginaryNLP.ImaginaryEmbeddingsForSequenceModeling import EvalImaginaryEmbeddingsForSequenceModeling
seq = EvalImaginaryEmbeddingsForSequenceModeling('Justus-Jonas/Imaginary-Embeddings-SpeakerTokens', speaker_token=True)
dataset = load_dataset("daily_dialog")
test = dataset['test']['dialog']
df = seq.evaluate_seq_dataset(test)from datasets import load_dataset
from imaginaryNLP.ImaginaryEmbeddingsForLTP import EvalImaginaryEmbeddingsForLTP
ltp = EvalImaginaryEmbeddingsForLTP('Justus-Jonas/Imaginary-Embeddings-Classic', speaker_token=False)
dataset = load_dataset("daily_dialog")
test = dataset['test']['dialog']
ltp.create_ltp_dataset(test, "output/path/to/dir")
df = ltp.evaluate_ltp_dataset("output/path/to/dir")from datasets import load_dataset
from imaginaryNLP.ImaginaryEmbeddingsForSTP import EvalImaginaryEmbeddingsForSTP
stp = EvalImaginaryEmbeddingsForSTP('Justus-Jonas/Imaginary-Embeddings-SpeakerTokens-STP',
llm_model_name_or_path='your favorite large language model',
speaker_token=True
)
dataset = load_dataset("daily_dialog")
test = dataset['test']['dialog']
stp.create_stp_dataset(test, "output/path/to/dir")
stp.add_transformer_candidates("output/path/to/dir")
df = stp.evaluate_stp_dataset("output/path/to/dir")| Huggingface Dataset | other datasets included | Models |
|---|---|---|
| daily_dialog | - | Justus-Jonas/Imaginary-Embeddings-SpeakerTokens Justus-Jonas/Imaginary-Embeddings-Classic Justus-Jonas/Imaginary-Embeddings-SpeakerTokens-STP * |
| diwank/imaginary-nlp-dataset | daily_dialog allenai/prosocial-dialog air_dialogue |
- |
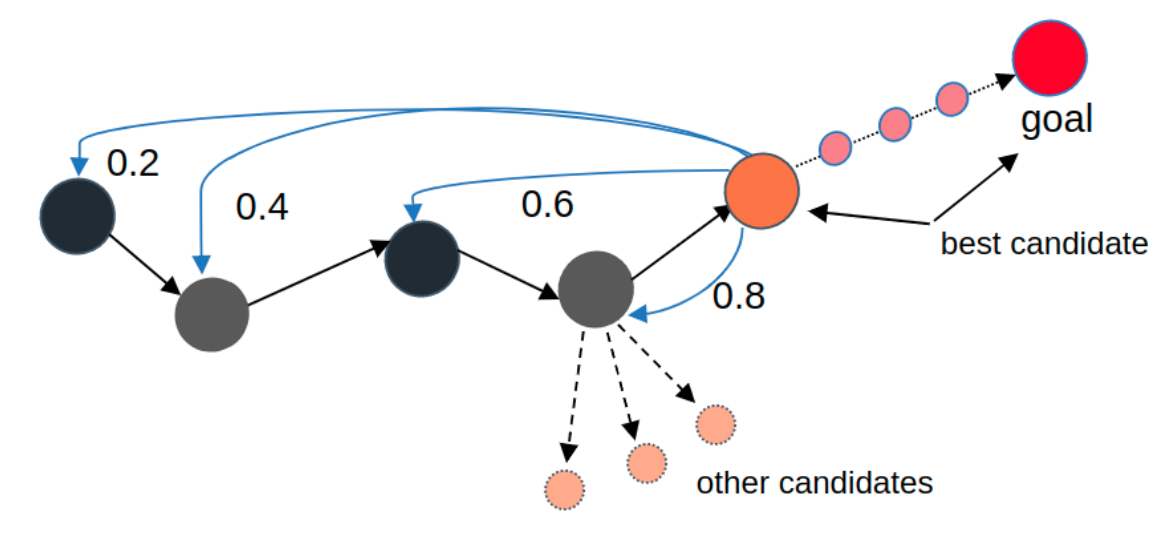
- explicitly for short-term planning while others are used for sequence modeling and long-term planning.
If you are interested in the other models used in the paper, please feel free to checkout our DailyDialog Models here.
Note while this repository is under Apache 2.0 License, the models are under cc by-nc-sa 4.0 due to the license
of the DailyDialog dataset. Unfortunately, we are not allowed to share the datasets / models of
the Microsoft Dialogue Challenge Corpus (MDC) due to License restrictions.
@inproceedings{erker-etal-2023-imagination,
title = "Imagination is All You Need! Curved Contrastive Learning for Abstract Sequence Modeling Utilized on Long Short-Term Dialogue Planning",
author = "Erker, Justus-Jonas and
Schaffer, Stefan and
Spanakis, Gerasimos",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2023",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-acl.319",
pages = "5152--5173",
abstract = "Inspired by the curvature of space-time, we introduce Curved Contrastive Learning (CCL), a novel representation learning technique for learning the relative turn distance between utterance pairs in multi-turn dialogues. The resulting bi-encoder models can guide transformers as a response ranking model towards a goal in a zero-shot fashion by projecting the goal utterance and the corresponding reply candidates into a latent space. Here the cosine similarity indicates the distance/reachability of a candidate utterance toward the corresponding goal. Furthermore, we explore how these forward-entailing language representations can be utilized for assessing the likelihood of sequences by the entailment strength i.e. through the cosine similarity of its individual members (encoded separately) as an emergent property in the curved space. These non-local properties allow us to imagine the likelihood of future patterns in dialogues, specifically by ordering/identifying future goal utterances that are multiple turns away, given a dialogue context. As part of our analysis, we investigate characteristics that make conversations (un)plannable and find strong evidence of planning capability over multiple turns (in 61.56{\%} over 3 turns) in conversations from the DailyDialog dataset. Finally, we show how we achieve higher efficiency in sequence modeling tasks compared to previous work thanks to our relativistic approach, where only the last utterance needs to be encoded and computed during inference.",
}