- 2021.11.10更新:更新了文档和说明,修改了一部分bug
- 2022.3.10更新:重构了大部分代码,更新了文档和说明
这是一个基于Pytorch平台、Transformer框架实现的视频描述生成 (Video Captioning) 深度学习模型。
视频描述生成任务指的是:输入一个视频,输出一句描述整个视频内容的文字(前提是视频较短且可以用一句话来描述)。本repo主要目的是帮助视力障碍者欣赏网络视频、感知周围环境,促进“无障碍视频”的发展。
😋 这个repo是第七届“互联网+”北京赛区三等奖项目「以声绘影——基于人工智能的无障碍视频自动生成技术」的一部分。
😋 这个repo是北京市级大学生创新训练项目「基于深度学习的视频画面描述及无障碍视频研究」的一部分。
😋 这个repo的一部分已登记软件著作权2022SR0269902。
当视频太长或较复杂时效果可能就很差了,针对长视频,目前有密集视频描述生成任务,即Dense Video Captioning,本项目暂时不涉及,但欢迎魔改这个repo。
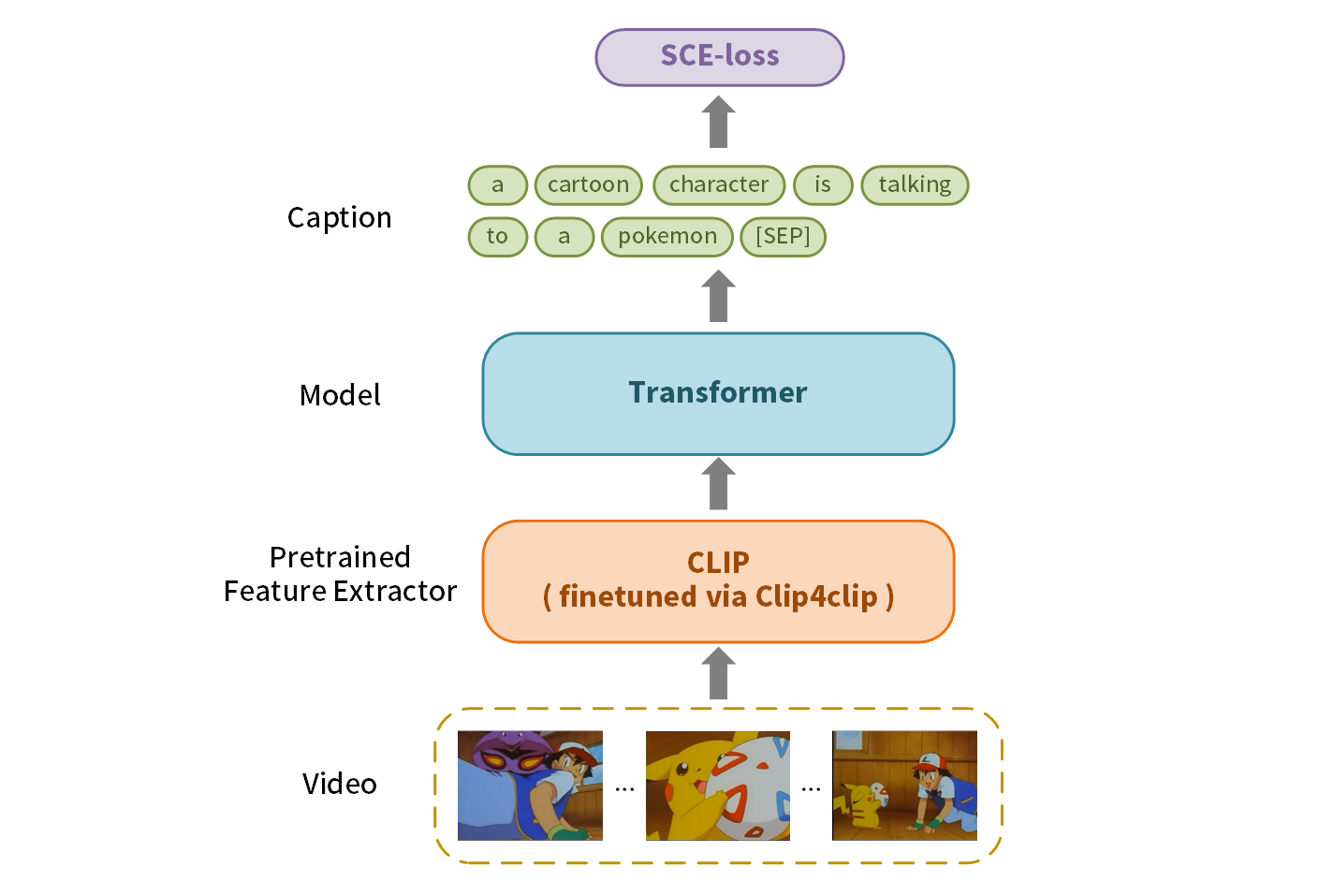
如下图:CLIP是一个视觉-语言的大规模预训练模型,Clip4clip是将CLIP运用在视频检索任务的一种方法,SCE-loss是一个针对噪声较大数据集的损失函数。我们通过CLIP提取视频的特征,然后作为输入送入Transformer中,输出Caption,训练阶段用SCE-loss优化。
Java JRE (用来调用MS COCO eval server进行Bleu等评估)
Python3.6+
torch 1.8.2+
transformers 4.17.0
tensorboardX
tqdm
mmcv
numpy
pathlib
PIL
模型在训练集集上训练,根据验证集进行earlystop,下表结果为测试集结果。
| 训练数据集 | Bleu@4 | METEOR | ROUGE_L | CIDEr | 下载 | 配置文件 |
|---|---|---|---|---|---|---|
| MSVD | 58.0 | 39.9 | 77.0 | 113.8 | 百度网盘zmr4 Drive | config |
| MSR-VTT | 48.1 | 31.1 | 65.1 | 60.2 | 百度网盘xy7e Drive | config |
git clone https://github.com/Kamino666/Video-Captioning-Transformer.git --recurse-submodules
python predict.py -c <config> -m <model> -v <video> \
--feat_type CLIP4CLIP-ViT-B-32 \
--ext_type uni_12 \
--greedy \
[--gpu/--cpu]- config:配置文件
- model:模型
- video:要测试的视频路径
- gpu/cpu:使用gpu或者cpu推理
- 更多参数见
predict.py内的注释。

 |
效果有的好有的差吧hhhhh |
|---|
本repo使用MSR-VTT数据集和MSVD数据集
-
原始视频
-
特征文件
百度网盘 aupi包含了两个数据集的标注和特征
-
特征提取方法
特征提取使用我的另一个repo:Kamino666/video_features。
PATH=$PATH:<java_root> \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
python eval.py -c <config> -m <model> [--gpu/--cpu]- java_root是java的路径,精确到bin目录,假如已经配置好环境变量可以忽略此项。
- 评估模型时配置文件中data下eval属性需要把验证集改成测试集。
PATH=$PATH:<java_root> \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
python -m torch.distributed.run --nproc_per_node 4 train.py \
-c <config> --multi_gpu -ws 4- 训练时可使用Bleu等指标作为Earlystop依据,此时需要Java。
- 此处以4卡训练为例子,注意
-ws参数的值是使用的显卡数量。 - 若单卡训练则:
python train.py -c <config> --gpu,若懒得改也可以直接把4换成1。
配置文件是json格式的一个文件,在训练和预测时都需要用到。简单的说明如下:(部分配置可能不起作用或令人迷惑,是实验时添加的其他部分,可用性暂无法保证)
├── data
│ ├── train 训练数据
│ ├── validation 验证数据(用来计算loss)
│ └── eval 验证数据(用来计算Bleu等)
├── train 和训练方法有关的参数
│ ├── earlystop earlystop的patience
│ ├── epoch 最大epoch数
│ ├── save_dir 模型保存路径
│ ├── log_dir 日志保存路径(tensorboard读取)
│ └── tag 模型保存名称
├── test
└── model 和模型结构有关的参数
├── video_encoder Transformer编码器的参数
├── caption_decoder Transformer解码器的参数
└── modal_shape 模态的维度
 |
 |
|---|---|
 |
 |
 |
 |
-
Q:下载来自hugging face的模型失败
-
A:以
bert-base-uncased模型为例,在hugging face的模型网站上的下载页面可以看到一系列文件,如果是模型下载失败BertModel.from_pretrained(),则下载.bin文件,并把参数改成.bin的路径;如果是tokenizer下载失败AutoTokenizer.from_pretrained(),则下载config.json、tokenizer.json、tokenizer_config.json、vocab.txt四个文件,并把参数改成这四个文件所处目录路径。如果不想这么麻烦,可以科学上网。 -
Q:这个模型多大?
-
A:主要参数是总共4层的Transformer。
- 微信小程序正在开发中
- 支持中文和VATEX数据集
- 祈祷论文不要被拒:pray:
@misc{video,
author = {Zihao, Liu},
title = {{video captioning transformer}},
howpublished = {\url{https://github.com/Kamino666/Video-Captioning-Transformer}},
year = {2022}
}