Postgres-XL is an all-purpose fully ACID open source multi node scalable SQL database solution, based on PostgreSQL.
This chart allows for creating a multi container, multi process, distributed database using Postgres-XL. It is based upon the wonderful docker postgres-xl-docker image.
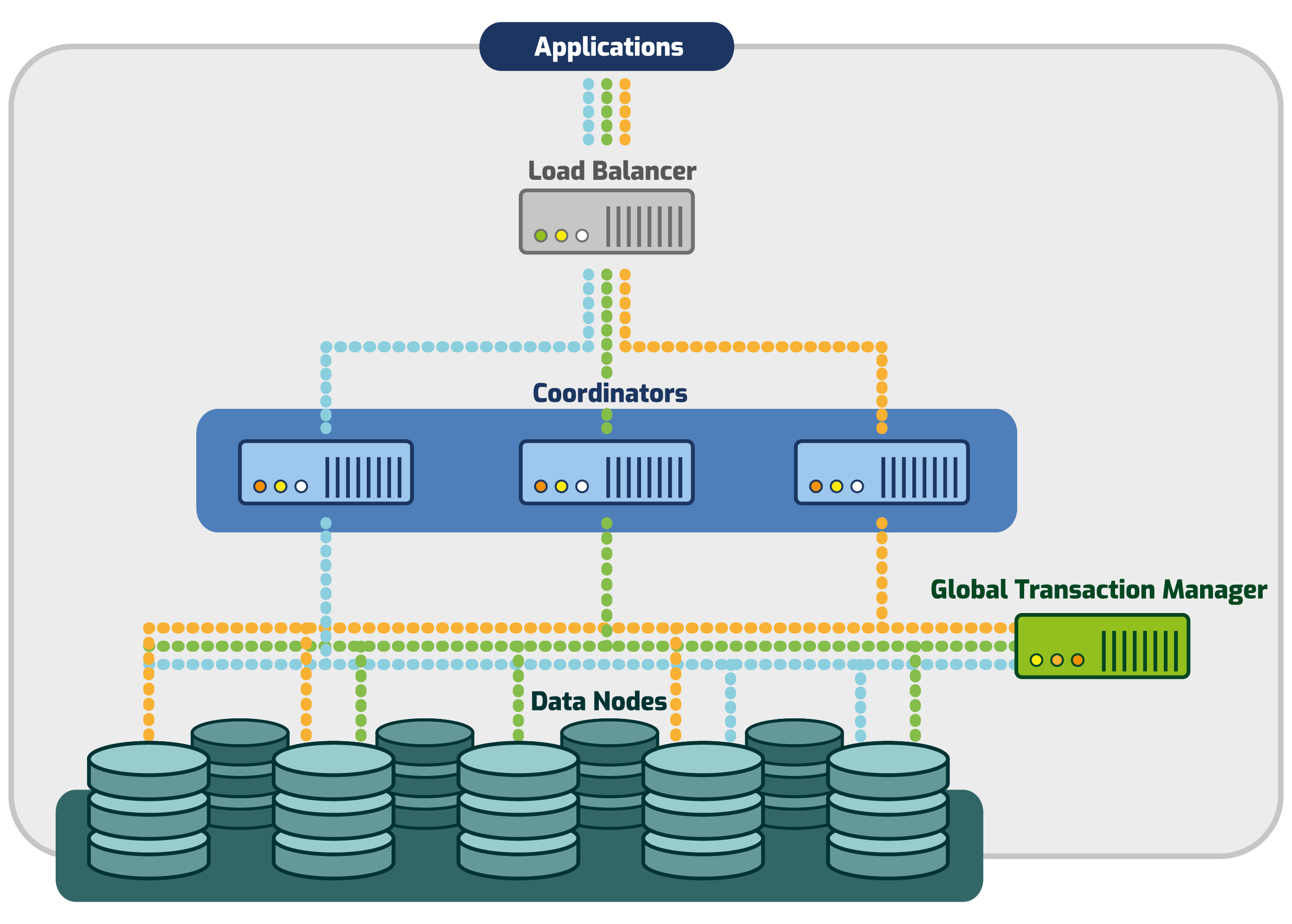
For a graph description of the connections structure see here.
{kind=link}
Any contributions are welcome.
- If using this chart as a database, please make sure you read the sections about persistence, backup and restore.
- We have been trying to get an official blessing for the underlining docker image, postgres-xl-docker, but until now there was no response (whatsoever) from the official channel. If you are planning to use postgres-xl in production, you may have to relay on paid support from www.2ndquadrant.com.
This chart is in final testing stage.
See: Postgres-XL documentation
- Global Transaction Manager (GTM) - Single pod StatefulSet - provides transaction management for the entire cluster. The data stored in the GTM is part of the database persistence and should be backed up.
- Coordinator - Multi-pod StatefulSet - Database external connections entry point (i.e. where I connect my client to). These pods provide transparent concurrency and integrity of transactions globally. Applications can choose any Coordinator to connect to, they work together. Any Coordinator provides the same view of the database, with the same data, as if it was one PostgreSQL database. The data stored in the coordinator is part of the DB data and should be backed up.
- Datanode - Multi-pod StatefulSet - All table data is stored here. A table may be replicated or distributed between datanodes. Since query work is done on the datanodes, the scale and capacity of the db will be determined by the number of datanodes. The data stored in the datanode is part of the DB data and should be backed up.
- GTM Proxy (optional) - A helper transaction manager. Gtm proxy groups connections and interactions between gtm and other Postgres-XL components to reduce both the number of interactions and the size of messages. Performance tests have shown greater performance with high concurrency workloads as a result.
To connect to the database, please connect to the db main service (which is the coordinator service), example:
kubectl port-forward svc/[release-name]-postgres-xl-svc[STS] = datanodes or coordinators or proxies or gtm
Example: datanodes.count = 32
| name | description | default value |
|---|---|---|
| image | the image to use | pavouk0/postgres-xl:XL_10_R1_1-6-g68c378f-4-g7a65119 |
| envs | Additional envs to add to all pods | [null] |
| extraLabels | yaml for adding container labels to be added to all the pods | [null] |
| config.log_level | The log level to use, accepts : ERROR, WARNING, INFO, DEBUG, DEBUG1-DEBUG5 | WARNING |
| config.managers_port | the port to use for transaction management (GTM or proxies) | 6666 |
| config.postgres_port | the internal postgres port | 5432 |
| config.append.[STS] | A string to append to the end of the postgres config file for a specific StatefulSet. | [null] |
| service.port | the external service port | 5432 |
| service.enabled | if true enables the external load balancer service | true |
| service.type | The external service type | LoadBalancer |
| security.passwords_secret_name | The kubernetes secret value set to be used for passwords. | [null] |
| security.pg_password | The superuser postgres password | [null] |
| security.postgres_auth_type | The authentication type used | md5 |
| name | description | default value |
|---|---|---|
| [STS].count | The total number of replicas, dose not apply to gtm | 1 |
| [STS].resources | the main pod resources | Limits, GTM - 2Gi, 2 cpu; All others - 1Gi, 1 cpu |
| [STS].pvc | The persistence volume claim for data storage. Use this value to set the internal database storage. See Persistence for recommended values. | [null] |
| [STS].addContainers | yaml inject to add more containers | |
| [STS].volumes | yaml inject to add more volumes | |
| [STS].volumeMounts | yaml inject to add more volume mounts | |
| [STS].addVolumeClaims | yaml inject to add STS dependent volume claims. See here for more info about these | |
| [STS].thread_count | applies only to proxies, and is the proxy worker thread count | 3 |
| name | description | default value |
|---|---|---|
| homedir | the image home directory | /var/lib/postgresql |
| overrideEnvs | a set of envs which are added after the chart core envs, and allows to override the chart. | [null] |
| service.injectSpecYaml | injects yaml into the external service | [null] |
| name | description |
|---|---|
| [STS].injectMainContainerYaml | inject yaml into the main container. |
| [STS].injectSpecYaml | inject yaml into the template spec. |
| [STS].injectSTSYaml | inject yaml into the main STS spec. |
The implementation in this chart relies on StatefulSets to maintain data persistence between recoveries and restarts.
To do so, one must define the pvc argument in the values. If you do not define the pvc argument, the
data will be lost on any case of restart/recover/fail.
To define a persistent database you must define all three pvcs for each of the stateful sets,
(below are recommended test values, where x is the size of each datanode)
datanodes.pvc:
resources:
requests:
storage: [x]Gi
gtm.pvc:
resources:
requests:
storage: 100Mi
coordinators.pvc:
resources:
requests:
storage: 100MiOnce these are defined, the DB will recover when any of datanode/coordinator/proxy/gtm are restarted.
See more about persistence in Stateful Sets here and here.
In order to keep to kubernetes principles, this helm chart allows to specify the persistent volume claim class for the workers, coordinators and gtm. This data will persist between restarts. The persistent volumes created will be prefixed by datastore-
Information about StorageClasses can be found here
In order to make a copy of the database one must copy all the data of each and every coordinator and datanode. This means that, when relying on this type of persistence one must:
- Create a backup solution using a specified persistent storage class, and allow the backend to keep copies of the data between restarts.
- You CANNOT decrease the number of executing datanodes and coordinators otherwise data will be lost. Scaling up may require the redistribution of tables, information about such operations can be found here.
More about replication and high availability.
- GCS
- AWS
For the current beta phase, a pod will be considered healthy if it can pass,
- pg_isready.
- Connect to the gtm, datanodes (all), and coordinators (all).
Benchmarks:
- https://www.2ndquadrant.com/en/blog/postgres-xl-scalability-for-loading-data/
- https://www.2ndquadrant.com/en/blog/benchmarking-postgres-xl/
The data in the DB will persist only when all datanodes, coordinators and gtm disks are safely restored. This helm chart does not deal with partial restores.
Copyright ©
Zav Shotan and other contributors.
It is free software, released under the MIT licence, and may be redistributed under the terms specified in LICENSE.