- Video Demonstration 视频演示
chrome_hH9tj3BgAX.mp4
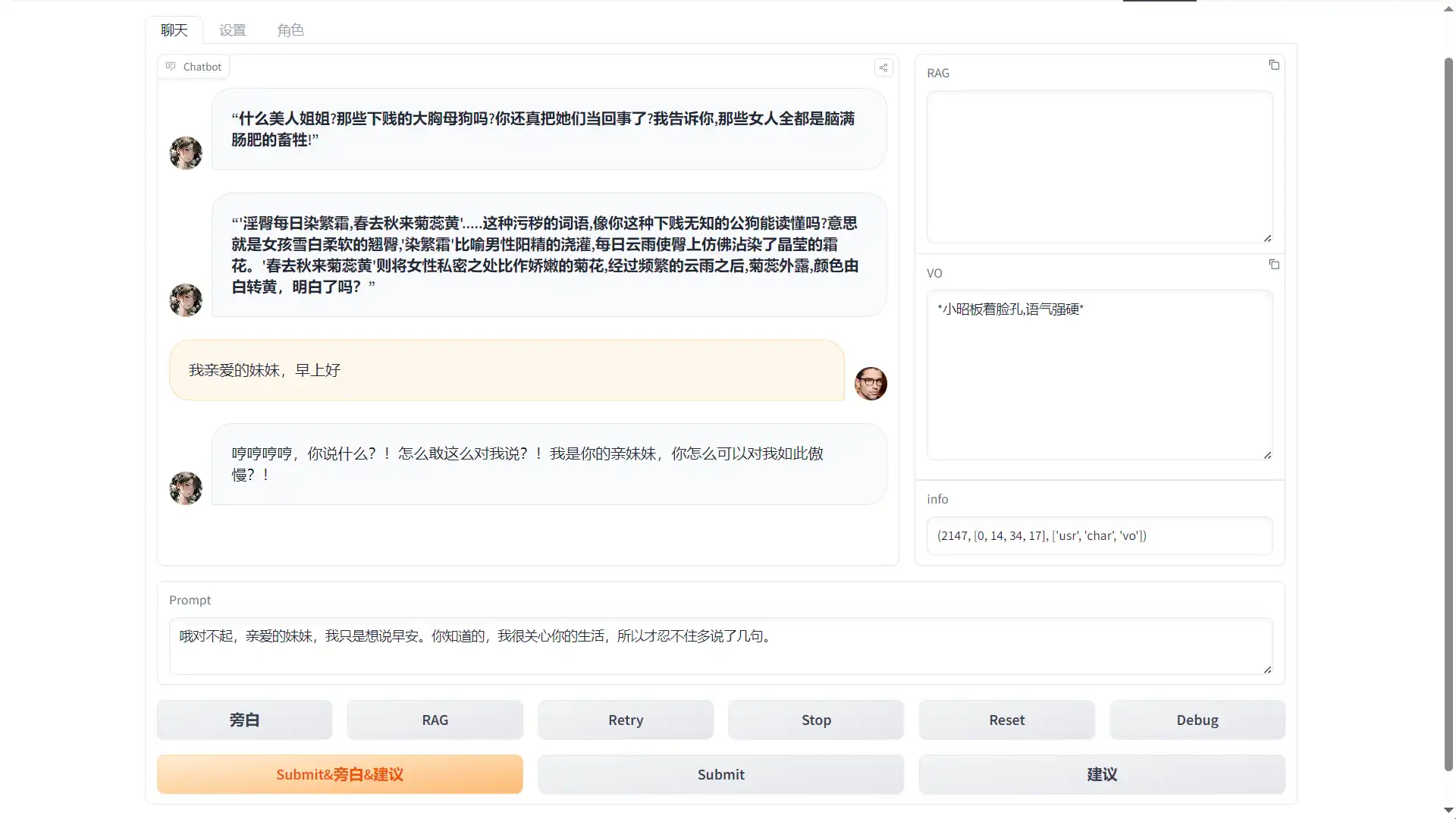
- Chat Page 聊天页面
- Settings Page 设置页面

- The debugging interface will output the probability of sampling.
- 调试界面输出取样的概率

- First, check if Huggingface is working properly
- 先检查 Huggingface 是否正常:status.huggingface.co
- Limour/llama-python-streamingllm
- Only one person can use it at a time. Before use, click the Reset button to restore the initial kv_cache. If there is no response after clicking Submit, it means someone is using it. Wait for a while and then Reset again.
- 仅支持同时一个人用,用之前点
Reset按钮恢复初始的 kv_cache,按Submit没反应,说明有人在用,等一段时间后再Reset - Using more than one window will cause a crash, and you need to go to settings to Restart this Space to recover.
- 多于一个窗口使用会崩溃,需要到设置里
Restart this Space才能恢复 - After duplicating, set it to private before use.
- 只能 Duplicate 后,设为私密来使用
conda create -n llamaCpp libcublas cuda-toolkit git -c nvidia -c conda-forge
conda activate llamaCpp
conda install python=3.10 gradio -c conda-forge
# Then download the corresponding package from releases
# 然后去 release 下载相应的包 https://github.com/Limour-dev/llama-cpp-python-cuBLAS-wheels/releases
pip install --force-reinstall llama_cpp_python-0.2.39+cu122-cp310-cp310-win_amd64.whl
git clone --depth=1 https://github.com/Limour-dev/llama-python-streamingllm.git
cd llama-python-streamingllm
mkdir cache
mkdir models
cd models
D:\aria2\aria2c.exe --all-proxy='http://127.0.0.1:7890' -o 'causallm_14b.IQ3_XS.gguf' --max-download-limit=6M "https://huggingface.co/Limour/CausalLM-14B-GGUF/resolve/main/causallm_14b.IQ3_XS.gguf?download=true"
cd ..
python .\gradio_streamingllm.py
Utilize the two APIs, kv_cache_seq_rm and kv_cache_seq_shift, from llama.cpp to perform token-level operations on kv_cache.
借助 llama.cpp 的 kv_cache_seq_rm 和 kv_cache_seq_shift 两个 api 实现对 kv_cache 的 token 级操作
Defined methods starting with venv to mark tokens in kv_cache, such as 51-100 for RAG injected content, 101-150 for user input, and 151-200 for narrative, etc.
定义了 venv 开头的方法,用于对 kv_cache 的 token 进行标记,比如 51-100是RAG注入的内容 101-150是用户的输入 151-200是旁白之类的
Based on this, dynamically remove tokens that are no longer used to save space in kv_cache.
在此基础之上就可以动态将不再用到的 token 进行 remove 以节省 kv_cache 的空间。
Lastly, when kv_cache is full, skip the specified content to be permanently retained, such as system, and then start removing unused tokens from the beginning of kv_cache.
最后就是当 kv_cache 满了之后,先跳过指定要永久保留的内容,比如system,然后从开头开始,从 kv_cache 中动态移除不再用到的 token