实现原理
详情请参考 这里
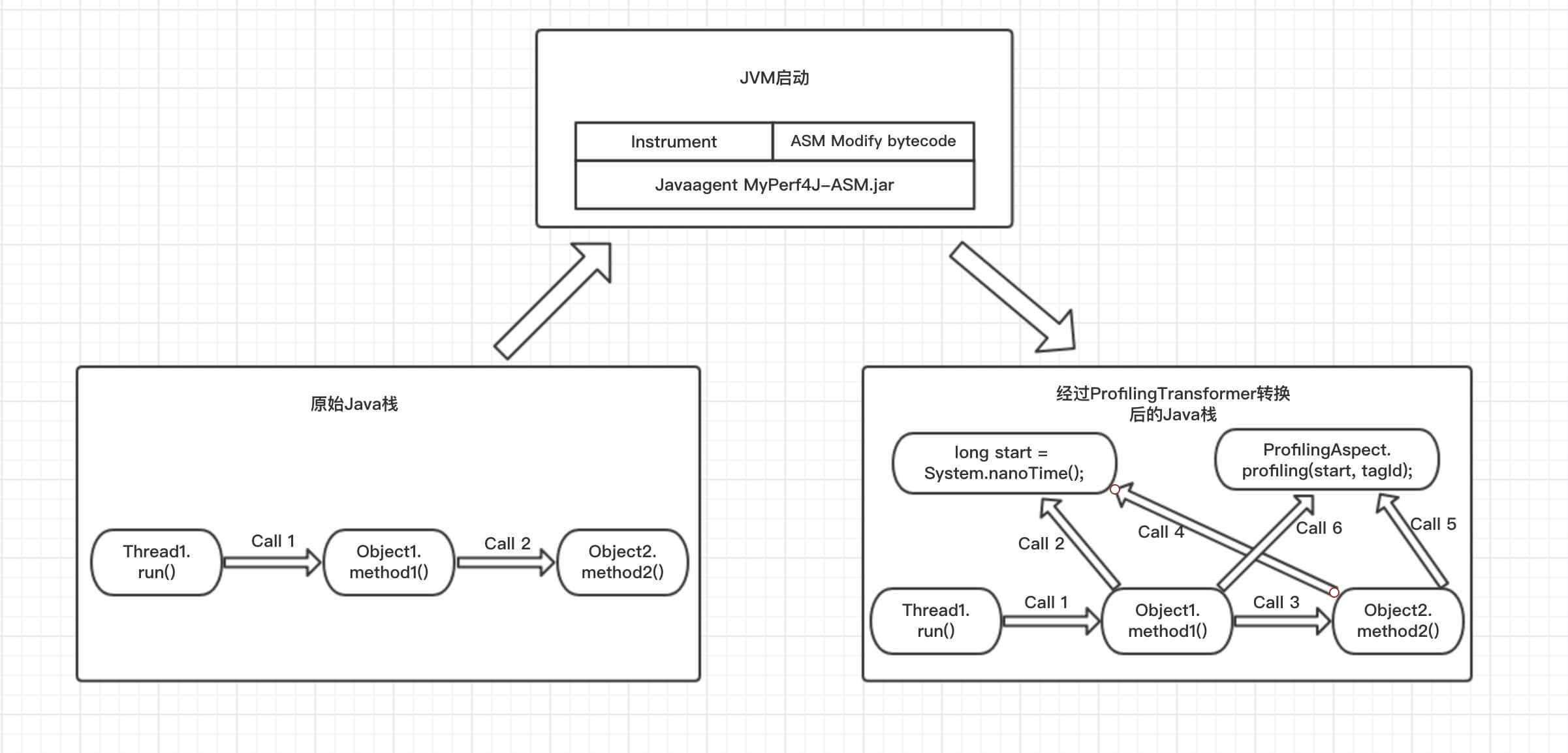 MyPerf4J 目前采用 ASM 字节码修改框架在 JVM 加载类时修改 Java 方法的字节码:
MyPerf4J 目前采用 ASM 字节码修改框架在 JVM 加载类时修改 Java 方法的字节码:
- 在方法的开头加入
long start = System.nanoTime(); - 在方法的结尾加入
ProfilingAspect.profiling(start, methodId);,其中 methodId 为类加载时为每一个方法分配的唯一 ID
想了解 ASM?请下载 ASM4使用指南.pdf
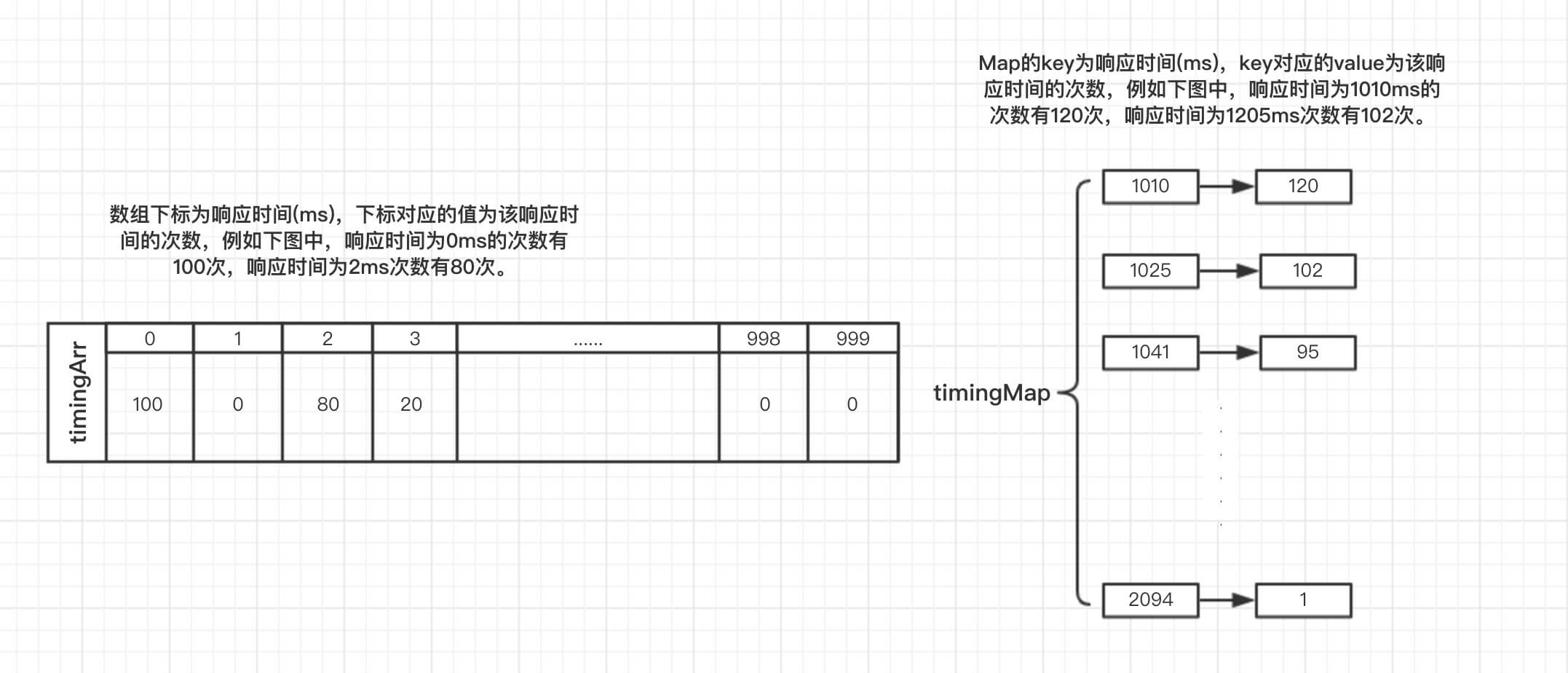 MyPerf4J 采用 数组(
MyPerf4J 采用 数组(timingArr) + Map(timingMap) 的方式把方法的响应时间存储到 Recorder 中:
- 在 timingArr 中,数组下标代表方法的响应时间,而下标对应的元素值代表该响应时间出现的次数,例如从上图中可以看出,timingArr 中记录了 100次 0ms 的响应,0次 1ms 的响应,80次 2ms 的响应 和 20次 3ms 的响应
- 在 timingMap 中,Map 的 key 代表方法的响应时间,而 key 对应的 value 代表该响应时间出现的次数,例如,从上图中可以看出,timingMap 中记录了 120次 1010ms 的响应,102次 1025ms 的响应,95次 1041ms 的响应,1次 2094ms 的响应。
假设你有 1024 个方法需要监控,并且 timingArr 长度为 1000,timingMap 大小为 128,Recorders 转盘的数量为 3
- 每个
timingArr占用 1000 * 4B = 4KB 的空间 - 每个
timingMap占用的空间大约为 128 * (96B + 4B) = 12.5KB,其中,每个 Map.Node 占用 96B
综上所述,监控这 1024 个方法只需要占用 3 * 1024 * (4KB + 12.5KB) = 49.5MB,并且这 49.5MB 的对象常驻在内存中,除了 timingMap 扩容和缩容时会分配少量内存外,所有的对象在 MyPerf4J 的整个生命周期中只分配一次!支持 弹性内存管理 后,MyPerf4J 可以降低数十倍的内存占用!
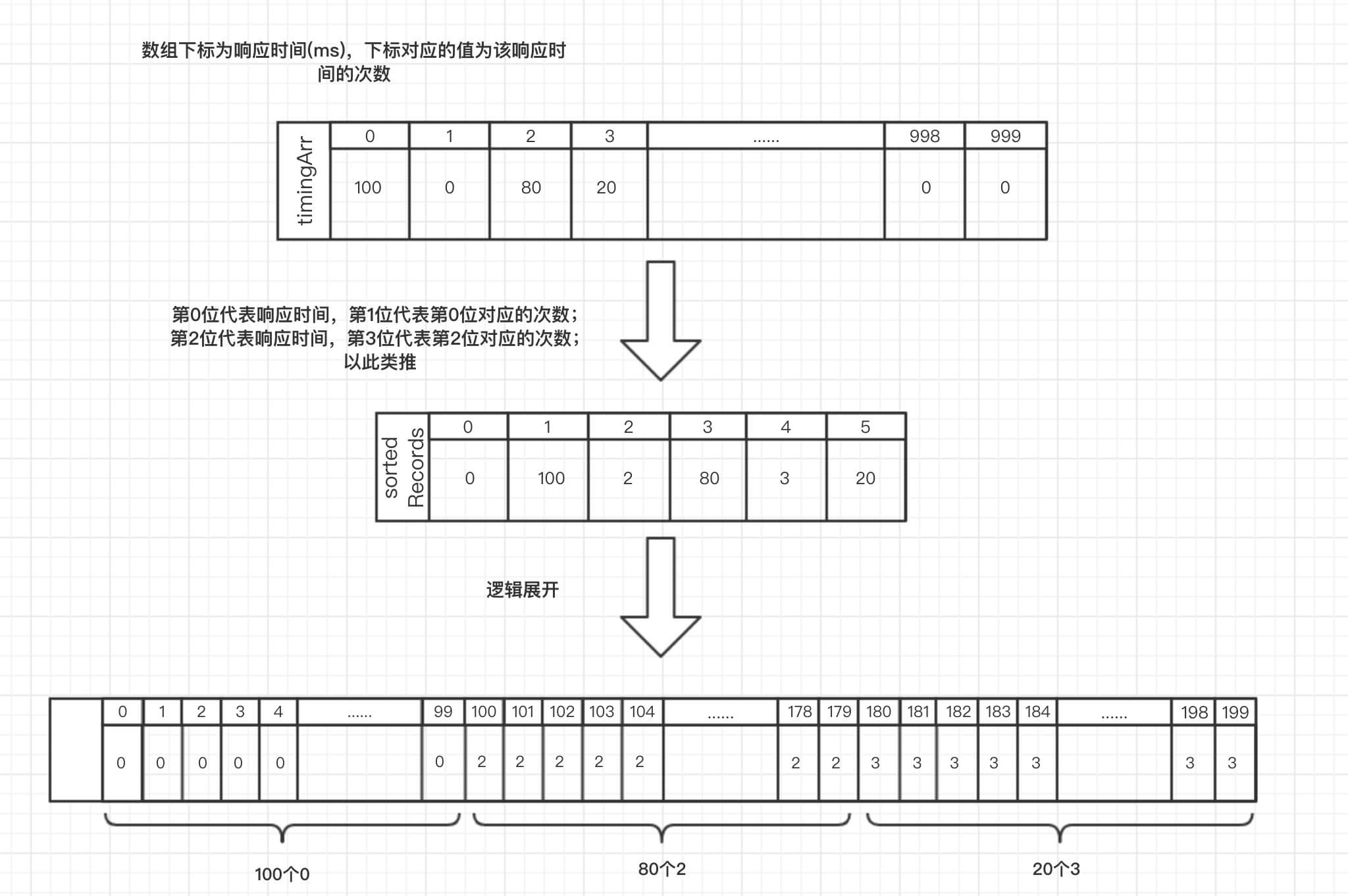 为简化处理流程,以 timingArr 为例进行说明:
为简化处理流程,以 timingArr 为例进行说明:
- 第一步,通过遍历一次 timingArr 可以计算出所有响应时间及其出现的次数,把这份数据存入 sortedRecords 中,在 sortedRecords 偶数下标代表响应时间,奇数下标代表次数,以上图为例,0ms 出现 100次,2ms 出现 80次,3ms 出现 20次。
- 第二步,把 sortedRecords 按逻辑展开,即可快速计算出 TP50、TP90 和 TP99 等指标,以上图为例,把 sortedRecords 按逻辑展开,可以得到连续存放的 100 个 0、80 个 2 和 20 个 3,一共 200 个响应时间,那么 TP50 对应于下标为 200 * 50% = 100 的值,也就是 2ms。
MyPerf4J 采用 Recorder 来记录方法的响应时间,采用 Recorders 存放同一个时间片内的所有 Recorder,采用 List<Recorders> 存放所有的 Recorders 并且维护一个 curIndex 指向当前时间片的 Recorders;所有的 Recorder 和 Recorders 均在应用启动时就分配好,当当前时间片结束时,curIndex 便指向 List<Recorders> 中下一个 Recorders 作为下一个时间片的 Recorders,并计算出当前时间片的性能指标,如此往复。
MyPerf4J 自 2.8.0 开始支持弹性内存管理,MyPerf4J 在应用启动时,会根据应用上一次运行期间的方法响应时间的分布计算出本次运行所需分配的内存,可以有效的减小每个 Recorder 的 timingArr 的大小,既可以大幅减少 MyPerf4J 的内存占用,也可以提高性能指标的计算速度!