Recientemente existen bastantes tutoriales y cursos sobre cómo generar texto a partir de redes neuronales y bastantes blogs de personas generando cambios de imágenes, entre otras cosas. Un uso novedoso de redes neuronales es la generación de música, de hecho, un ejemplo muy interesante y emocionante sobre esta novedad sería el generador de música de OpenAI, el cual cuenta con dos proyectos: Musenet, el cual genera música instrumental y la clasifica, y Jukebox el más novedoso de los dos y publicado recientemente, les recomiendo revisar más al respecto de este proyecto, porque está muy interesante ver su funcionamiento. Ahora, esto no será un tutorial como tal, más que nada mi enfoque es mostrarles este mundo tan interesante e invitarlos a que se sumen a este grupo de personas que estudian o intentan mejorar el mundo de las redes neuronales.
Redes tradicionales no tienen este beneficio lo cual podría considerarse un gran defecto, por ejemplo, digamos que ves una película y quieres clasificar cada punto de esta, una red neuronal no podría razonar puntos previos de la película para informar de los nuevos puntos, es por ello que recurrimos a utilizar redes neuronales recurrentes. En el siguiente diagrama podemos observar cómo funciona una red neural recurrente:

Imagenes obtenidas en el blog de colah, proporciono el vinculo en la seccion de agradecimientos.

La teoría establece que una red recurrente podría resolver este tipo de problemas, pero solamente si el programador escoge perfectamente los parámetros, ¡afortunadamente las LSTM no tienes estas limitaciones!
Una red recurrente y una LSTM tienen el diseño de cadena antes mostrado, la red recurrente normalmente tiene una estructura bastante simple como una simple capa tanh, mientras que la red LSTM tiene una estructura más compleja, pues dentro de cada módulo tiene cuatro capas que interactúan de una manera muy especial.


Función sigma/logística: esta previene saltos en los valores de salidas y tiende a tener predicciones claras cuando X es mayor a 2 o menor a -2, pero su computación es muy costosa.
Función tangente hiperbólica: es muy similar a la función sigma pero su principal diferencia es que es una función "zero centered", es decir que la media de esta función será cero, lo que ayuda a que se tenga una convergencia rápida.
Leaky ReLU: resuelve el problema de la ReLU tradicional agregando una pequeña inclinación positiva en el área negativa para permitir backpropagation incluso para valores negativos, el problema es que no da predicciones consistentes para valores negativos.
Parametric ReLU: introduce la inclinación de la parte negativa como argumento. Por lo tanto, es posible hacer backpropagation para aprender el valor de alpha más apropiado, el problema es que se puede desempeñar muy diferente para otros problemas.
Swish: es una nueva función de activación automática descubierta por los investigadores de Google, se cree que puede desempeñarse mejor que una ReLU con una eficiencia computacional similar, pueden leer más al respecto en este articulo.
Recientemente se está buscando una manera de automáticamente aprender cual es la función de activación óptima para cierta red y hasta automáticamente combinar funciones para obtener una precisión optima.
Music21 es una colección de herramientas que facilita a las personas la obtención de respuestas sobre música de forma eficaz y sencilla. Por ejemplo, dudas como: "Me pregunto cuántas veces Bach hace eso", "desearía conocer cuál fue la primer banda en usar ese progreso de acordes" o dudas como la mía, es decir, si quieres crear un programa el cual automáticamente genere más música como es mi caso.
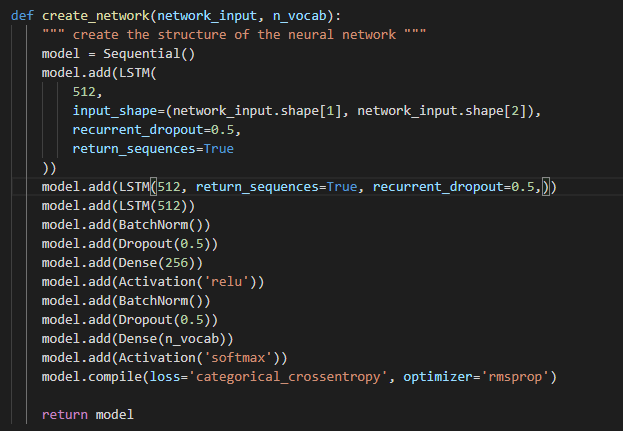
Capa LSTM: Toma una secuencia como entrada (input) y puede devolver una secuencia o una matriz.
Capa dropout (expulsar): Esta capa consiste en ajustar una fracción de entradas a 0 en cada actualización durante el entrenamiento para prevenir sobreajuste (overfitting), la fracción de entradas se determina por el parámetro usado con la capa.
Capa densa o Capa completamente conectada (fully connected): Es una capa de red neuronal donde cada nodo de entrada (input) está conectado con cada nodo de salida (output).
Capa de activación: Determina qué función de activación nuestra red neuronal usará para calcular el nodo la salida (output) de un nodo.
Para cada capa LSTM, densa y de activación el primer parámetro indica cuántos nodos la capa debe tener, en la capa dropout es la fracción de entradas (inputs) que se "soltarán" durante el entrenamiento. Para la primera capa debemos introducir un valor único llamado "input_shape", el cual se usa para informar a la red sobre los datos que está entrenando.
Como expliqué en la sección de LSTM, cada compuerta cuenta con su función de activación, en este modelo se utilizaron funciones ReLU y softmax, cada función tiene sus ventajas y desventajas, por lo que debes escoger las que mejor se ajusten a tu proyecto. Se usó ReLU (Rectified Linear Unit) ya que le permite a la red converger rápidamente y aunque la gráfica de esta función puede verse como una función lineal, su función derivada permite hacer "backpropagation", mientras que softmax permite manejar múltiples clases normalizando las salidas de cada clase entre 0 a 1 y divide por su suma, típicamente softmax es usado solamente para la capa de salida en redes que necesitan clasificar entradas a múltiples categorías.
En cuanto a mi entrenamiento, hice unas pruebas con el pipeline cambiando batches. Inicié con un batch de 32 al correr las primeras canciones con epoch de 150 para hacer pruebas rápidas, pero con 32 me generaba resultados que no eran de mi agrado o el tipo de música que buscaba, así que fui a 64 y el número de epochs a 250, pude haber aumentado el número a algo más alto para ver los resultados, pero debo decir que es un poco más tardado hacerlo. Mi plan a futuro es hacer entrenamientos con epochs más largos para hallar un punto donde sienta que es muy razonable el cambio o que la pérdida será mínima. Mucho de mi enfoque se centró en cambiar las capas: la cantidad de capas y la cantidad de neuronas por cada capa.
Un defecto que tiene ahorita el código es que cuando termina el entrenamiento te genera un numero de archivos hdf5 igual al número de epoch, el título de este archivo tiene el número de epoch y la pérdida, y cada vez que corras el predict.py para generar una nueva canción debes cambiar el archivo que busca al nuevo archivo hdf5. Esto a mí no me gustaba ya que es muy incómodo así que lo cambie para que el nombre del archivo no deba cambiarse.
Dato curioso: Normalmente el entrenamiento utilizando la supercomputadora de la Universidad de Sonora ACARUS me tomó alrededor de 3-4 horas con 250 epochs.
Chrono Trigger con 100 epoch
Chrono Trigger con 150 epoch
Chrono Trigger con 250 epoch
Mario Bros 3 con 100 epoch
Mario Bros 3 con 150 epoch
Mario Bros 3 con 250 epoch
The Legend of Zelda con 100 epoch
The Legend of Zelda con 150 epoch
The Legend of Zelda con 250 epoch
- A Sigurður Skúli por su blog sobre generación de música con LSTM, el codigo original también pueden hallarlo aquí.
- A Christopher Olah por su post sobre redes recurrentes y LSTM me ayudo a entender bastante y por las imágenes que fueron obtenidas de su blog.
- A la sección de funciones de activación de Missinglink por su guía de como escoger la mejor función de activación.
- A el Doctor Julio Waissman por sus clases sobre redes neuronales y apoyo con dudas.
- A la Profesora Sonia Sosa por su apoyo en cómo obtener la información y manejar mi método de trabajo, además de empujarme a poner lo mejor de mí en este proyecto.