{kind=link}
This repository contains the Tensorflow implementation of the paper ViSiL: Fine-grained Spatio-Temporal Video Similarity Learning. It provides code for the calculation of similarities between the query and database videos given by the user. Also, it contains an evaluation script to reproduce the results of the paper. The video similarity calculation is achieved by applying a frame-to-frame function that respects the spatial within-frame structure of videos and a learned video-to-video similarity function that also considers the temporal structure of videos.
The PyTorch implementation of ViSiL can be found here
- Python 3
- Tensorflow 1.xx (tested with 1.8-1.15)
- Clone this repo:
git clone https://github.com/MKLab-ITI/visil
cd visil- You can install all the dependencies by
pip install -r requirements.txt- Download and unzip the pretrained model:
wget http://ndd.iti.gr/visil/ckpt.zip
unzip ckpt.zip- If you want to use I3D as backbone network (used for AVR in the paper), then install the following packages:
# For tensoflow version >= 1.14
pip install tensorflow-probability==0.7 dm-sonnet==1.25
# For tensoflow version < 1.14
pip install tensorflow-probability==0.6 dm-sonnet==1.23-
Create a file that contains the query videos. Each line of the file have to contain a video id and a path to the corresponding video file, separated by a tab character (\t). Example:
wrC_Uqk3juY queries/wrC_Uqk3juY.mp4 k_NT43aJ_Jw queries/k_NT43aJ_Jw.mp4 2n30dbPBNKE queries/2n30dbPBNKE.mp4 ... -
Create a file with the same format for the database videos.
-
Run the following command to calculate the similarity between all the query and database videos
python calculate_similarity.py --query_file queries.txt --database_file database.txt --model_dir model/- For faster processing, you can load the query videos to the GPU memory by adding the flag
--load_queries
python calculate_similarity.py --query_file queries.txt --database_file database.txt --model_dir model/ --load_queries- The calculated similarities are stored to the file given to the
--output_file. The file is in JSON format and contains a dictionary with every query id as keys, and another dictionary that contains the similarities of the dataset videos to the corresponding queries as values. See the example below
{
"wrC_Uqk3juY": {
"KQh6RCW_nAo": 0.716,
"0q82oQa3upE": 0.300,
...},
"k_NT43aJ_Jw": {
"-KuR8y1gjJQ": 1.0,
"Xb19O5Iur44": 0.417,
...},
....
}
```- Add flag
--helpto display the detailed description for the arguments of the similarity calculation script
-q, --query_file QUERY_FILE Path to file that contains the query videos
-d, --database_file DATABASE_FILE Path to file that contains the database videos
-o, --output_file OUTPUT_FILE Name of the output file. Default: "results.json"
--network NETWORK Backbone network used for feature extraction.
Options: "resnet" or "i3d". Default: "resnet"
--model_dir MODEL_DIR Path to the directory of the pretrained model.
Default: "ckpt/resnet"
-s, --similarity_function SIMILARITY_FUNCTION Function that will be used to calculate the
similarity between query-candidate frames and
videos.Options: "chamfer" or "symmetric_chamfer".
Default: "chamfer"
--batch_sz BATCH_SZ Number of frames contained in each batch during
feature extraction. Default: 128
--gpu_id GPU_ID Id of the GPU used. Default: 0
-l, --load_queries Flag that indicates that the queries will be loaded to
the GPU memory.
--threads THREADS Number of threads used for video loading. Default: 8
-
We also provide code to reproduce the experiments in the paper.
-
First, download the videos of the dataset you want. The supported options are:
- CC_WEB_VIDEO - Near-Duplicate Video Retrieval
- FIVR-5K, FIVR-200K - Fine-grained Incident Video Retrieval
- EVVE - Event-based Video Retrieval
- ActivityNet - Action Video Retrieval
-
Determine the pattern based on the video id that the source videos are stored. For example, if all dataset videos are stored in a folder with filename the video id and the extension
.mp4, then the pattern is{id}.mp4. If each dataset video is stored in a different folder based on their video id with filenamevideo.mp4, then the pattern us{id}/video.mp4.- The code replaces the
{id}string with the id of the videos in the dataset - Also, it support supports Unix style pathname pattern expansion. For example, if video files have
various extension, then the pattern can be e.g.
{id}/video.* - For FIVR-200K, EVVE, ActivityNet, the Youtube ids are considered as the video ids
- For CC_WEB_VIDEO, video ids derives from the number of the query set that the video belongs to,
and the basename of the file. In particular, the video ids are in form
<number_of_query_set>/<basename>, e.g.1/1_1_Y
- The code replaces the
-
Run the
evaluation.pyby providing the name of the evaluation dataset, the path to video files, the pattern that the videos are stored
python evaluation.py --dataset FIVR-5K --video_dir /path/to/videos/ --pattern {id}/video.* --load_queries
Here is a toy example to run ViSiL on any data.
from model.visil import ViSiL
from datasets import load_video
# Load the two videos from the video files
query_video = load_video('/path/to/query/video')
target_video = load_video('/path/to/target/video')
# Initialize ViSiL model and load pre-trained weights
model = ViSiL('ckpt/resnet/')
# Extract features of the two videos
query_features = model.extract_features(query_video, batch_sz=32)
target_features = model.extract_features(target_video, batch_sz=32)
# Calculate similarity between the two videos
similarity = model.calculate_video_similarity(query_features, target_features)Thanks to @theycallmeloki for providing a Dockerfile to setup a docker container for the repo.
- First build a docker image based on the Dockerfile
docker build -t visil:latest .- Start a docker container based on the created docker image
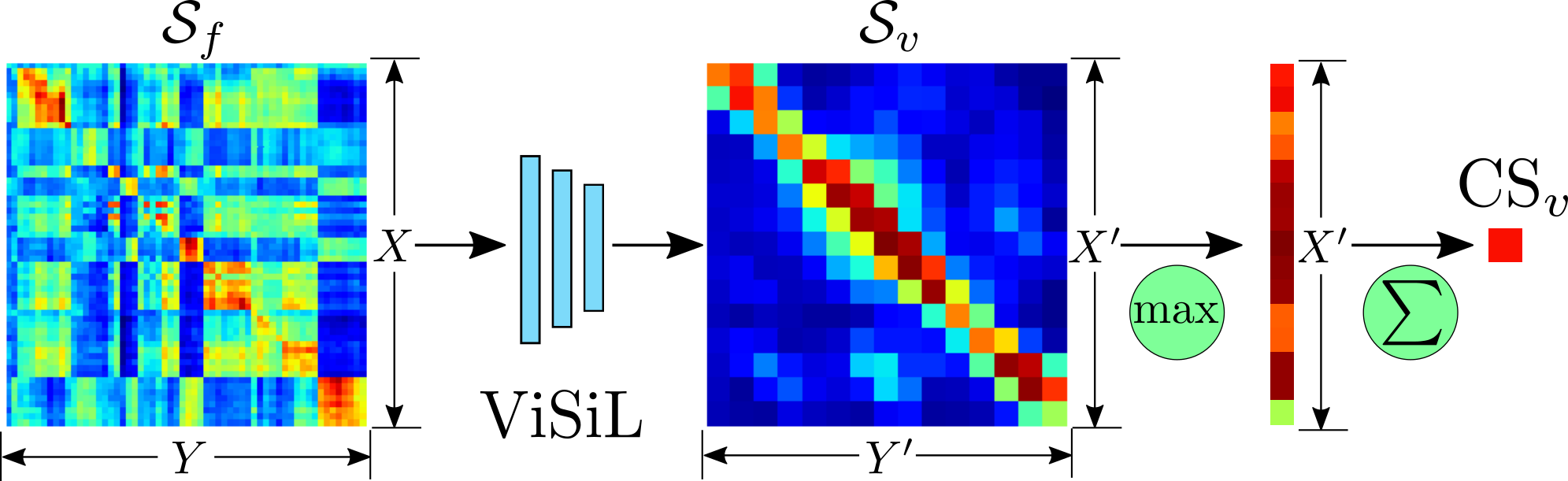
docker run -it --gpus all --name ViSiL visil:latestTo visualize similarity matrices and the ViSiL outputs, you may use this Colab notebook.
If you use this code for your research, please consider citing our paper:
@inproceedings{kordopatis2019visil,
title={{ViSiL}: Fine-grained Spatio-Temporal Video Similarity Learning},
author={Kordopatis-Zilos, Giorgos and Papadopoulos, Symeon and Patras, Ioannis and Kompatsiaris, Ioannis},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year={2019}
}DnS - improved performance and better computational efficiency
FIVR-200K - download our FIVR-200K dataset
This project is licensed under the Apache License 2.0 - see the LICENSE file for details
Giorgos Kordopatis-Zilos (georgekordopatis@iti.gr)