Circle ci: e2e test improvement for retrying failed develop branch #25955
Comments
Re-run from failedCircle ci supports an endpoint for re-run jobs from failed. Re-run failed testsAbout re-run failed tests, I've seen that there was a question in circle ci forum if this was supported in their API (Jul24) and they replied the following: Meaning that if there is 1 failure in an e2e job which takes ~10mins, we'll re-run the complete job again taking another 10mins. Compared to what we do now manually, where we just re-run the failed test, which usually takes just 1-2 more minutes, so this will increase ci usage. DiscussionShould we:
I think re-running e2e from failed can increase quite significantly circle ci usage and maybe it's not worth it? I'm personally fine re-running tests manually, it's a way for me to see which are the most recent failures/flakiness, but I understand not everyone might agree / be able to do so. What do you think? |
|
I don't see the added costs here as significant. Even if Our goal here is twofold: to determine whether failures on The consequences of choosing not to automate this are significant; this has been a significant burden for myself, Desi, and others who have taken on the work of triggering these re-runs manually. And we fairly often have poor response time to |
|
I agree with @Gudahtt, I would also re-run all failed jobs, including e2e. Time is the most expensive thing all of us can have, if we do not have to manually re-run the failed jobs, it is a huge benefit to all of us already. |
|
I would prefer --> |
<!-- Please submit this PR as a draft initially. Do not mark it as "Ready for review" until the template has been completely filled out, and PR status checks have passed at least once. --> ## **Description** This PR adds a new workflow in our circle ci config, called `rerun-from-failed` which does the following: 1. It gets the last 20 circle ci workflows from develop branch 2. It assesses if any of the workflows needs to be rerun. The conditions for a rerun are: a. The workflow has only been run once (not retried, or run multiple times, no matter its final status), this is to spare some credits and avoid re-runing multiple times the same jobs, but we could change this, and allow 2 runs instead of 1 for example, if we see that it's needed. b. The workflow is completed and has the status of `failed` c. The workflow runs in develop branch c. The workflow was triggered by the merge queue bot. This means that we won't rerun scheduled workflows (like the nightly ones). It didn't seem necessary to re-run those, but we can remove the filter, if we want 3. It reruns `from_failed` the workflows that have the conditions mentioned above. Note: the circle ci API does not support the `rerun_failed_tests` feature This new workflow can be scheduled by circle ci UI panel, and we can choose on which frequency we want it to run. Possibly once every hour (only Mon-Friday), but that's totally customizable from the UI. Our usage falls within the API limits, which are 51 requests per second per endpoint. In our case we will be doing: - 1 GET to get all workflows - 20 GET to get each workflow status - X POST (a max of 20) to rerun the corresponding failed jobs everytime we run the re-run-workflow. ### Implementation A few words around the implementation of this setup: - This setup uses the API token set in `process.env.API_V2_TOKEN` for authenticating the circle ci requests - This new workflow can be scheduled to be run once a day, twice etc.. depending on our needs, also from the circle ci ui, with the name `rerun-from-failed` - This new workflow can be enabled and disabled from the circle ci ui, just by removing the scheduled job The initial idea of adding a rerun logic embedded inside the test_and_release, and re-run right after, poses some challenges and that's why making a decoupled workflow and automate that by scheduling seems to solve those better. One issue is, how to make sure that we are not rerunning from failed forever. That might need additional logic and complexity for tracking the reruns for that specific workflow (possibly creating more artifacts and reading them) into the current workflow. Another issue is how to ensure that the workflow has finished (no matter if failed or successful) to then apply the rerun if needed: - if we used the `required` keyword, for making the rerun job the last one, that wouldn't serve us, as it would only be run if all jobs were successful (which doesn't solve our task) - we could run a job with a timer with ~30mins, so this would make sure that the workflow has finished (no matter, if failed or not) and then could rerun from failed calling the API. That would add additional resources to circle ci though - we could add a trigger if job fails `on_fail` to then trigger the rerun logic, but this would cancel ongoing parallel jobs, and it's not desired as we discussed - we could make that each job writes into an artifact their result, but the challenge again comes on when to trigger the read action to that file I found that decoupling the rerun and relying on their API could benefit in both challenges, as well as doesn't pollute the current ci config, making it a totally independent workflow, that can be customized by the UI. It also allow us to use more customizable rules, by accessing the state and number of runs of each workflow in a straight forward manner. Happy to discuss further though :) [](https://codespaces.new/MetaMask/metamask-extension/pull/28143?quickstart=1) ## **Related issues** Fixes: #25955 ## **Manual testing steps** 1. Check successful ci run for this new job (which in this example, it rerun 1 workflow from failed, successfully): https://app.circleci.com/pipelines/github/MetaMask/metamask-extension/110689/workflows/9ac7aaee-2610-4985-952d-6bd4f747c071/jobs/4141314 2. Create a branch of out this branch, and remove the filters in the config.yml file, so the new workflow is run. You can then check the result in circle ci ## **Screenshots/Recordings** See pipeline here: https://app.circleci.com/pipelines/github/MetaMask/metamask-extension/110689/workflows/9ac7aaee-2610-4985-952d-6bd4f747c071/jobs/4141314 It fetched 20 last workflows from develop, from those, it got it status, and [rerun only on workflow which complied](https://app.circleci.com/pipelines/github/MetaMask/metamask-extension/110625/workflows/af8d5617-a0bb-4d35-8b4f-72ac9812ccbb/jobs/4141316) with all requirements (not being rerun before, and with status failed) 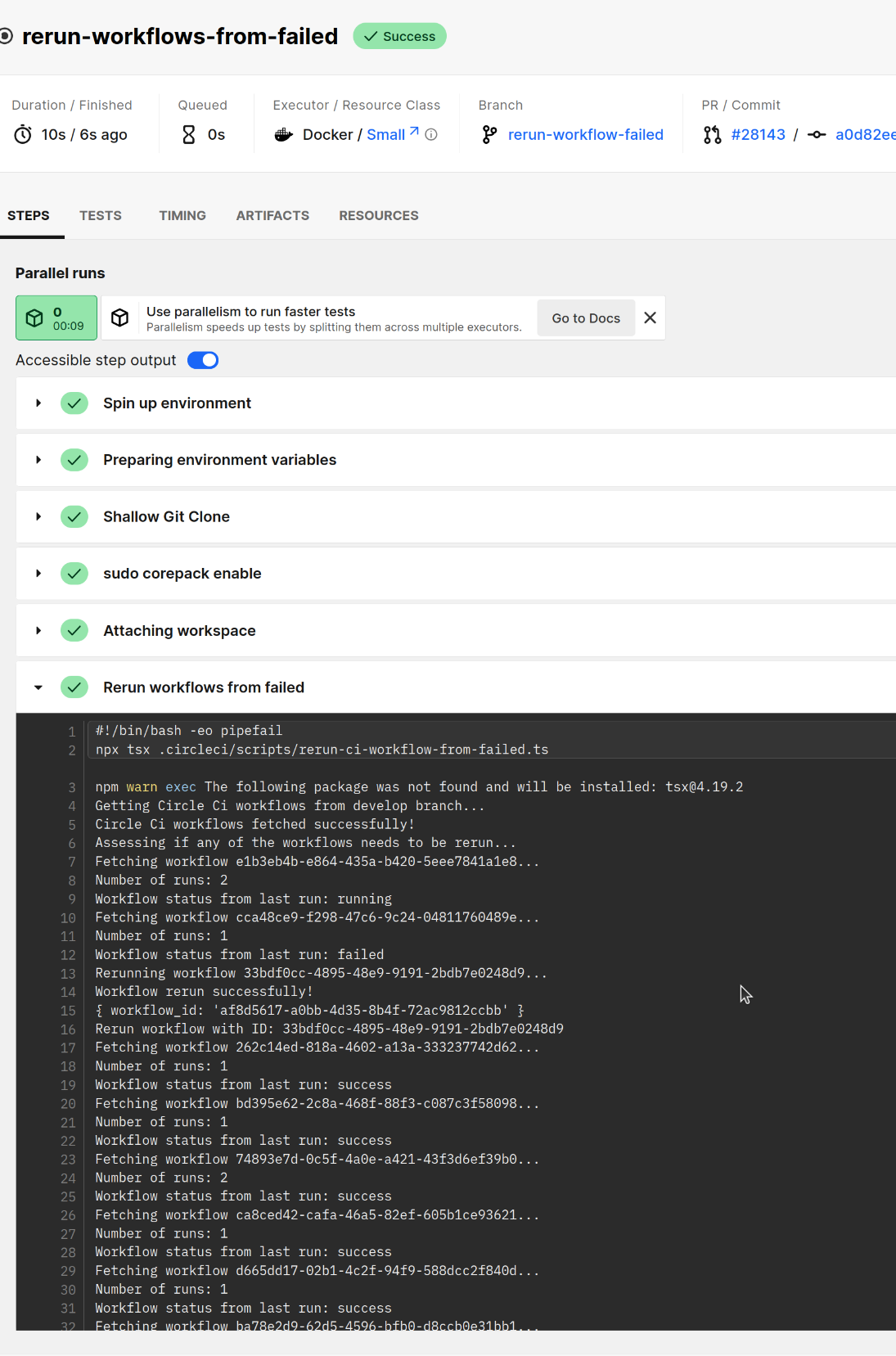 ## **Pre-merge author checklist** - [x] I've followed [MetaMask Contributor Docs](https://github.com/MetaMask/contributor-docs) and [MetaMask Extension Coding Standards](https://github.com/MetaMask/metamask-extension/blob/develop/.github/guidelines/CODING_GUIDELINES.md). - [x] I've completed the PR template to the best of my ability - [x] I’ve included tests if applicable - [x] I’ve documented my code using [JSDoc](https://jsdoc.app/) format if applicable - [x] I’ve applied the right labels on the PR (see [labeling guidelines](https://github.com/MetaMask/metamask-extension/blob/develop/.github/guidelines/LABELING_GUIDELINES.md)). Not required for external contributors. ## **Pre-merge reviewer checklist** - [ ] I've manually tested the PR (e.g. pull and build branch, run the app, test code being changed). - [ ] I confirm that this PR addresses all acceptance criteria described in the ticket it closes and includes the necessary testing evidence such as recordings and or screenshots. --------- Co-authored-by: Mark Stacey <markjstacey@gmail.com>
](https://codespaces.new/MetaMask/metamask-extension/pull/28143?quickstart=1){kind=link}
Following the thread here and suggested by @Gudahtt:
The text was updated successfully, but these errors were encountered: