PipelineX: Python package to build ML pipelines for experimentation with Kedro, MLflow, and more
PipelineX is a Python package to build ML pipelines for experimentation with Kedro, MLflow, and more
PipelineX provides the following options which can be used independently or together.
-
HatchDict: Python in YAML/JSON
HatchDictis a Python dict parser that enables you to include Python objects in YAML/JSON files.Note:
HatchDictcan be used with or without Kedro. -
Flex-Kedro: Kedro plugin for flexible config
-
Flex-Kedro-Pipeline: Kedro plugin for quicker pipeline set up
-
Flex-Kedro-Context: Kedro plugin for YAML lovers
-
-
MLflow-on-Kedro: Kedro plugin for MLflow users
MLflow-on-Kedroprovides integration of Kedro with MLflow with Kedro DataSets and Hooks.Note: You do not need to install MLflow if you do not use.
-
Kedro-Extras: Kedro plugin to use various Python packages
Kedro-Extrasprovides Kedro DataSets, decorators, and wrappers to use various Python packages such as:- <PyTorch>
- <Ignite>
- <Pandas>
- <OpenCV>
- <Memory Profiler>
- <NVIDIA Management Library>
Note: You do not need to install Python packages you do not use.
Please refer here to find out how PipelineX differs from other pipeline/workflow packages: Airflow, Luigi, Gokart, Metaflow, and Kedro.
pip install pipelinexThis is recommended only if you want to modify the source code of PipelineX.
git clone https://github.com/Minyus/pipelinex.git
cd pipelinex
python setup.py developYou can install packages and organize development environment with pipenv. Refer the pipenv document to install pipenv. Once you installed pipenv, you can use pipenv to install and organize your environment.
# install dependent libraries
$ pipenv install
# install development libraries
$ pipenv install --dev
# install pipelinex
$ pipenv run install
# install pipelinex via setup.py
$ pipenv run install_dev
# lint python code
$ pipenv run lint
# format python code
$ pipenv run fmt
# sort imports
$ pipenv run sort
# apply mypy to python code
$ pipenv run vet
# get into shell
$ pipenv shell
# run test
$ pipenv run testgit clone https://github.com/Minyus/pipelinex.git
cd pipelinex
docker build --tag pipelinex .
docker run --rm -it pipelinexKedro starters (Cookiecutter templates) to use Kedro, Scikit-learn, MLflow, and PipelineX are available at: kedro-starters-sklearn
Iris dataset is included and used, but you can easily change to Kaggle Titanic dataset.
-
-
parameters.ymlat conf/base/parameters.yml -
Essential packages: PyTorch, Ignite, Shap, Kedro, MLflow
-
Application: Image classification
-
Data: MNIST images
-
Model: CNN (Convolutional Neural Network)
-
Loss: Cross-entropy
-
-
Kaggle competition using PyTorch
-
parameters.ymlat kaggle/conf/base/parameters.yml -
Essential packages: PyTorch, Ignite, pandas, numpy, Kedro, MLflow
-
Application: Kaggle competition to predict the results of American Football plays
-
Data: Sparse heatmap-like field images and tabular data
-
Model: Combination of CNN and MLP
-
Loss: Continuous Rank Probability Score (CRPS)
-
-
parameters.ymlat conf/base/parameters.yml- Essential packages: OpenCV, Scikit-image, numpy, TensorFlow (pretrained model), Kedro, MLflow
- Application: Image processing to estimate the empty area ratio of cuboid container on a truck
- Data: container images
-
Uplift Modeling using CausalLift
parameters.ymlat conf/base/parameters.yml- Essential packages: CausalLift, Scikit-learn, XGBoost, pandas, Kedro
- Application: Uplift Modeling to find which customers should be targeted and which customers should not for a marketing campaign (treatment)
- Data: generated by simulation
YAML is a common text format used for application config files.
YAML's most notable advantage is allowing users to mix 2 styles, block style and flow style.
Example:
import yaml
from pprint import pprint # pretty-print for clearer look
# Read parameters dict from a YAML file in actual use
params_yaml="""
block_style_demo:
key1: value1
key2: value2
flow_style_demo: {key1: value1, key2: value2}
"""
parameters = yaml.safe_load(params_yaml)
print("### 2 styles in YAML ###")
pprint(parameters)### 2 styles in YAML ###
{'block_style_demo': {'key1': 'value1', 'key2': 'value2'},
'flow_style_demo': {'key1': 'value1', 'key2': 'value2'}}
To store highly nested (hierarchical) dict or list, YAML is more conveinient than hard-coding in Python code.
-
YAML's block style, which uses indentation, allows users to omit opening and closing symbols to specify a Python dict or list (
{}or[]). -
YAML's flow style, which uses opening and closing symbols, allows users to specify a Python dict or list within a single line.
So simply using YAML with Python will be the best way for Machine Learning experimentation?
Let's check out the next example.
Example:
import yaml
from pprint import pprint # pretty-print for clearer look
# Read parameters dict from a YAML file in actual use
params_yaml = """
model_kind: LogisticRegression
model_params:
C: 1.23456
max_iter: 987
random_state: 42
"""
parameters = yaml.safe_load(params_yaml)
print("### Before ###")
pprint(parameters)
model_kind = parameters.get("model_kind")
model_params_dict = parameters.get("model_params")
if model_kind == "LogisticRegression":
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(**model_params_dict)
elif model_kind == "DecisionTree":
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(**model_params_dict)
elif model_kind == "RandomForest":
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(**model_params_dict)
else:
raise ValueError("Unsupported model_kind.")
print("\n### After ###")
print(model)### Before ###
{'model_kind': 'LogisticRegression',
'model_params': {'C': 1.23456, 'max_iter': 987, 'random_state': 42}}
### After ###
LogisticRegression(C=1.23456, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=987,
multi_class='warn', n_jobs=None, penalty='l2',
random_state=42, solver='warn', tol=0.0001, verbose=0,
warm_start=False)
This way is inefficient as we need to add import and if statements for the options in the Python code in addition to modifying the YAML config file.
Any better way?
PyYAML provides UnsafeLoader which can load Python objects without import.
Example usage of !!python/object
import yaml
# You do not need `import sklearn.linear_model` using PyYAML's UnsafeLoader
# Read parameters dict from a YAML file in actual use
params_yaml = """
model:
!!python/object:sklearn.linear_model.LogisticRegression
C: 1.23456
max_iter: 987
random_state: 42
"""
parameters = yaml.unsafe_load(params_yaml) # unsafe_load required
model = parameters.get("model")
print("### model object by PyYAML's UnsafeLoader ###")
print(model)### model object by PyYAML's UnsafeLoader ###
LogisticRegression(C=1.23456, class_weight=None, dual=None, fit_intercept=None,
intercept_scaling=None, l1_ratio=None, max_iter=987,
multi_class=None, n_jobs=None, penalty=None, random_state=42,
solver=None, tol=None, verbose=None, warm_start=None)
Example usage of !!python/name
import yaml
# Read parameters dict from a YAML file in actual use
params_yaml = """
numpy_array_func:
!!python/name:numpy.array
"""
try:
parameters = yaml.unsafe_load(params_yaml) # unsafe_load required for PyYAML 5.1 or later
except:
parameters = yaml.load(params_yaml)
numpy_array_func = parameters.get("numpy_array_func")
import numpy
assert numpy_array_func == numpy.arrayPyYAML's !!python/object and !!python/name, however, has the following problems.
!!python/objector!!python/nameare too long to write.- Positional (unnamed) arguments are apparently not supported.
Any better way?
PipelineX provides the solution.
PipelineX's HatchDict provides an easier syntax, as follows, to convert Python dictionaries read from YAML or JSON files to Python objects without import.
- Use
=key to specify the package, module, and class/function with.separator infoo_package.bar_module.baz_classformat. - [Optional] Use
_key to specify (list of) positional (unnamed) arguments if any. - [Optional] Add keyword arguments (kwargs) if any.
To return an object instance like PyYAML's !!python/object, feed positional and/or keyword arguments. If it has no arguments, just feed null (known as None in Python) to _ key.
To return an uninstantiated (raw) object like PyYAML's !!python/name, just feed = key without any arguments.
Example alternative to !!python/object specifying keyword arguments:
from pipelinex import HatchDict
import yaml
from pprint import pprint # pretty-print for clearer look
# You do not need `import sklearn.linear_model` using PipelineX's HatchDict
# Read parameters dict from a YAML file in actual use
params_yaml="""
model:
=: sklearn.linear_model.LogisticRegression
C: 1.23456
max_iter: 987
random_state: 42
"""
parameters = yaml.safe_load(params_yaml)
model_dict = parameters.get("model")
print("### Before ###")
pprint(model_dict)
model = HatchDict(parameters).get("model")
print("\n### After ###")
print(model)### Before ###
{'=': 'sklearn.linear_model.LogisticRegression',
'C': 1.23456,
'max_iter': 987,
'random_state': 42}
### After ###
LogisticRegression(C=1.23456, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=987,
multi_class='warn', n_jobs=None, penalty='l2',
random_state=42, solver='warn', tol=0.0001, verbose=0,
warm_start=False)
Example alternative to !!python/object specifying both positional and keyword arguments:
from pipelinex import HatchDict
import yaml
from pprint import pprint # pretty-print for clearer look
params_yaml = """
metrics:
- =: functools.partial
_:
=: sklearn.metrics.roc_auc_score
multiclass: ovr
"""
parameters = yaml.safe_load(params_yaml)
metrics_dict = parameters.get("metrics")
print("### Before ###")
pprint(metrics_dict)
metrics = HatchDict(parameters).get("metrics")
print("\n### After ###")
print(metrics)### Before ###
[{'=': 'functools.partial',
'_': {'=': 'sklearn.metrics.roc_auc_score'},
'multiclass': 'ovr'}]
### After ###
[functools.partial(<function roc_auc_score at 0x16bcf19d0>, multiclass='ovr')]
Example alternative to !!python/name:
from pipelinex import HatchDict
import yaml
# Read parameters dict from a YAML file in actual use
params_yaml="""
numpy_array_func:
=: numpy.array
"""
parameters = yaml.safe_load(params_yaml)
numpy_array_func = HatchDict(parameters).get("numpy_array_func")
import numpy
assert numpy_array_func == numpy.arrayThis import-less Python object supports nested objects (objects that receives object arguments) by recursive depth-first search.
For more examples, please see Use with PyTorch.
This import-less Python object feature, inspired by the fact that Kedro uses load_obj for file I/O (DataSet), uses load_obj copied from kedro.utils which dynamically imports Python objects using importlib, a Python standard library.
To avoid repeating, YAML natively provides Anchor&Alias Anchor&Alias feature, and Jsonnet provides Variable feature to JSON.
Example:
import yaml
from pprint import pprint # pretty-print for clearer look
# Read parameters dict from a YAML file in actual use
params_yaml="""
train_params:
train_batch_size: &batch_size 32
val_batch_size: *batch_size
"""
parameters = yaml.safe_load(params_yaml)
train_params_dict = parameters.get("train_params")
print("### Conversion by YAML's Anchor&Alias feature ###")
pprint(train_params_dict)### Conversion by YAML's Anchor&Alias feature ###
{'train_batch_size': 32, 'val_batch_size': 32}
Unfortunately, YAML and Jsonnet require a medium to share the same value.
This is why PipelineX provides anchor-less aliasing feature.
You can directly look up another value in the same YAML/JSON file using "$" key without an anchor nor variable.
To specify the nested key (key in a dict of dict), use "." as the separator.
Example:
from pipelinex import HatchDict
import yaml
from pprint import pprint # pretty-print for clearer look
# Read parameters dict from a YAML file in actual use
params_yaml="""
train_params:
train_batch_size: 32
val_batch_size: {$: train_params.train_batch_size}
"""
parameters = yaml.safe_load(params_yaml)
train_params_dict = parameters.get("train_params")
print("### Before ###")
pprint(train_params_dict)
train_params = HatchDict(parameters).get("train_params")
print("\n### After ###")
pprint(train_params)### Before ###
{'train_batch_size': 32,
'val_batch_size': {'$': 'train_params.train_batch_size'}}
### After ###
{'train_batch_size': 32, 'val_batch_size': 32}
Strings wrapped in parentheses are evaluated as a Python expression.
from pipelinex import HatchDict
import yaml
from pprint import pprint # pretty-print for clearer look
# Read parameters dict from a YAML file in actual use
params_yaml = """
train_params:
param1_tuple_python: (1, 2, 3)
param1_tuple_yaml: !!python/tuple [1, 2, 3]
param2_formula_python: (2 + 3)
param3_neg_inf_python: (float("-Inf"))
param3_neg_inf_yaml: -.Inf
param4_float_1e9_python: (1e9)
param4_float_1e9_yaml: 1.0e+09
param5_int_1e9_python: (int(1e9))
"""
parameters = yaml.load(params_yaml)
train_params_raw = parameters.get("train_params")
print("### Before ###")
pprint(train_params_raw)
train_params_converted = HatchDict(parameters).get("train_params")
print("\n### After ###")
pprint(train_params_converted)### Before ###
{'param1_tuple_python': '(1, 2, 3)',
'param1_tuple_yaml': (1, 2, 3),
'param2_formula_python': '(2 + 3)',
'param3_neg_inf_python': '(float("-Inf"))',
'param3_neg_inf_yaml': -inf,
'param4_float_1e9_python': '(1e9)',
'param4_float_1e9_yaml': 1000000000.0,
'param5_int_1e9_python': '(int(1e9))'}
### After ###
{'param1_tuple_python': (1, 2, 3),
'param1_tuple_yaml': (1, 2, 3),
'param2_formula_python': 5,
'param3_neg_inf_python': -inf,
'param3_neg_inf_yaml': -inf,
'param4_float_1e9_python': 1000000000.0,
'param4_float_1e9_yaml': 1000000000.0,
'param5_int_1e9_python': 1000000000}
Machine Learning projects involves with loading and saving various data in various ways such as:
- files in local/network file system, Hadoop Distributed File System (HDFS), Amazon S3, Google Cloud Storage
- e.g. CSV, JSON, YAML, pickle, images, models, etc.
- databases
- Postgresql, MySQL etc.
- Spark
- REST API (HTTP(S) requests)
It is often the case that many Machine Learning Engineers code both data loading/saving and data transformation mixed in the same Python module or Jupyter notebook during experimentation/prototyping phase and suffer later on because:
- During experimentation/prototyping, we often want to save the intermediate data after each transformation.
- In production environments, we often want to skip saving data to minimize latency and storage space.
- To benchmark the performance or troubleshoot, we often want to switch the data source.
- e.g. read image files in local storage or download images through REST API
The proposed solution is the unified data interface.
Here is a simple demo example to predict survival on the Titanic.
 Pipeline visualized by Kedro-viz
Pipeline visualized by Kedro-viz
Common code to define the tasks/operations/transformations:
# Define tasks
def train_model(model, df, cols_features, col_target):
# train a model here
return model
def run_inference(model, df, cols_features):
# run inference here
return dfIt is notable that you do not need to add any Kedro-related code here to use Kedro later on.
Furthermore, you do not need to add any MLflow-related code here to use MLflow later on as Kedro hooks provided by PipelineX can handle behind the scenes.
This advantage enables you to keep your pipelines for experimentation/prototyping/benchmarking production-ready.
- Plain code:
# Configure: can be written in a config file (YAML, JSON, etc.)
train_data_filepath = "data/input/train.csv"
train_data_load_args = {"float_precision": "high"}
test_data_filepath = "data/input/test.csv"
test_data_load_args = {"float_precision": "high"}
pred_data_filepath = "data/load/pred.csv"
pred_data_save_args = {"index": False, "float_format": "%.16e"}
model_kind = "LogisticRegression"
model_params_dict = {
"C": 1.23456
"max_iter": 987
"random_state": 42
}
# Run tasks
import pandas as pd
if model_kind == "LogisticRegression":
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(**model_params_dict)
train_df = pd.read_csv(train_data_filepath, **train_data_load_args)
model = train_model(model, train_df)
test_df = pd.read_csv(test_data_filepath, **test_data_load_args)
pred_df = run_inference(model, test_df)
pred_df.to_csv(pred_data_filepath, **pred_data_save_args)- Following the data interface framework, objects with
_load, and_savemethods, proposed by Kedro and supported by PipelineX:
# Define a data interface: better ones such as "CSVDataSet" are provided by Kedro
import pandas as pd
from pathlib import Path
class CSVDataSet:
def __init__(self, filepath, load_args={}, save_args={}):
self._filepath = filepath
self._load_args = {}
self._load_args.update(load_args)
self._save_args = {"index": False}
self._save_args.update(save_args)
def _load(self) -> pd.DataFrame:
return pd.read_csv(self._filepath, **self._load_args)
def _save(self, data: pd.DataFrame) -> None:
save_path = Path(self._filepath)
save_path.parent.mkdir(parents=True, exist_ok=True)
data.to_csv(str(save_path), **self._save_args)
# Configure data interface: can be written in catalog config file using Kedro
train_dataset = CSVDataSet(
filepath="data/input/train.csv",
load_args={"float_precision": "high"},
# save_args={"float_format": "%.16e"}, # You can set save_args for future use
)
test_dataset = CSVDataSet(
filepath="data/input/test.csv",
load_args={"float_precision": "high"},
# save_args={"float_format": "%.16e"}, # You can set save_args for future use
)
pred_dataset = CSVDataSet(
filepath="data/load/pred.csv",
# load_args={"float_precision": "high"}, # You can set load_args for future use
save_args={"float_format": "%.16e"},
)
model_kind = "LogisticRegression"
model_params_dict = {
"C": 1.23456
"max_iter": 987
"random_state": 42
}
cols_features = [
"Pclass", # The passenger's ticket class
"Parch", # # of parents / children aboard the Titanic
]
col_target = "Survived" # Column used as the target: whether the passenger survived or not
# Run tasks: can be configured as a pipeline using Kedro
# and can be written in parameters config file using PipelineX
if model_kind == "LogisticRegression":
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(**model_params_dict)
train_df = train_dataset._load()
model = train_model(model, train_df, cols_features, col_target)
test_df = test_dataset._load()
pred_df = run_inference(model, test_df, cols_features)
pred_dataset._save(pred_df)Just following the data interface framework might be somewhat beneficial in the long run, but not enough.
Let's see what Kedro and PipelineX can do.
Kedro is a Python package to develop pipelines consisting of:
-
data interface sets (data loading/saving wrappers, called "DataSets", that follows the unified data interface framework) such as:
pandas.CSVDataSet: a CSV file in local or cloud (Amazon S3, Google Cloud Storage) utilizing filesystem_spec (fsspec)pickle.PickleDataSet: a pickle file in local or cloud (Amazon S3, Google Cloud Storage) utilizing filesystem_spec (fsspec)pandas.SQLTableDataSet: a table data in an SQL database supported by SQLAlchemy- data interface sets for Spark, Google BigQuery, Feather, HDF, Parquet, Matplotlib, NetworkX, Excel, and more provided by Kedro
- Custom data interface sets provided by Kedro users
-
tasks/operations/transformations (called "Nodes") provided by Kedro users such as:
- data pre-processing
- training a model
- inference using a model
-
inter-task dependency provided by Kedro users
Kedro pipelines can be run sequentially or in parallel.
Regarding Kedro, please see:
- <Kedro's document>
- <YouTube playlist: Writing Data Pipelines with Kedro>
- <Python Packages for Pipeline/Workflow>
Here is a simple example Kedro project.
# catalog.yml
train_df:
type: pandas.CSVDataSet # short for kedro.extras.datasets.pandas.CSVDataSet
filepath: data/input/train.csv
load_args:
float_precision: high
# save_args: # You can set save_args for future use
# float_format": "%.16e"
test_df:
type: pandas.CSVDataSet # short for kedro.extras.datasets.pandas.CSVDataSet
filepath: data/input/test.csv
load_args:
float_precision: high
# save_args: # You can set save_args for future use
# float_format": "%.16e"
pred_df:
type: pandas.CSVDataSet # short for kedro.extras.datasets.pandas.CSVDataSet
filepath: data/load/pred.csv
# load_args: # You can set load_args for future use
# float_precision: high
save_args:
float_format: "%.16e"# parameters.yml
model:
!!python/object:sklearn.linear_model.LogisticRegression
C: 1.23456
max_iter: 987
random_state: 42
cols_features: # Columns used as features in the Titanic data table
- Pclass # The passenger's ticket class
- Parch # # of parents / children aboard the Titanic
col_target: Survived # Column used as the target: whether the passenger survived or not# pipeline.py
from kedro.pipeline import Pipeline, node
from my_module import train_model, run_inference
def create_pipeline(**kwargs):
return Pipeline(
[
node(
func=train_model,
inputs=["params:model", "train_df", "params:cols_features", "params:col_target"],
outputs="model",
),
node(
func=run_inference,
inputs=["model", "test_df", "params:cols_features"],
outputs="pred_df",
),
]
)# run.py
from kedro.runner import SequntialRunner
# Set up ProjectContext here
context = ProjectContext()
context.run(pipeline_name="__default__", runner=SequentialRunner())Kedro pipelines can be visualized using kedro-viz.
Kedro pipelines can be productionized using:
- kedro-airflow: converts a Kedro pipeline into Airflow Python operators.
- kedro-docker: builds a Docker image that can run a Kedro pipeline
- kedro-argo: converts a Kedro pipeline into an Argo (backend of Kubeflow) pipeline
Flex-Kedro provides more options to configure Kedro projects flexibly and thus quickly by KFlex-Kedro-Pipeline and Flex-Kedro-Context features.
If you want to define Kedro pipelines quickly, you can consider to use pipelinex.FlexiblePipeline instead of kedro.pipeline.Pipeline.
pipelinex.FlexiblePipeline adds the following options to kedro.pipeline.Pipeline.
To define each node, dict can be used instead of kedro.pipeline.node.
Example:
pipelinex.FlexiblePipeline(
nodes=[dict(func=task_func1, inputs="my_input", outputs="my_output")]
)will be equivalent to:
kedro.pipeline.Pipeline(
nodes=[
kedro.pipeline.node(func=task_func1, inputs="my_input", outputs="my_output")
]
)For sub-pipelines consisting of nodes of only single input and single output, you can optionally use Sequential API similar to PyTorch (torch.nn.Sequential) and Keras (tf.keras.Sequential)
Example:
pipelinex.FlexiblePipeline(
nodes=[
dict(
func=[task_func1, task_func2, task_func3],
inputs="my_input",
outputs="my_output",
)
]
)will be equivalent to:
kedro.pipeline.Pipeline(
nodes=[
kedro.pipeline.node(
func=task_func1, inputs="my_input", outputs="my_output__001"
),
kedro.pipeline.node(
func=task_func2, inputs="my_output__001", outputs="my_output__002"
),
kedro.pipeline.node(
func=task_func3, inputs="my_output__002", outputs="my_output"
),
]
)-
Optionally specify the Python function decorator(s) to apply to multiple nodes under the pipeline using
decoratorargument instead of usingdecoratemethod ofkedro.pipeline.Pipeline.Example:
pipelinex.FlexiblePipeline( nodes=[ kedro.pipeline.node(func=task_func1, inputs="my_input", outputs="my_output") ], decorator=[task_deco, task_deco], )
will be equivalent to:
kedro.pipeline.Pipeline( nodes=[ kedro.pipeline.node(func=task_func1, inputs="my_input", outputs="my_output") ] ).decorate(task_deco, task_deco)
-
Optionally specify the default python module (path of .py file) if you do not want to repeat the same (deep and/or long) Python module (e.g.
foo.bar.my_task1,foo.bar.my_task2, etc.)
If you want to take advantage of YAML more than Kedro supports, you can consider to use
pipelinex.FlexibleContext instead of kedro.framework.context.KedroContext.
pipelinex.FlexibleContext adds preprocess of parameters.yml and catalog.yml to kedro.framework.context.KedroContext to provide flexibility.
This option is for YAML lovers only.
If you don't like YAML very much, skip this one.
You can define the inter-task dependency (DAG) for Kedro pipelines in parameters.yml using PIPELINES key. To define each Kedro pipeline, you can use the kedro.pipeline.Pipeline or its variant such as pipelinex.FlexiblePipeline as shown below.
# parameters.yml
PIPELINES:
__default__:
=: pipelinex.FlexiblePipeline
module: # Optionally specify the default Python module so you can omit the module name to which functions belongs
decorator: # Optionally specify function decorator(s) to apply to each node
nodes:
- inputs: ["params:model", train_df, "params:cols_features", "params:col_target"]
func: sklearn_demo.train_model
outputs: model
- inputs: [model, test_df, "params:cols_features"]
func: sklearn_demo.run_inference
outputs: pred_dfYou can specify the run config in parameters.yml using RUN_CONFIG key instead of specifying the args for kedro run command for every run.
You can still set the args for kedro run to overwrite.
In addition to the args for kedro run, you can opt to run only missing nodes (skip tasks which have already been run to resume pipeline using the intermediate data files or databases.) by only_missing key.
# parameters.yml
RUN_CONFIG:
pipeline_name: __default__
runner: SequentialRunner # Set to "ParallelRunner" to run in parallel
only_missing: False # Set True to run only missing nodes
tags: # None
node_names: # None
from_nodes: # None
to_nodes: # None
from_inputs: # None
load_versions: # NoneYou can use HatchDict feature in parameters.yml.
# parameters.yml
model:
=: sklearn.linear_model.LogisticRegression
C: 1.23456
max_iter: 987
random_state: 42
cols_features: # Columns used as features in the Titanic data table
- Pclass # The passenger's ticket class
- Parch # # of parents / children aboard the Titanic
col_target: Survived # Column used as the target: whether the passenger survived or notEnable caching using cached key set to True if you do not want Kedro to load the data from disk/database which were in the memory. (kedro.io.CachedDataSet is used under the hood.)
You can use HatchDict feature in catalog.yml.
Kedro DataSet and Hooks (callbacks) are provided to use MLflow without adding any MLflow-related code in the node (task) functions.
-
Kedro Dataset that saves data to or loads data from MLflow depending on
datasetargument as follows.-
If set to "p", the value will be saved/loaded as an MLflow parameter (string).
-
If set to "m", the value will be saved/loaded as an MLflow metric (numeric).
-
If set to "a", the value will be saved/loaded based on the data type.
-
If the data type is either {float, int}, the value will be saved/loaded as an MLflow metric.
-
If the data type is either {str, list, tuple, set}, the value will be saved/load as an MLflow parameter.
-
If the data type is dict, the value will be flattened with dot (".") as the separator and then saved/loaded as either an MLflow metric or parameter based on each data type as explained above.
-
-
If set to either {"json", "csv", "xls", "parquet", "png", "jpg", "jpeg", "img", "pkl", "txt", "yml", "yaml"}, the backend dataset instance will be created accordingly to save/load as an MLflow artifact.
-
If set to a Kedro DataSet object or a dictionary, it will be used as the backend dataset to save/load as an MLflow artifact.
-
If set to None (default), MLflow logging will be skipped.
Regarding all the options, please see the API document
-
-
Kedro Hooks
-
pipelinex.MLflowBasicLoggerHook: Configures MLflow logging and logs duration time for the pipeline to MLflow. -
pipelinex.MLflowArtifactsLoggerHook: Logs artifacts of specified file paths and dataset names to MLflow. -
pipelinex.MLflowDataSetsLoggerHook: Logs datasets of (list of) float/int and str classes to MLflow. -
pipelinex.MLflowTimeLoggerHook: Logs duration time for each node (task) to MLflow and optionally visualizes the execution logs as a Gantt chart byplotly.figure_factory.create_ganttifplotlyis installed. -
pipelinex.AddTransformersHook: Adds Kedro transformers such as:pipelinex.MLflowIOTimeLoggerTransformer: Logs duration time to load and save each dataset with args:
Regarding all the options, please see the API document
-
MLflow-ready Kedro projects can be generated by the Kedro starters (Cookiecutter template) which include the following example config:
# catalog.yml
# Write a pickle file & upload to MLflow
model:
type: pipelinex.MLflowDataSet
dataset: pkl
# Write a csv file & upload to MLflow
pred_df:
type: pipelinex.MLflowDataSet
dataset: csv
# Write an MLflow metric
score:
type: pipelinex.MLflowDataSet
dataset: m # catalog.py (alternative to catalog.yml)
catalog_dict = {
"model": MLflowDataSet(dataset="pkl"), # Write a pickle file & upload to MLflow
"pred_df": MLflowDataSet(dataset="csv"), # Write a csv file & upload to MLflow
"score": MLflowDataSet(dataset="m"), # Write an MLflow metric
}# mlflow_config.py
import pipelinex
mlflow_hooks = (
pipelinex.MLflowBasicLoggerHook(
uri="sqlite:///mlruns/sqlite.db",
experiment_name="experiment_001",
artifact_location="./mlruns/experiment_001",
offset_hours=0,
),
pipelinex.MLflowCatalogLoggerHook(
auto=True,
),
pipelinex.MLflowArtifactsLoggerHook(
filepaths_before_pipeline_run=["conf/base/parameters.yml"],
filepaths_after_pipeline_run=[
"info.log",
"errors.log",
],
),
pipelinex.MLflowEnvVarsLoggerHook(
param_env_vars=["HOSTNAME"],
metric_env_vars=[],
),
pipelinex.MLflowTimeLoggerHook(),
)
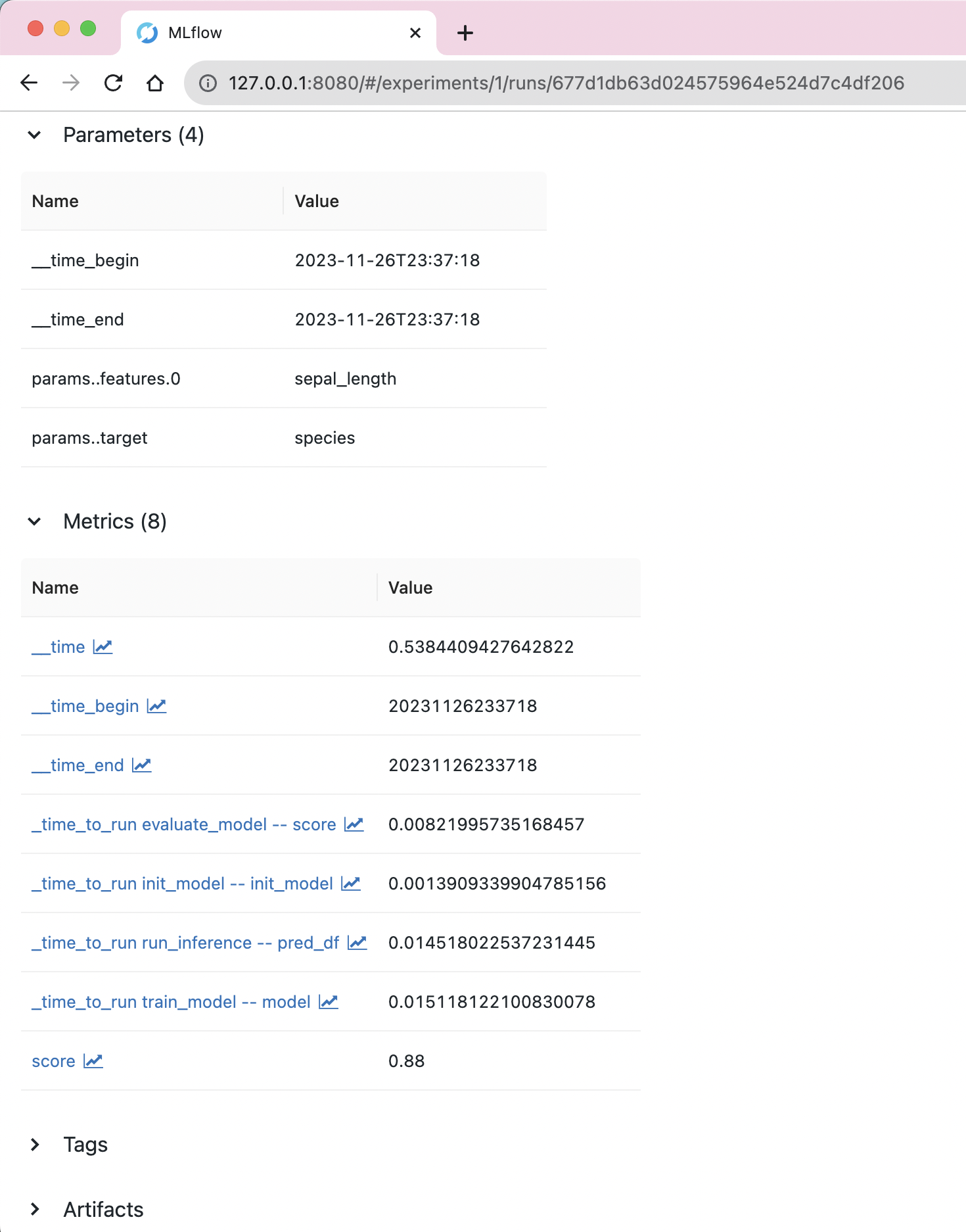 Logged metrics shown in MLflow's UI
Logged metrics shown in MLflow's UI
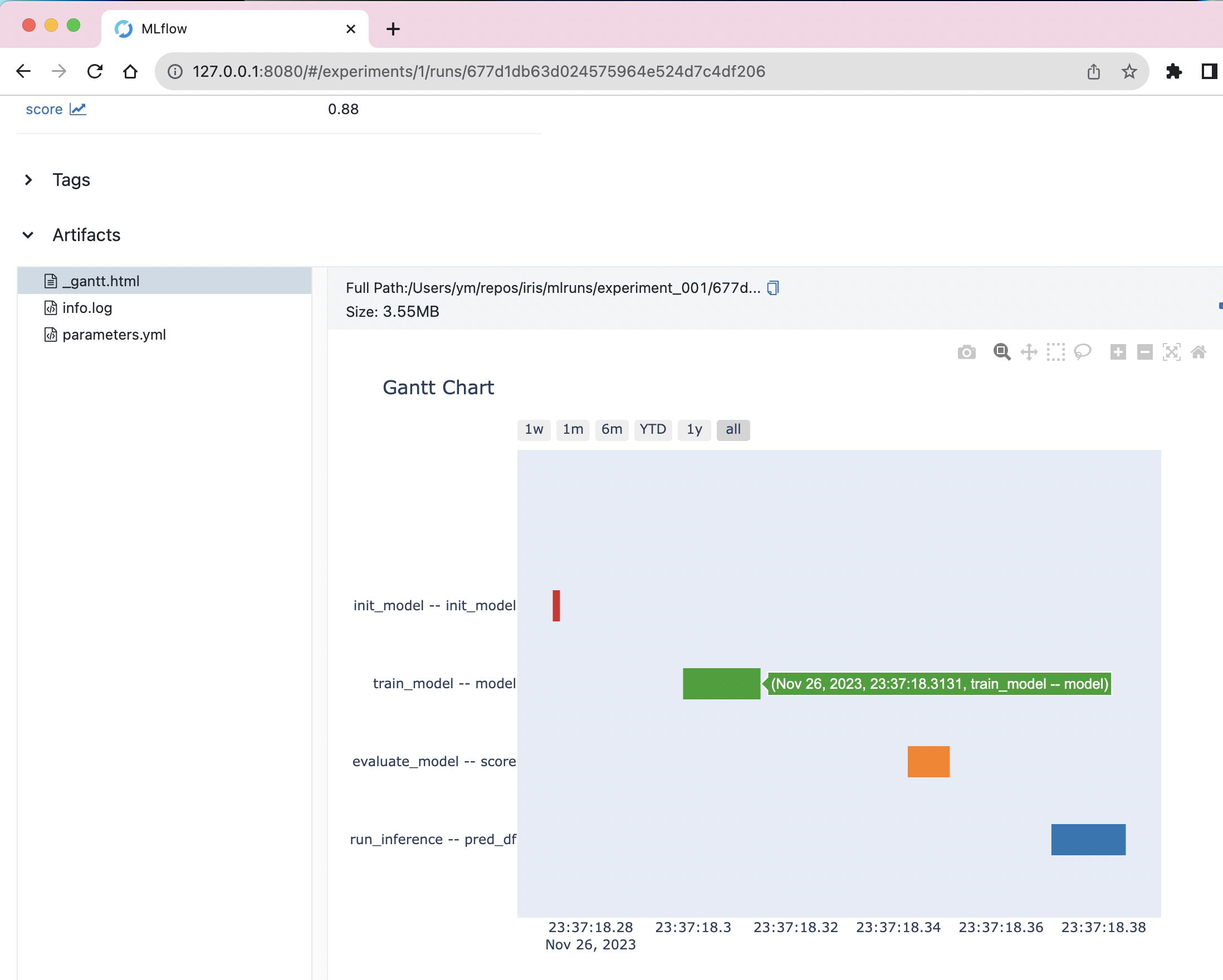 Gantt chart for execution time, generated using Plotly, shown in MLflow's UI
Gantt chart for execution time, generated using Plotly, shown in MLflow's UI
Both PipelineX's MLflow-on-Kedro and kedro-mlflow provide integration of MLflow to Kedro. Here are the comparisons.
-
Features supported by both PipelineX and kedro-mlflow
- Kedro DataSets and Hooks to log (save/upload) artifacts, parameters, and metrics to MLflow.
- Truncate MLflow parameter values to 250 characters to avoid error due to MLflow parameter length limit.
- Dict values can be flattened using dot (".") as the separator to log each value inside the dict separately.
-
Features supported by only PipelineX
- [Time logging] Option to log execution time for each task (Kedro node) as MLflow metrics
- [Gantt logging] Option to log Gantt chart HTML file that visualizes execution time using Plotly as an MLflow artifact (inspired by Apache Airflow)
- [Automatic backend Kedro DataSets for common artifacts] Option to specify a common file extension ({"json", "csv", "xls", "parquet", "png", "jpg", "jpeg", "img", "pkl", "txt", "yml", "yaml"}) so the Kedro DataSet object will be created behind the scene instead of manually specifying a Kedro DataSet including filepath in the catalog (inspired by Kedro Wings).
- [Automatic logging for MLflow parameters and metrics] Option to log each dataset not listed in the catalog as MLflow parameter or metric, instead of manually specifying a Kedro DataSet in the catalog.
- If the data type is either {float, int}, the value will be saved/loaded as an MLflow metric.
- If the data type is either {str, list, tuple, set}, the value will be saved/load as an MLflow parameter.
- If the data type is dict, the value will be flattened with dot (".") as the separator and then saved/loaded as either an MLflow metric or parameter based on each data type as explained above.
- For example,
"data_loading_config": {"train": {"batch_size": 32}}will be logged as MLflow metric of"data_loading_config.train.batch_size": 32
- [Flexible config per DataSet] For each Kedro DataSet, it is possible to configure differently. For example, a dict value can be logged as an MLflow parameter (string) as is while another one can be logged as an MLflow metric after being flattened.
- [Direct artifact logging] Option to specify the paths of any data to log as MLflow artifacts after Kedro pipeline runs without using a Kedro DataSet, which is useful if you want to save local files (e.g. info/warning/error log files, intermediate model weights saved by Machine Learning packages such as PyTorch and TensorFlow, etc.)
- [Environment Variable logging] Option to log Environment Variables
- [Downloading] Option to download MLflow artifacts, params, metrics from an existing MLflow experiment run using the Kedro DataSet
- [Up to date] Support for Kedro 0.17.x (released in Dec 2020) or later
-
Features provided by only kedro-mlflow
- A wrapper for MLflow's
log_model - Configure MLflow logging in a YAML file
- Option to use MLflow tag or raise error if MLflow parameter values exceed 250 characters
- A wrapper for MLflow's
Kedro-Extras provides Kedro DataSets and decorators not available in kedro.extras.
Contributors who are willing to help preparing the test code and send pull request to Kedro following Kedro's CONTRIBUTING.md are welcomed.
pipelinex.extras.datasets provides the following Kedro Datasets (data interface sets) mainly for Computer Vision applications using PyTorch/torchvision, OpenCV, and Scikit-image.
-
- loads/saves multiple numpy arrays (RGB, BGR, or monochrome image) from/to a folder in local storage using
pillowpackage, working likekedro.extras.datasets.pillow.ImageDataSetandkedro.io.PartitionedDataSetwith conversion between numpy arrays and Pillow images. - an example project is at pipelinex_image_processing
- loads/saves multiple numpy arrays (RGB, BGR, or monochrome image) from/to a folder in local storage using
-
- modified version of kedro.extras.APIDataSet with more flexible options including downloading multiple contents (such as images and json) by HTTP requests to multiple URLs using
requestspackage - an example project is at pipelinex_image_processing
- modified version of kedro.extras.APIDataSet with more flexible options including downloading multiple contents (such as images and json) by HTTP requests to multiple URLs using
-
- downloads multiple contents (such as images and json) by asynchronous HTTP requests to multiple URLs using
httpxpackage - an example project is at pipelinex_image_processing
- downloads multiple contents (such as images and json) by asynchronous HTTP requests to multiple URLs using
-
pipelinex.IterableImagesDataSet
- wrapper of
torchvision.datasets.ImageFolderthat loads images in a folder as an iterable data loader to use with PyTorch.
- wrapper of
-
pipelinex.PandasProfilingDataSet
- generates a pandas dataframe summary report using pandas-profiling
-
more data interface sets for pandas dataframe summarization/visualization provided by PipelineX
pipelinex.extras.decorators provides Python decorators for benchmarking.
-
- logs the duration time of a function (difference of timestamp before and after running the function).
- Slightly modified version of Kedro's log_time
-
- logs the peak memory usage during running the function.
memory_profilerneeds to be installed.- Slightly modified version of Kedro's mem_profile
-
- logs the difference of NVIDIA GPU usage before and after running the function.
pynvmlorpy3nvmlneeds to be installed.
from pipelinex import log_time
from pipelinex import mem_profile # Need to install memory_profiler for memory profiling
from pipelinex import nvml_profile # Need to install pynvml for NVIDIA GPU profiling
from time import sleep
import logging
logging.basicConfig(level=logging.INFO)
@nvml_profile
@mem_profile
@log_time
def foo_func(i=1):
sleep(0.5) # Needed to avoid the bug reported at https://github.com/pythonprofilers/memory_profiler/issues/216
return "a" * i
output = foo_func(100_000_000)INFO:pipelinex.decorators.decorators:Running 'foo_func' took 549ms [0.549s]
INFO:pipelinex.decorators.memory_profiler:Running 'foo_func' consumed 579.02MiB memory at peak time
INFO:pipelinex.decorators.nvml_profiler:Ran: 'foo_func', NVML returned: {'_Driver_Version': '418.67', '_NVML_Version': '10.418.67', 'Device_Count': 1, 'Devices': [{'_Name': 'Tesla P100-PCIE-16GB', 'Total_Memory': 17071734784, 'Free_Memory': 17071669248, 'Used_Memory': 65536, 'GPU_Utilization_Rate': 0, 'Memory_Utilization_Rate': 0}]}, Used memory diff: [0]
To develop a simple neural network, it is convenient to use Sequential API
(e.g. torch.nn.Sequential, tf.keras.Sequential).
- Hardcoded:
from torch.nn import Sequential, Conv2d, ReLU
model = Sequential(
Conv2d(in_channels=3, out_channels=16, kernel_size=[3, 3]),
ReLU(),
)
print("### model object by hard-coding ###")
print(model)### model object by hard-coding ###
Sequential(
(0): Conv2d(3, 16, kernel_size=[3, 3], stride=(1, 1))
(1): ReLU()
)
- Using import-less Python object feature:
from pipelinex import HatchDict
import yaml
from pprint import pprint # pretty-print for clearer look
# Read parameters dict from a YAML file in actual use
params_yaml="""
model:
=: torch.nn.Sequential
_:
- {=: torch.nn.Conv2d, in_channels: 3, out_channels: 16, kernel_size: [3, 3]}
- {=: torch.nn.ReLU, _: }
"""
parameters = yaml.safe_load(params_yaml)
model_dict = parameters.get("model")
print("### Before ###")
pprint(model_dict)
model = HatchDict(parameters).get("model")
print("\n### After ###")
print(model)### Before ###
{'=': 'torch.nn.Sequential',
'_': [{'=': 'torch.nn.Conv2d',
'in_channels': 3,
'kernel_size': [3, 3],
'out_channels': 16},
{'=': 'torch.nn.ReLU', '_': None}]}
### After ###
Sequential(
(0): Conv2d(3, 16, kernel_size=[3, 3], stride=(1, 1))
(1): ReLU()
)
In addition to Sequential, TensorFLow/Keras provides modules to merge branches such as
tf.keras.layers.Concatenate, but PyTorch provides only functional interface such as torch.cat.
PipelineX provides modules to merge branches such as ModuleConcat, ModuleSum, and ModuleAvg.
- Hardcoded:
from torch.nn import Sequential, Conv2d, AvgPool2d, ReLU
from pipelinex import ModuleConcat
model = Sequential(
ModuleConcat(
Conv2d(in_channels=3, out_channels=16, kernel_size=[3, 3], stride=[2, 2], padding=[1, 1]),
AvgPool2d(kernel_size=[3, 3], stride=[2, 2], padding=[1, 1]),
),
ReLU(),
)
print("### model object by hard-coding ###")
print(model)### model object by hard-coding ###
Sequential(
(0): ModuleConcat(
(0): Conv2d(3, 16, kernel_size=[3, 3], stride=[2, 2], padding=[1, 1])
(1): AvgPool2d(kernel_size=[3, 3], stride=[2, 2], padding=[1, 1])
)
(1): ReLU()
)
- Using import-less Python object feature:
from pipelinex import HatchDict
import yaml
from pprint import pprint # pretty-print for clearer look
# Read parameters dict from a YAML file in actual use
params_yaml="""
model:
=: torch.nn.Sequential
_:
- =: pipelinex.ModuleConcat
_:
- {=: torch.nn.Conv2d, in_channels: 3, out_channels: 16, kernel_size: [3, 3], stride: [2, 2], padding: [1, 1]}
- {=: torch.nn.AvgPool2d, kernel_size: [3, 3], stride: [2, 2], padding: [1, 1]}
- {=: torch.nn.ReLU, _: }
"""
parameters = yaml.safe_load(params_yaml)
model_dict = parameters.get("model")
print("### Before ###")
pprint(model_dict)
model = HatchDict(parameters).get("model")
print("\n### After ###")
print(model)### Before ###
{'=': 'torch.nn.Sequential',
'_': [{'=': 'pipelinex.ModuleConcat',
'_': [{'=': 'torch.nn.Conv2d',
'in_channels': 3,
'kernel_size': [3, 3],
'out_channels': 16,
'padding': [1, 1],
'stride': [2, 2]},
{'=': 'torch.nn.AvgPool2d',
'kernel_size': [3, 3],
'padding': [1, 1],
'stride': [2, 2]}]},
{'=': 'torch.nn.ReLU', '_': None}]}
### After ###
Sequential(
(0): ModuleConcat(
(0): Conv2d(3, 16, kernel_size=[3, 3], stride=[2, 2], padding=[1, 1])
(1): AvgPool2d(kernel_size=[3, 3], stride=[2, 2], padding=[1, 1])
)
(1): ReLU()
)
Wrappers of PyTorch Ignite provides most of features available in Ignite, including integration with MLflow, in an easy declarative way.
In addition, the following optional features are available in PipelineX.
- Use only partial samples in dataset (Useful for quick preliminary check before using the whole dataset)
- Time limit for training (Useful for code-only (Kernel-only) Kaggle competitions with time limit)
Here are the arguments for NetworkTrain:
loss_fn (callable): Loss function used to train.
Accepts an instance of loss functions at https://pytorch.org/docs/stable/nn.html#loss-functions
epochs (int, optional): Max epochs to train
seed (int, optional): Random seed for training.
optimizer (torch.optim, optional): Optimizer used to train.
Accepts optimizers at https://pytorch.org/docs/stable/optim.html
optimizer_params (dict, optional): Parameters for optimizer.
train_data_loader_params (dict, optional): Parameters for data loader for training.
Accepts args at https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader
val_data_loader_params (dict, optional): Parameters for data loader for validation.
Accepts args at https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader
evaluation_metrics (dict, optional): Metrics to compute for evaluation.
Accepts dict of metrics at https://pytorch.org/ignite/metrics.html
evaluate_train_data (str, optional): When to compute evaluation_metrics using training dataset.
Accepts events at https://pytorch.org/ignite/engine.html#ignite.engine.Events
evaluate_val_data (str, optional): When to compute evaluation_metrics using validation dataset.
Accepts events at https://pytorch.org/ignite/engine.html#ignite.engine.Events
progress_update (bool, optional): Whether to show progress bar using tqdm package
scheduler (ignite.contrib.handle.param_scheduler.ParamScheduler, optional): Param scheduler.
Accepts a ParamScheduler at
https://pytorch.org/ignite/contrib/handlers.html#module-ignite.contrib.handlers.param_scheduler
scheduler_params (dict, optional): Parameters for scheduler
model_checkpoint (ignite.handlers.ModelCheckpoint, optional): Model Checkpoint.
Accepts a ModelCheckpoint at https://pytorch.org/ignite/handlers.html#ignite.handlers.ModelCheckpoint
model_checkpoint_params (dict, optional): Parameters for ModelCheckpoint at
https://pytorch.org/ignite/handlers.html#ignite.handlers.ModelCheckpoint
early_stopping_params (dict, optional): Parameters for EarlyStopping at
https://pytorch.org/ignite/handlers.html#ignite.handlers.EarlyStopping
time_limit (int, optioinal): Time limit for training in seconds.
train_dataset_size_limit (int, optional): If specified, only the subset of training dataset is used.
Useful for quick preliminary check before using the whole dataset.
val_dataset_size_limit (int, optional): If specified, only the subset of validation dataset is used.
useful for qucik preliminary check before using the whole dataset.
cudnn_deterministic (bool, optional): Value for torch.backends.cudnn.deterministic.
See https://pytorch.org/docs/stable/notes/randomness.html for details.
cudnn_benchmark (bool, optional): Value for torch.backends.cudnn.benchmark.
See https://pytorch.org/docs/stable/notes/randomness.html for details.
mlflow_logging (bool, optional): If True and MLflow is installed, MLflow logging is enabled.
Please see the example code using MNIST dataset prepared based on the original code.
It is also possible to use:
- FlexibleModelCheckpoint handler which enables to use timestamp in the model checkpoint file name to clarify which one is the latest.
- CohenKappaScore metric which can compute Quadratic Weighted Kappa Metric used in some Kaggle competitions. See sklearn.metrics.cohen_kappa_score for details.
It is planned to port some code used with PyTorch Ignite to PyTorch Ignite repository once test and example codes are prepared.
A challenge of image processing is that the parameters and algorithms that work with an image often do not work with another image. You will want to output intermediate images from each image processing pipeline step for visual check during development, but you will not want to output all the intermediate images to save time and disk space in production.
Wrappers of OpenCV and ImagesLocalDataSet are the solution. You can concentrate on developping your image processing pipeline for an image (3-D or 2-D numpy array), and it will run for all the images in a folder.
If you are devepping an image processing pipeline consisting of 5 steps and you have 10 images, for example, you can check 10 generated images in each of 5 folders, 50 images in total, during development.
When I was working on a Deep Learning project, it was very time-consuming to develop the pipeline for experimentation. I wanted 2 features.
First one was an option to resume the pipeline using the intermediate data files instead of running the whole pipeline. This was important for rapid Machine/Deep Learning experimentation.
Second one was modularity, which means keeping the 3 components, task processing, file/database access, and DAG definition, independent. This was important for efficient software engineering.
After this project, I explored for a long-term solution. I researched about 3 Python packages for pipeline development, Airflow, Luigi, and Kedro, but none of these could be a solution.
Luigi provided resuming feature, but did not offer modularity. Kedro offered modularity, but did not provide resuming feature.
After this research, I decided to develop my own package that works on top of Kedro. Besides, I added syntactic sugars including Sequential API similar to Keras and PyTorch to define DAG. Furthermore, I added integration with MLflow, PyTorch, Ignite, pandas, OpenCV, etc. while working on more Machine/Deep Learning projects.
After I confirmed my package worked well with the Kaggle competition, I released it as PipelineX.
Please see CONTRIBUTING.md for details.