I'm Mustafa Shoukat, a data scientist. I'm in the world of AI and exploring various concepts and techniques to enhance my skills. In this notebook, I'll unlock the potential of your models with precision and efficiency.
"Community empowers growth through shared knowledge and mutual support."
About Notebook: 🧠 Fine-Tuning and PEFT with QLoRA on LLaMA 3
This notebook delves into the advanced techniques of fine-tuning and Parameter-Efficient Fine-Tuning (PEFT) using QLoRA on the LLaMA 3 model. Designed for data science enthusiasts and professionals, it offers hands-on experience and practical insights to enhance model performance with efficient use of computational resources. Join the journey to master these cutting-edge techniques and elevate your machine learning projects.
| Name | GitHub | Kaggle | ||
|---|---|---|---|---|
| Mustafa Shoukat | mustafashoukat.ai@gmail.com |
|
|
|
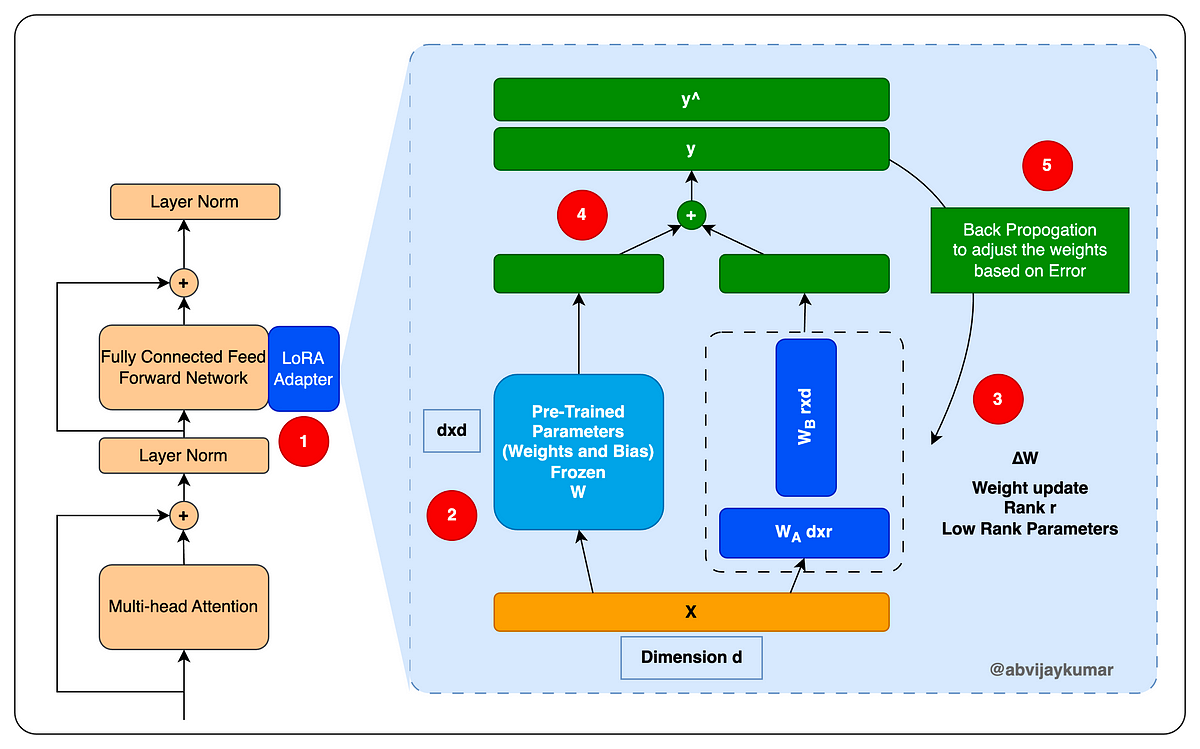
- Uses: A pre-trained model (weights and architecture) trained on a large dataset (source task) for a new task (target task).
- Key Point: Freezes most of the pre-trained model's parameters, only training a small subset (usually the final layers) on the new data.
- Benefit: Faster training, leverages learned features, good for tasks with limited data.
- Also leverages: A pre-trained model for a new task.
- Key Point: Trains all the parameters of the pre-trained model on the new data.
- Benefit: Allows for more significant adaptation to the new task, potentially higher performance compared to transfer learning.
- Drawback: Can be computationally expensive, potentially prone to overfitting with small datasets.
- A specific strategy: Within fine-tuning.
- Key Point: Focuses on training only a subset of the pre-trained model's parameters, often identified through techniques like saliency maps or gradient analysis.
- Benefit: Reduces computational cost compared to full fine-tuning while achieving comparable performance in some cases.

Adapters are a special type of submodule that can be added to pre-trained language models to modify their hidden representation during fine-tuning. By inserting adapters after the multi-head attention and feed-forward layers in the transformer architecture, we can update only the parameters in the adapters during fine-tuning while keeping the rest of the model parameters frozen.
Adopting adapters can be a straightforward process. All that is required is to add adapters into each transformer layer and place a classifier layer on top of the pre-trained model. By updating the parameters of the adapters and the classifier head, we can improve the performance of the pre-trained model on a particular task without updating the entire model. This approach can save time and computational resources while still producing impressive results.
Low-rank adaptation (LoRA) of large language models is another approach in the area of fine-tuning models for specific tasks or domains. Similar to the adapters, LoRA is also a small trainable submodule that can be inserted into the transformer architecture. It involves freezing the pre-trained model weights and injecting trainable rank decomposition matrices into each layer of the transformer architecture, greatly diminishing the number of trainable parameters for downstream tasks. This method can minimize the number of trainable parameters by up to 10,000 times and the GPU memory necessity by 3 times while still performing on par or better than fine-tuning model quality on various tasks. LoRA also allows for more efficient task-switching, lowering the hardware barrier to entry, and has no additional inference latency compared to other methods.
ORPO is a new exciting fine-tuning technique that combines the traditional supervised fine-tuning and preference alignment stages into a single process. This reduces the computational resources and time required for training. Moreover, empirical results demonstrate that ORPO outperforms other alignment methods on various model sizes and benchmarks.
There are now many methods to align large language models (LLMs) with human preferences. Reinforcement learning with human feedback (RLHF) was one of the first and brought us ChatGPT, but RLHF is very costly. DPO (Differentiable Preference Optimization), IPO (Interactive Preference Optimization), and KTO (Knowledge Transfer Optimization) are notably cheaper than RLHF as they don’t need a reward model.
While DPO and IPO are cheaper, they still require to train two different models. One model for the supervised fine-tuning (SFT) step, i.e., training the model to answer instructions, and then the model to align with human preferences using the SFT model for initialization and as a reference.
Instruction tuning and preference alignment are essential techniques for adapting Large Language Models (LLMs) to specific tasks. Traditionally, this involves a multi-stage process: 1/ Supervised Fine-Tuning (SFT) on instructions to adapt the model to the target domain, followed by 2/ preference alignment methods like Reinforcement Learning with Human Feedback (RLHF) or Direct Preference Optimization (DPO) to increase the likelihood of generating preferred responses over rejected ones.
ORPO is yet another new method for LLM alignment but this one doesn’t even need the SFT model. With ORPO, the LLM jointly learns to answer instructions and human preferences. ORPO: Monolithic Preference Optimization without Reference Model
ORPO: Monolithic Preference Optimization without Reference Model