1. Structure of the REopt API
The REopt® API is built primarily in Python, with the exception of the code used to call the optimization kernel, which is written in Julia. In the REopt_API version 3 and higher, the Julia JuMP model (and all of the supporting functions) are now housed in the publicly-registered Julia package, REopt.jl. The API is served using the Django framework, with a PostgreSQL database backend where input, output, and error data models are stored. Task management is achieved with Celery, which uses Redis as a message broker (a database for storing and retrieving Celery tasks). The figure below shows a how each of these pieces interact.
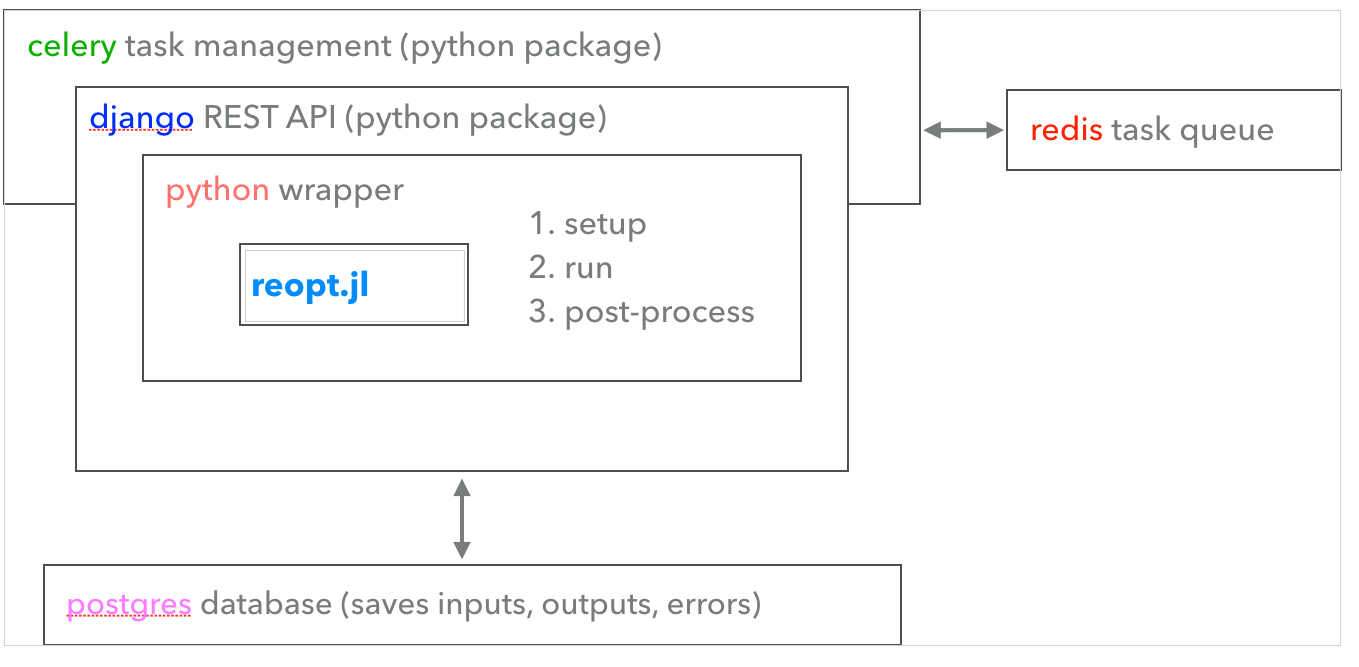
We typically update the API version when we make major changes to default values or breaking changes.
Please see the documentation at https://developer.nrel.gov/docs/energy-optimization/reopt/ for REopt API versions and their urls.
API v3 uses the REopt Julia Package as the optimization back-end, whereas v1 and v2 access an older version of this Julia code contained within the julia_src directory of the REopt_API repository. The v3 Python code is housed in the reoptjl directory of this repository and the v1/v2 Python code in the reo directory.
Base url: https://developer.nrel.gov/api/reopt/
API_KEY parameter must be added to url
Run a REopt optimization: /job?
Get the results of a REopt optimization: job/<run_uuid>/results?
Get descriptions of possible inputs: /help?
Get descriptions of possible inputs: /job/inputs?
Get descriptions of possible outputs: /job/outputs?
Get CHP defaults, which depend on other CHP inputs: /chp_defaults?
Get absorption chiller defaults, which depend on other absorption chiller inputs: /absorption_chiller?
Get grid emissions for a location: /emissions_profile?
Get EASIUR health emissions cost data for a location: /easiur_costs?
Get a simulated load profile: /simulated_load?
Get a summary of a user's optimization jobs: /<user_uuid>/summary?
Get a summary of a subset of a user's optimization jobs: /<user_uuid>/summary_by_chunk?
Unlink an optimization job from a user: /<user_uuid>/unlink/<run_uuid>?
Get outage start times centered or starting on peak load: /peak_load_outage_times?
Check if a URDB label is in a set of invalid labels: /invalid_urdb?
Get a summary of a yearly CHP unavailability profile: /schedule_stats?
Run the ERP: /erp?
Get the results of an ERP run: erp/<run_uuid>/results?
Get descriptions of possible ERP inputs: /erp/help?
Get descriptions of possible ERP inputs: /erp/inputs?
Get descriptions of possible ERP outputs: /erp/outputs?
We separate catagories of data involved in REopt API functionality into subclasses of Django Model, which each correspond to a table in the database. Some Models are for input values, some for outputs values, and some for warning/error messages. These Django Models are defined in the file models.py. After making any changes to models.py, to update the database accordingly, run in terminal:
python manage.py makemigrationsEach Model except APIMeta has a meta attribute, which is used to link instances of that class to an instance of APIMeta. This is necessary for linking all the data of a REopt run stored in the database. The meta field can be of different types depending on the relationship between models.
This class is used when there is only ever one instance of the class associated with each APIMeta, which goes for most classes. For example, this is how the WindInputs meta field is defined as follows:
meta = models.OneToOneField(
APIMeta,
on_delete=models.CASCADE,
related_name="WindInputs",
primary_key=True
)This class is used when there can be multiple instances of the class associated with each APIMeta, such as PVInputs, PVOutputs, and Message. For example, the PVOutputs meta field is defined as follows
meta = models.ForeignKey(
to=APIMeta,
on_delete=models.CASCADE,
related_name="PVOutputs",
unique=False
)When defining data fields inside a Model subclass, we take advantage of Django's built-in functionality to:
- validate field types
- validate field min/max values
- limit fields to certain values
- set defaults
- set whether fields are required
- provide
help_textfor each field
For example, the timeout_seconds field is constrained between 1 and 420 seconds with a default of 420:
timeout_seconds = models.IntegerField(
default=420,
validators=[
MinValueValidator(1),
MaxValueValidator(420)
],
help_text="The number of seconds allowed before the optimization times out."
)The following is an example of limiting a field value to a set of choices:
time_steps_per_hour = models.IntegerField(
default=TIME_STEP_CHOICES.ONE,
choices=TIME_STEP_CHOICES.choices,
help_text="The number of time steps per hour in the REopt model."
)where TIME_STEP_CHOICES is defined as:
class TIME_STEP_CHOICES(models.IntegerChoices):
ONE = 1
TWO = 2
FOUR = 4When fields are not required to be provided by the user, we set the blank parameter to True. When the field also has no default, to allow it to be stored in the database as NULL, we set the null parameter to True (except for CharField and TextField which should be saved as /'/' when empty).
The Django Model class has a clean method that by default is empty. We can override this method to perform custom validation or set defaults with dependencies.
We enforce input Model validation using the InputValidator class in reoptjl/validators.py. First, the InputValidator class has a clean_fields() method that calls Model.clean_fields() on all of the input data models. This checks data types, min/max values, choices, and sets basic defaults. InputValidator.clean() calls the optionally overridden Model.clean() on each input model. Then we have an additional method InputValidator.cross_clean(), which performs custom validation with inter-model dependencies. Finally, InputValidator.save() calls save() on all of the models to save the validated inputs in the database.
To access data from the database, use the get() method. For example, to get the APIMeta object associated with the run uuid run_uuid, do:
meta = APIMeta.objects.get(run_uuid=run_uuid)We often need to access the data of multiple Model subclasses. Rather than doing a get() call for each, it is more efficient to do this in one database call using the select_related() method as shown in the example below. Any Model with a OneToOneField linking it to APIMeta can be specified as an argument here using the related_name provided when defining the OneToOneField.
meta = APIMeta.objects.select_related(
'Settings',
'FinancialInputs',
'SiteInputs',
'ElectricLoadInputs',
).get(run_uuid=run_uuid)The class Job in reoptjl/api.py is an example of a Resource. It takes inputs and initiates a (v3) REopt optimization. In reopt_api/urls.py, we create API versions and register Resources to them by doing:
from tastypie.api import Api
from reoptjl.api import Job as Job3
from django.urls import include, re_path, path
v3_api = Api(api_name='v3')
v3_api.register(Job3())
urlpatterns = [..., re_path(r'', include(v3_api.urls)), ...]Job.Meta.resource_name = 'job' determines the url of the Job Resource. Sending a request to /v3/job will create a Job instance. The equivalent will be true of any other Resource registered to v3_api.
Another way of making a particular url (or url pattern) do something is using views, which are the functions in reoptjl/views.py. In the REopt API we generally use views for endpoints that get data. In order to connect the url /v3/job/<run_uuid>/results to the results view function, we do the following in reoptjl/urls.py:
from . import views
urlpatterns = [..., re_path(r'^job/(?P<run_uuid>[0-9a-f-]+)/results/?$', views.results), ...]And this in reopt_api/urls.py, which adds all the urlpatterns in reoptjl/urls.py:
urlpatterns = [..., path('v3/', include('reoptjl.urls')), ...]The Job Resource takes a POST request and runs REopt using these inputs. After handling of various metadata, an InputValidator is instantiated and used to validate the inputs using its methods described in the InputValidator section above. If inputs are valid, we create run_jump_model, which is a Celery Task defined in reoptjl/src/run_jump_model.py. The run_jump_model Task uses the provided run_uuid to get inputs from the database, POSTs this data to the Julia server to solve the optimization problem (see next section), handles erros, then processes and saves outputs to the database with a call to process_results. This Task is run asynchronously so that the API can continue to handle other requests without waiting for it to complete. Similarly, when an ERPJob Resource (defined in resilience_stats/api.py) is created, this asynchronously runs a Celery Task called run_erp_task.
Tasks like run_jump_model and run_erp_task, as well as some views in reoptjl/views.py, use the REopt Julia package to fulfill requests. The julia_src directory contains all the API's Julia code. A Julia HTTP server is defined in julia_src/http.jl and requests to its endpoints can be written in Python. For example, in run_jump_model:
julia_host = os.environ.get('JULIA_HOST', "julia")
response = requests.post("http://" + julia_host + ":8081/reopt/", json=data)And in the chp_defaults view:
julia_host = os.environ.get('JULIA_HOST', "julia")
http_jl_response = requests.get("http://" + julia_host + ":8081/chp_defaults/", json=inputs)In julia_src/http.jl, these HTTP endpoints are each linked to a function in that file. For example, the /reopt endpoint is made to execute the function reopt via:
HTTP.@register(ROUTER, "POST", "/reopt", reopt)
The functions in julia_src/http.jl can use functions from the REopt package (imported as reoptjl) and return data as an HTTP.Response.
Some inputs have defaults that are determined in the REopt Julia package rather than in the API before saving to the database (e.g. CHP defaults and emissions defaults that come from AVERT or EASIUR). This is done to avoid redundant code. In the reopt function in julia_src/http.jl, these defaults are collected and included in the returned data so that the database can be updated appropriately.
When developing the REopt API, one often needs the API to use a version of the REopt Julia package other than the latest version in the Julia Registry. To do this, navigate in a command terminal to julia_src, start Julia using the local environment (julia --project=.), go to package manager (]), and do one of the following:
- Registered REopt version:
add REopt@x.x.x - Branch of REopt.jl on GitHub:
add REopt#branch-name - Cloned REopt.jl in your local Julia dev folder:
dev REopt(also see Docker instructions specific to deving REopt)
The REopt API has multiple endpoints. The endpoint for optimizing an energy system is described here.
The steps behind an optimization are:
- A POST is made at
<host-url>/v2/job(for a description of all input parameters GET<host-url>/v2/help) -
reo/api.pyvalidates the POST, sets up the four celery tasks, and returns arun_uuid -
reo/scenario.pysets up all the inputs for the two optimization tasks - Two
reo/src/run_jump_model.pytasks are run in parallel, one for the business-as-usual costs, and one for the minimum life cycle cost system -
reo/process_results.pyprocesses the outputs from the two REopt tasks and saves them to database.
From the user's perspective, the primary changes are:
- Partial "flattening" of the inputs/outputs nested dictionaries (outer "Scenario" key has been removed and other models are no longer nested under the "Site" key).
- Input/output reorganization and name changes for improved clarity (see the REopt analysis wiki for a full mapping between old and new inputs and outputs).
For developers of the API, more significant changes have been made to improve the development experience.
In v1/v2, a single Django Model (and thus database table) contains both the inputs and outputs for each conceptual model (e.g. PV or ElectricTariff). In v3 the inputs and outputs are split into two separate Models (eg. ElectricTariffInputs and ElectricTariffOutputs). This division greatly simplifies creating the API response as well as saving and updating the data models.
In v1/v2, for each REopt optimization job, all Django Models are created and saved in the database. In v3, only the tables of Models relevant to the job a have rows inserted. For example, if a scenario is not modeling Wind then no WindInputs nor WindOutputs are instantiated and no "Wind" key would be present in the API response data.
In v1/v2, the nested_inputs_definitions is used as a source of data types, limits, defaults, and descriptions, which is used in ValidateNestedInput to validate user's POSTs. In v3, we take advantage of Django's built-in data validation to accomplish most of what ValidateNestedInput does. When defining fields of Django Models, we can use optional parameters to:
- validate field types
- validate field min/max values
- limit fields to certain values
- set defaults
- set whether fields are required
- provide
help_textfor each field In v3, after instantiating a Django model with a user's input values we call theModel.clean_fields()method on all of the input data models. This method checks data types, min/max values, choices, and sets defaults. Calling theModel.clean_fieldsmethod is done in the newInputValidator(in reoptjl/validators.py) for every input model.
The Django Model also has a clean method that by default is empty. In v3, we over-ride this method to perform custom validation as needed. Using the InputValidator class, we call the Model.clean() method on all of the input models (after calling the Model.clean_fields() method).
Finally, there are some cases for input validation that require comparing fields from two different Django Models. For example, the length of any time-series input value, such as ElectricLoadInputs.loads_kw, needs to align with the Settings.time_steps_per_hour. This type of cross-model validation is done after the clean_fields and clean methods, and is called cross_clean. The cross_clean method is part of the InputValidator and is called in reoptjl/api.py as the final step for validating the job inputs.
In v1/v2, each optimization job consists of four celery tasks (setup_scenario, one optimal and one baurun_jump_model, and process_results).
In v3, there is only one celery task per optimization job. This has been accomplished by running the BAU and optimal scenarios in parallel in the Julia code and combining the scenario set up and post process steps into a single celery task.
In v1/v2, the julia_src/ directory includes the code to build and optimize the JuMP model. In v3, this is housed in a publicly registered Julia pacakge. This means that the JuMP model (and all of the supporting functions) are now in a separate repository and can be used with just a few lines of Julia code without accessing the REopt API. For example:
using REopt, Cbc, JuMP
model = JuMP.Model(Cbc.Optimizer)
results = REopt.run_reopt(m, "path/to/scenario.json")In v3 of the API we use the REopt Julia package in a similar fashion (see julia_src/http.jl). Note that in v3 the Business as Usual and Optimal scenarios are run in parallel by the REopt package, and running the BAU scenario is optional (via Settings.run_bau input).
In creating the Julia Module (or "package") for REoptLite much of the inputs set up code and post-processing has shifted from the API to the Julia package. By porting the setup and post-processing code to the Julia package anyone can now use REoptLite in Julia alone, which makes it much easier to add inputs/outputs, create new constraints, and in general modify REoptLite as one sees fit.
For past and recent developers of the REopt Lite API, here is a pseudo-map of where some of API code responsibilities has been moved to in the Julia package:
- reo/src/techs.py -> broken out into individual files for each tech in the src/core/ directory, e.g. pv.jl, wind.jl, generator.jl
- reo/scenario.py -> src/core/scenario.jl
- reo/src/pvwatts.py + wind_resource.py + wind.py + sscapi.py -> src/core/prodfactor.jl
- reo/src/data_manager.py + julia_src/utils.jl -> src/core/reopt_inputs.jl
- reo/process_results.py -> src/results/ contains a main results.jl as well as results generating functions for each data structure (e.g. src/results/pv.jl)
- julia_src/reopt_model.jl -> src/core/reopt.jl + src/constraints/*
Also, here is a pseudo-map of where some of the reo/ code is now handled in the reoptjl/ app:
- reo/nested_inputs.py + nested_outputs.py + models.py -> reoptjl/models.py
- reo/process_results.py -> reoptjl/src/process_results.py (only saving results to database now since results are created in Julia)
- reo/api.py -> reoptjl/api.py
- reo/views.py -> reoptjl/views.py
- reo/src/run_jump_model.py -> reoptjl/src/run_jump_model.py
For more information on the Julia package please see the developer section in the Julia package documentation.
The primary change to the mathematical model in the new reoptjl endpoint is that all binary variables (and constraints) are added conditionally. For example, when modeling PV, Wind, and/or Storage without a tiered ElectricTariff no binary variables are necessary. However, adding a Generator or a tiered ElectricTariff does require binaries.
Also related to binary variables, the approach to modeling the net metering vs. wholesale export decision has been simplified:
In v1 the approach to the NEM/WHL binaries is as follows. First, binNMIL is used to choose between a combined tech capacity that is either above or below net_metering_limit_kw. There are two copies of each tech model made for both the above or below net_metering_limit_kw. If the combined tech capacity is below net_metering_limit_kw then the techs can export into the NEM bin (i.e. take advantage of net metering). If the combined tech capacity is greater than net_metering_limit_kw then the techs can export into the WHL bin. In either case the techs can export into the EXC bin. Second, this approach also requires a tech-to-techclass map and binaries for constraining one tech from each tech class - where the tech class contains the tech that can net meter and the one that can wholesale.
In the new approach of the new reoptjl endpoint there there is no need for the tech-to-techclass map and associated binaries, as well as the duplicate tech models for above and below net_metering_limit_kw. Instead, indicator constraints are used (as needed) for binNEM and binWHL variables, whose sum is constrained to 1 (i.e. the model can choose only NEM or WHL, not both). binNEM is used in two pairs of indicator constraints: one for the net_metering_limit_kw vs. interconnection_limit_kw choice and another set for the NEM benefit vs. zero NEM benefit. The binWHL is also used in one set of indicator constraints for the WHL benefit vs. zero WHL benefit. The EXC bin is only available if NEM is chosen.
See https://github.com/NREL/REoptLite/blob/d083354de1ff5d572a8165343bfea11054e556fc/src/constraints/electric_utility_constraints.jl for details.