Using nothing but pure python and pytorch, ToMe for SD speeds up diffusion by merging redundant tokens.

This is the official implementation of ToMe for SD from our short paper:
Token Merging for Fast Stable Diffusion
Daniel Bolya, Judy Hoffman
GitHub | arXiv | BibTeX
ToMe for SD is an extension of the original ToMe:
Token Merging: Your ViT but Faster
Daniel Bolya,
Cheng-Yang Fu,
Xiaoliang Dai,
Peizhao Zhang,
Christoph Feichtenhofer,
Judy Hoffman
ICLR '23 Oral (Top 5%) | GitHub | arXiv | Blog | BibTeX
Note: this extension of ToMe is not affiliated in any way with Meta.
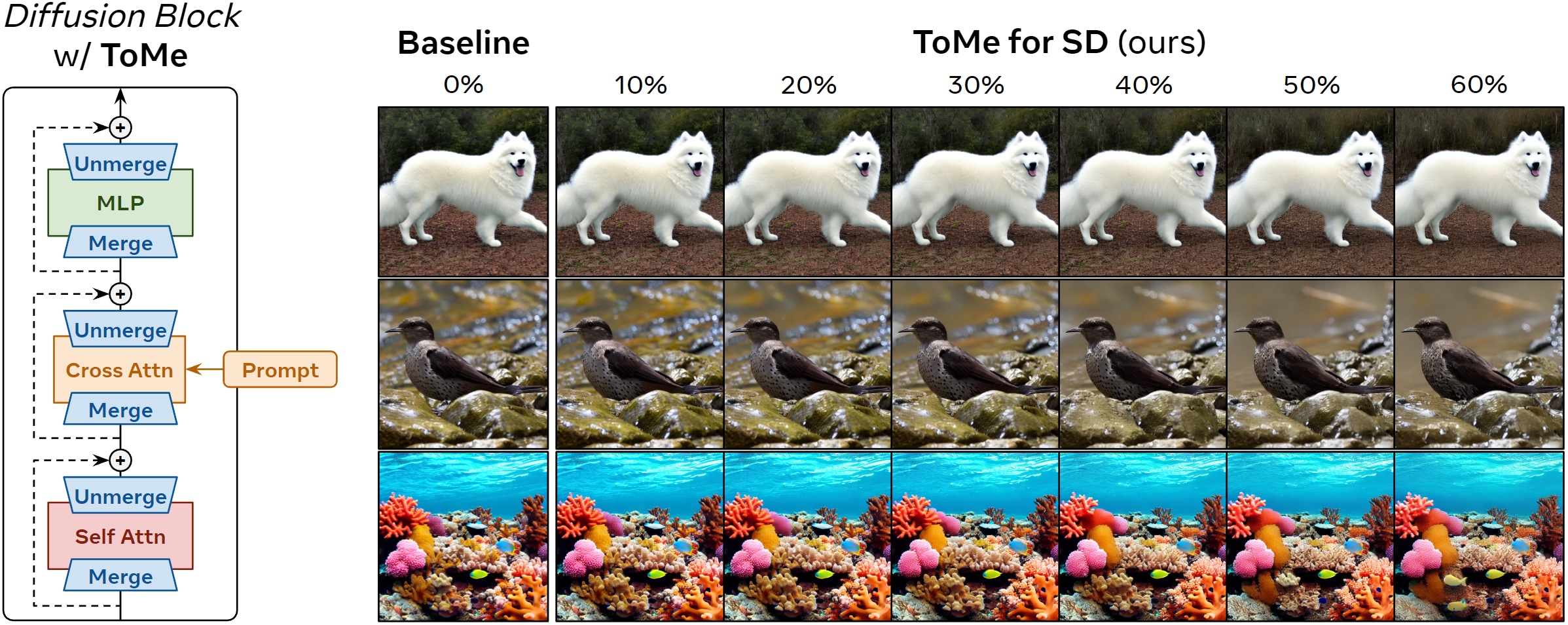
Token Merging (ToMe) speeds up transformers by merging redundant tokens, which means the transformer has to do less work. We apply this to the underlying transformer blocks in Stable Diffusion in a clever way that minimizes quality loss while keeping most of the speed-up and memory benefits. ToMe for SD doesn't require training and should work out of the box for any Stable Diffusion model.
Note: this is a lossy process, so the image will change, ideally not by much. Here are results with FID scores vs. time and memory usage (lower is better) when using Stable Diffusion v1.5 to generate 512x512 images of ImageNet-1k classes on a 4090 GPU with 50 PLMS steps using fp16:
| Method | r% | FID ↓ | Time (s/im) ↓ | Memory (GB/im) ↓ |
|---|---|---|---|---|
| Baseline (Original Model) | 0 | 33.12 | 3.09 | 3.41 |
| w/ ToMe for SD | 10 | 32.86 | 2.56 (1.21x faster) | 2.99 (1.14x less) |
| 20 | 32.86 | 2.29 (1.35x faster) | 2.17 (1.57x less) | |
| 30 | 32.80 | 2.06 (1.50x faster) | 1.71 (1.99x less) | |
| 40 | 32.87 | 1.85 (1.67x faster) | 1.26 (2.71x less) | |
| 50 | 33.02 | 1.65 (1.87x faster) | 0.89 (3.83x less) | |
| 60 | 33.37 | 1.52 (2.03x faster) | 0.60 (5.68x less) |
Even with more than half of the tokens merged (60%!), ToMe for SD still produces images close to the originals, while being 2x faster and using ~5.7x less memory. Moreover, ToMe is not another efficient reimplementation of transformer modules. Instead, it actually reduces the total work necessary to generate an image, so it can function in conjunction with efficient implementations (see Usage).
- [2023.04.02] ToMe for SD is now available via pip as tomesd. Thanks @mkshing!
- [2023.03.31] ToMe for SD now supports Diffusers. Thanks @JunnYu and @ExponentialML!
- [2023.03.30] Initial release.
See the changelog for more details.
This repo includes code to patch an existing Stable Diffusion environment. Currently, we support the following implementations:
- Stable Diffusion v2
- Stable Diffusion v1
- Latent Diffusion
- Diffusers
- And potentially others
Note: This also supports most downstream UIs that use these repositories.
ToMe for SD requires pytorch >= 1.12.1 (for scatter_reduce), which you can get from here. Then after installing your choice of stable diffusion environment (supported environments), use the corresponding python environment to install ToMe for SD:
pip install tomesdIf you'd like to install from source to get the latest updates, clone the repository:
git clone https://github.com/dbolya/tomesd
cd tomesdThen set up the tomesd package with:
python setup.py build developThat's it! ToMe for SD is implemented in pure python, no CUDA compilation required. 🙂
Apply ToMe for SD to any Stable Diffusion model with
import tomesd
# Patch a Stable Diffusion model with ToMe for SD using a 50% merging ratio.
# Using the default options are recommended for the highest quality, tune ratio to suit your needs.
tomesd.apply_patch(model, ratio=0.5)
# However, if you want to tinker around with the settings, we expose several options.
# See docstring and paper for details. Note: you can patch the same model multiple times.
tomesd.apply_patch(model, ratio=0.9, sx=4, sy=4, max_downsample=2) # Extreme merging, expect diminishing returnsSee above for what speeds and memory savings you can expect with different ratios.
If you want to remove the patch later, simply use tomesd.remove_patch(model).
To apply ToMe to the txt2img script of SDv2 or SDv1 for instance, add the following to this line (SDv2) or this line (SDv1):
import tomesd
tomesd.apply_patch(model, ratio=0.5)That's it! More examples and demos coming soon (hopefully).
Note: You may not see the full speed-up for the first image generated (as pytorch sets up the graph). Since ToMe for SD uses random processes, you might need to set the seed every batch if you want consistent results.
ToMe can also be used to patch a 🤗 Diffusers Stable Diffusion pipeline:
import torch, tomesd
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16).to("cuda")
# Apply ToMe with a 50% merging ratio
tomesd.apply_patch(pipe, ratio=0.5) # Can also use pipe.unet in place of pipe here
image = pipe("a photo of an astronaut riding a horse on mars").images[0]
image.save("astronaut.png")You can remove the patch with tomesd.remove_patch(pipe).
Since ToMe only affects the forward function of the block, it should support most efficient transformer implementations out of the box. Just apply the patch as normal!
Note: when testing with xFormers, I observed the most speed-up with ToMe when using big images (i.e., 2048x2048 in the parrot example above). You can get even more speed-up with more aggressive merging configs, but quality obviously suffers. For the result above, I had each method img2img from the same 512x512 res image (i.e., I only applied ToMe during the second pass of "high res fix") and used the default config with 60% merging. Also, the memory benefits didn't stack with xFormers (efficient attention already takes care of memory concerns).
If you use ToMe for SD or this codebase in your work, please cite:
@article{bolya2023tomesd,
title={Token Merging for Fast Stable Diffusion},
author={Bolya, Daniel and Hoffman, Judy},
journal={arXiv},
year={2023}
}
If you use ToMe in general please cite the original work:
@inproceedings{bolya2023tome,
title={Token Merging: Your {ViT} but Faster},
author={Bolya, Daniel and Fu, Cheng-Yang and Dai, Xiaoliang and Zhang, Peizhao and Feichtenhofer, Christoph and Hoffman, Judy},
booktitle={International Conference on Learning Representations},
year={2023}
}