
ACG2vec全称为Anime Comics Games to vector。本repo会持续维护一些基于二次元相关的深度学习领域实践与探索。
在线预览(目前包含文本搜索、以图搜图、文本搜图、图片分数预测):https://cheerfun.dev/acg2vec/
开源仓库:https://github.com/OysterQAQ/ACG2vec
演示页前端开源仓库:https://github.com/wewewe131/acg2vec-frontend
以上两个仓库求个star QAQ🌟🌟🌟
目前模块包括:
-
model:深度神经网络模型模块,目前包括
-
acgvoc2vec:基于从维基百科动漫列表、萌娘百科、Bangumi、pixiv、AnimeList等来源获取清洗处理抽取的510w语句对微调的sentence-transformers模型,生成二次元相关文本的特征向量,用于各种下游任务(标签推荐,标签搜索,推荐系统等)
可以使用Huggingface在线体验:https://huggingface.co/OysterQAQ/ACGVoc2vec
-
dclip:使用danburoo2021数据集对clip(ViT-L/14)模型进行微调。
可以使用Huggingface在线体验:https://huggingface.co/OysterQAQ/DanbooruCLIP
-
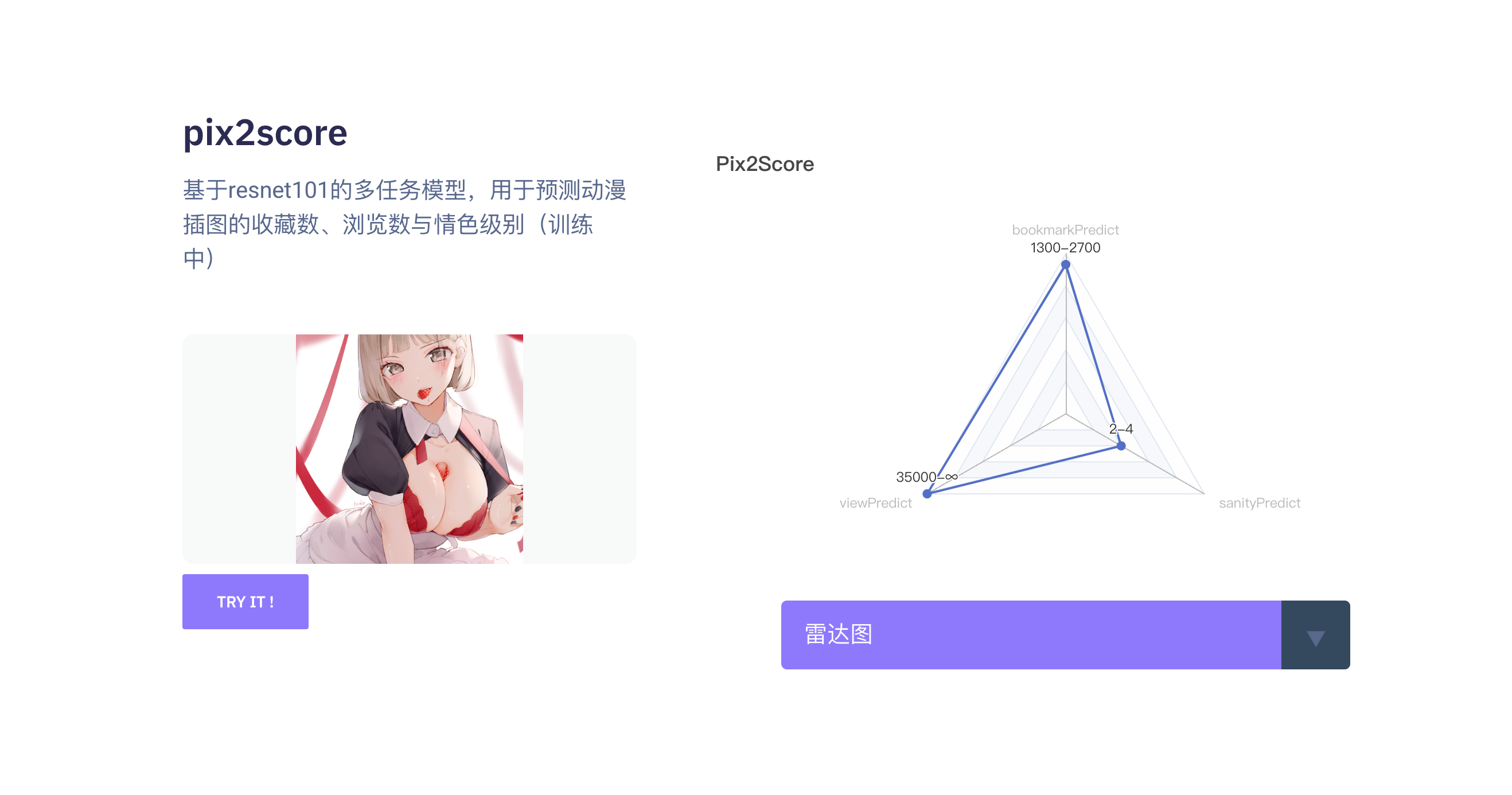
pix2score:基于resnet101的多任务模型,用于预测动漫插图的收藏数、浏览数与情色级别(训练中)
-
illust2vec:从DeepDanbooru模型去除预测头并对末尾层做均值池化的图片语义特征抽取模型
-
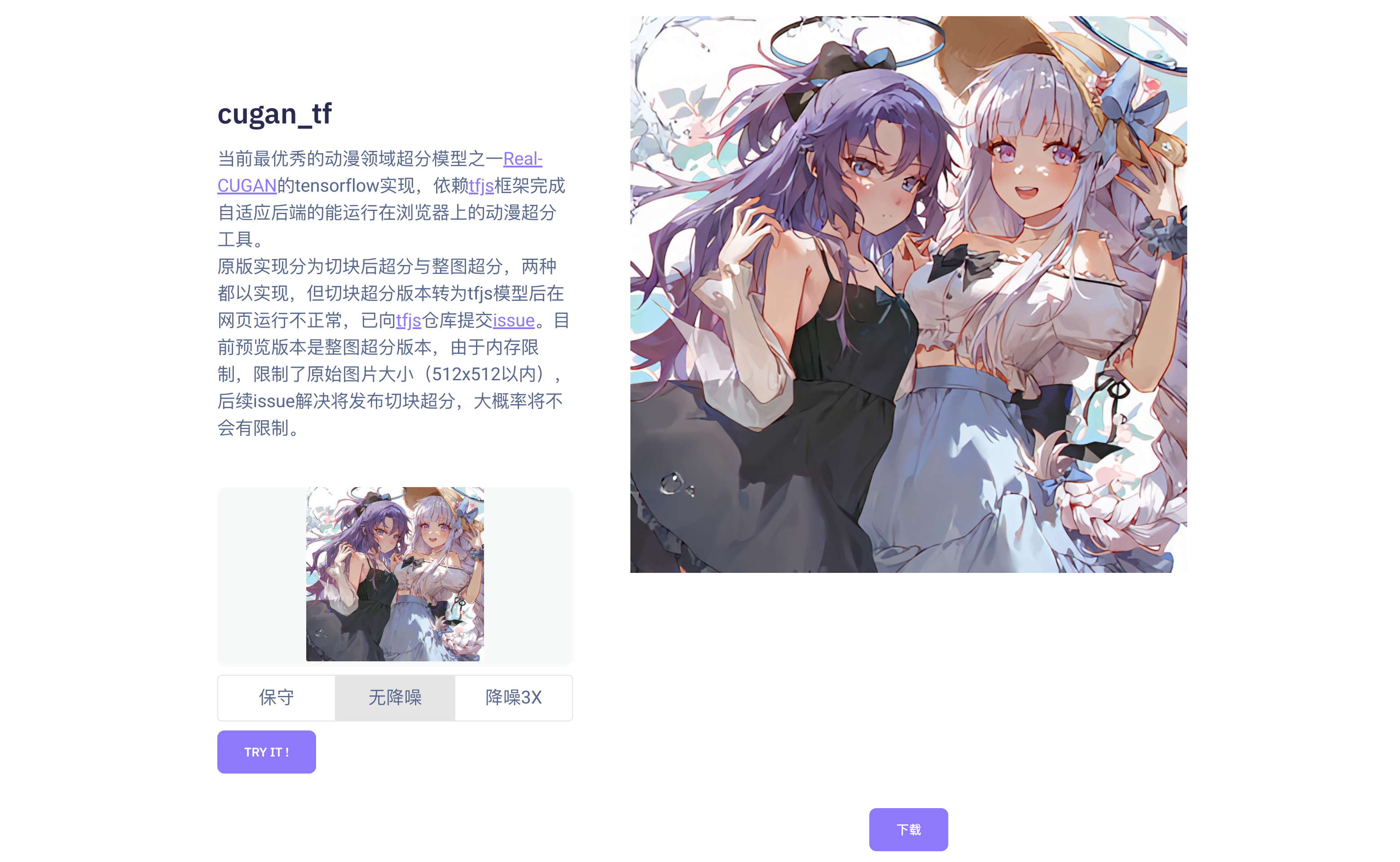
real-cugan_tf:当前最优秀的动漫领域超分模型之一Real-CUGAN的tensorflow实现,依赖tfjs框架完成自适应后端的能运行在浏览器上的动漫超分工具。
-
recSys4Pix:构建最小化现代推荐系统实践
-
-
webapp:对外提供web服务模块。目前包括开箱即用的二次元插画标签预测服务、以图搜图服务、插画特征抽取服务、文本特征抽取服务
-
docker:基于容器化的部署模块,包括了部署所需要的配置文件与资源文件(未开发完成)

结构概览为:DeepDanbooru的输入层至activation_96层作为特征抽取器(学习率设置为1e-5)+各个任务自定义resnet block与dense预测头(学习率设置为1e-2)
预测任务为pixiv插画的浏览数、收藏数、图片浏览级别(文本标签可以使用DeepDanbooru模型进行预测)。
DeepDanbooru模型是基于resnet的预测模型,用于预测动漫插画的标签信息,完整模型输出纬度为8000。DeepDanbooru能很好的预测Danbooru数据集所描述的多标签多分类问题,Danbooru数据集的标签分布更加的均衡,对图片的描述更加的准确,但是标签中没有对图片收藏数与浏览数的预测,因此其输出中并没有包含图片的质量信息(一般笔触细腻,作画精美的作品会得到更多的浏览与收藏)。
因此考虑将DeepDanbooru的前半部分拼接上自定义任务的模块,以预测收藏浏览作为代理任务的方式对DeepDanbooru的前半部分进行小学习率的微调(自定义任务的模块使用正常学习率),使其能够包含插图的质量信息。
当模型拟合,将模型的特征抽取器模块单独取出,拼接上平均pooling层,使其做到输入一张图片,输出1024维的向量,该向量作为图片的特征向量,用于下游任务。
之前也考虑过使用Danbooru数据集微调CLIP,但是loss一直不变,大概原因可能是这种对比学习的模型,其学习效率与batchsize相关性很大,batchsize越大,正样本所对应的负样本就越多。
结构为sentence-transformers,使用其distiluse-base-multilingual-cased-v2预训练权重,以5e-5的学习率在动漫相关语句对数据集下进行微调,损失函数为MultipleNegativesRankingLoss。
数据集主要包括:
-
Bangumi
- 动画日文名-动画中文名
- 动画日文名-简介
- 动画中文名-简介
- 动画中文名-标签
- 动画日文名-角色
- 动画中文名-角色
- 声优日文名-声优中文名
-
pixiv
- 标签日文名-标签中文名
-
AnimeList
- 动画日文名-动画英文名
-
维基百科
- 动画日文名-动画中文名
- 动画日文名-动画英文名
- 中英日详情页h2标题及其对应文本
- 简介多语言对照(中日英)
- 动画名-简介(中日英)
-
moegirl
- 动画中文名的简介-简介
-
动画中文名+小标题-对应内容
在进行爬取,清洗,处理后得到510w对文本对(还在持续增加),batchzise=80训练了20个epoch,使st的权重能够适应该问题空间,生成融合了领域知识的文本特征向量(体现为有关的文本距离更加接近,例如作品与登场人物,或者来自同一作品的登场人物)。
使用danburoo2021数据集对clip(ViT-L/14)模型进行微调。
0-3 epoch学习率为4e-6,权重衰减为1e-3
4-8 epoch学习率为1e-6,权重衰减为1e-3
标签预处理过程:
for i in range(length):
# 加载并且缩放图片
if not is_image(data_from_db.path[i]):
continue
try:
img = self.preprocess(
Image.open(data_from_db.path[i].replace("./", "/mnt/lvm/danbooru2021/danbooru2021/")))
except Exception as e:
#print(e)
continue
# 处理标签
tags = json.loads(data_from_db.tags[i])
# 优先选择人物和作品标签
category_group = {}
for tag in tags:
category_group.setdefault(tag["category"], []).append(tag)
# category_group=groupby(tags, key=lambda x: (x["category"]))
character_list = category_group[4] if 4 in category_group else []
# 作品需要过滤以bad开头的
work_list = list(filter(
lambda e:
e["name"] != "original"
, category_group[3])) if 3 in category_group else []
# work_list= category_group[5] if 5 in category_group else []
general_list = category_group[0] if 0 in category_group else []
caption = ""
caption_2 = None
for character in character_list:
if len(work_list) != 0:
# 去除括号内作品内容
character["name"] = re.sub(u"\\(.*?\\)", "", character["name"])
caption += character["name"].replace("_", " ")
caption += ","
caption = caption[:-1]
caption += " "
if len(work_list) != 0:
caption += "from "
for work in work_list:
caption += work["name"].replace("_", " ")
caption += " "
# 普通标签
if len(general_list) != 0:
caption += "with "
if len(general_list) > 20:
general_list_1 = general_list[:int(len(general_list) / 2)]
general_list_2 = general_list[int(len(general_list) / 2):]
caption_2 = caption
for general in general_list_1:
if general["name"].find("girl") == -1 and general["name"].find("boy") == -1 and len(
re.findall(is_contain, general["name"])) != 0:
caption_2 += general["name"].replace("_", " ")
caption_2 += ","
caption_2 = caption_2[:-1]
for general in general_list_2:
if general["name"].find("girl") == -1 and general["name"].find("boy") == -1 and len(
re.findall(is_contain, general["name"])) != 0:
caption += general["name"].replace("_", " ")
caption += ","
caption = caption[:-1]
else:
for general in general_list:
# 如果标签数据目大于20 则拆分成两个caption
if general["name"].find("girl") == -1 and general["name"].find("boy") == -1 and len(
re.findall(is_contain, general["name"])) != 0:
caption += general["name"].replace("_", " ")
caption += ","
caption = caption[:-1]
# 标签汇总成语句
# tokenize语句
# 返回
# 过长截断 不行的话用huggingface的
text_1 = clip.tokenize(texts=caption, truncate=True)
text_2= None
if caption_2 is not None:
text_2 = clip.tokenize(texts=caption_2, truncate=True)
# 处理逻辑
# print(img)
yield img, text_1[0]
if text_2 is not None:
yield img, text_2[0]在线体验:Https://cheerfun.org/acg2vec
github 主仓库地址( tensorflow 的 savemodel 格式可以在 release 中下载): https://github.com/OysterQAQ/ACG2vec(求star~)
基于resnet101对插画的浏览数、收藏数、情色级别的分类预测,以 1e-3 的学习率在动漫插画数据集下进行训练,输入尺寸为224x224,输出字典为
{
"bookmark_predict": {
"0": "0-10",
"1": "10-30",
"2": "30-50",
"3": "50-70",
"4": "70-100",
"5": "100-130",
"6": "130-170",
"7": "170-220",
"8": "220-300",
"9": "300-400",
"10": "400-550",
"11": "550-800",
"12": "800-1300",
"13": "1300-2700",
"14": "2700-∞"
},
"view_predict": {
"0": "0-500",
"1": "500-700",
"2": "700-1000",
"3": "1000-1500",
"4": "1500-2000",
"5": "2000-2500",
"6": "2500-3000",
"7": "3000-4000",
"8": "4000-5000",
"9": "5000-6500",
"10": "6500-8500",
"11": "8500-12000",
"12": "12000-19000",
"13": "19000-35000",
"14": "35000-∞"
},
"sanity_predict": {
"0": "0-2",
"1": "2-4",
"2": "4-6",
"3": "6-7",
"4": "7-∞"
}
}- 样本类别比例失衡 将元数据导入clickhouse查找n分位数来重新划分分段范围
- 数据集过大 无法一次读入内存,使用generator逐步读取
- 训练链路中io瓶颈 取数据与预处理数据造成瓶颈,将dataset导出成tfrecord二进制格式(实测可以跑满机械硬盘连续读写值,大概是250M/s)
- 开启混合精度导致loss nan 调整学习率
- 多任务梯度带偏 多任务存在简单任务与复杂任务,学习到后期,网络中的权重更新的梯度被困难任务loss和简单任务loss的加和共同所影响,为了维持简单任务的loss会导致复杂任务loss下降缓慢,后期通过手动调整loss权重得到改善,也实现了pcgrad但是没有什么改善
- 模型训练正常推理输出nan 排查出bn层moving_mean与moving_variance权重异常(这也是为什么训练正常推理异常的原因),重新使用对应层初始化器初始化异常权重后,继续训练(之前训练拟合进度慢的问题也和这个有关),出现nan权重大概是因为混合精度造成的,详见https://oysterqaq.com/archives/1463
- 部署的预处理一致性 在模型本体集成base64图片预处理层,无需顾虑预处理行为(resize)不同导致的推理结果差异
当前最优秀的动漫领域超分模型之一Real-CUGAN的tensorflow实现,依赖tfjs框架完成自适应后端的能运行在浏览器上的动漫超分工具。
原版实现分为切块后超分与整图超分,两种都以实现,但切块超分版本转为tfjs模型后在网页运行不正常,已向tfjs仓库提交issue。目前预览版本是整图超分版本,由于内存限制,限制了原始图片大小(512x512以内),后续issue解决将发布切块超分,大概率将不会有限制。
-
图片处理默认维度顺序: tensorflow为nhwc,pytorch为nchw,卷积权重维度顺序也不相同
-
tensorflow转置卷积无法自定义padding: Conv2DTranspose层padding设为0,后续使用slice手动crop输出
-
**tf.pad无法接受负数:**使用 tf.slice作为替代
-
**多尺寸输入导致无法batch :**无解
-
**延迟设置输入尺寸运行时获取size:**这是tensorflow图模型的限制
-
python操作逻辑最好翻译为tensorflow 分支选择api
-
**TensorArray:**TensorArray是图模式中python list替代品, TensorArray在eager模式TensorArray.write(i, x)可以直接生效,而在graph模式时需要将引用赋值给自身
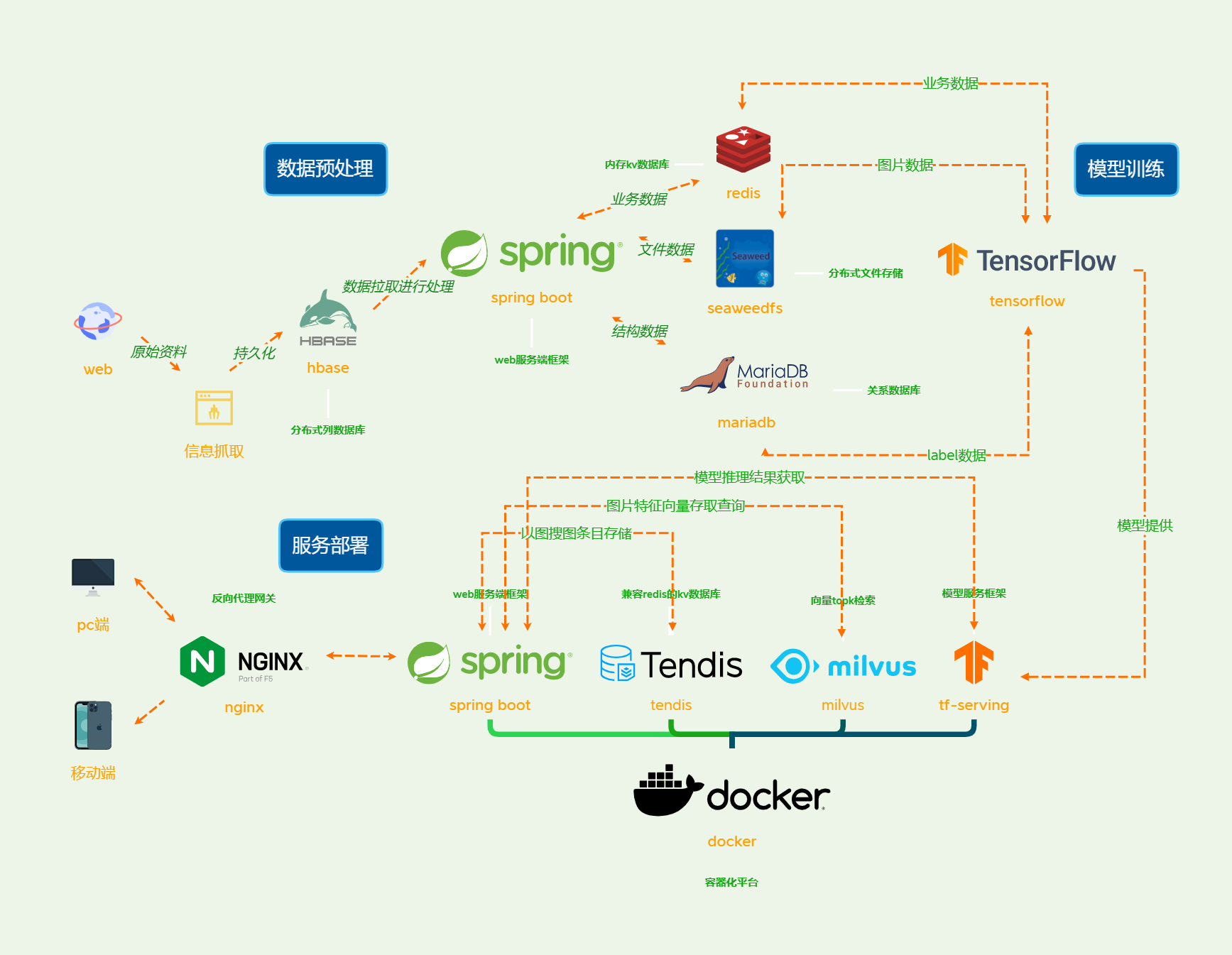
- Tensorflow 2.0作为模型训练引擎
- 基于Spring Boot的web服务
- 基于TF-serving的模型部署与前向推理
- 基于Milvus实现的topk近似向量检索
- 基于docker-compose的容器化跨平台部署
- 基于Tendis的元数据存储
克隆本repo并在docker文件夹中使用docker-compose进行部署
#拉取项目
git clone https://github.com/OysterQAQ/ACG2vec-docker.git
#下载release(1.0.0_for_tf_serving)中的模型包 解压到tf-serving/models
#使用docker-compose部署
docker-compose up -d基于restful api对外提供服务,以下是api文档(默认端口为8081,可在docker-compose.yaml中修改):
Path: /images/socresByPix2Score
Method: POST
接口描述:
Headers
| 参数名称 | 参数值 | 是否必须 | 示例 | 备注 |
|---|---|---|---|---|
| Content-Type | multipart/form-data | 是 | ||
| Body |
| 参数名称 | 参数类型 | 是否必须 | 示例 | 备注 |
|---|---|---|---|---|
| image | file | 是 |
| 名称 | 类型 | 是否必须 | 默认值 | 备注 | 其他信息 |
|---|---|---|---|---|---|
| message | string | 非必须 | |||
| data | object | 非必须 | |||
| ├─ bookmarkPredict | number [] | 非必须 | item 类型: number | ||
| ├─ | 非必须 | ||||
| ├─ viewPredict | number [] | 非必须 | item 类型: number | ||
| ├─ | 非必须 | ||||
| ├─ sanityPredict | number [] | 非必须 | item 类型: number | ||
| ├─ | 非必须 |
Path: /models/acgvoc2vec/feature
Method: POST
接口描述:
Headers
| 参数名称 | 参数值 | 是否必须 | 示例 | 备注 |
|---|---|---|---|---|
| Content-Type | application/x-www-form-urlencoded | 是 | ||
| Query |
| 参数名称 | 是否必须 | 示例 | 备注 |
|---|---|---|---|
| text | 是 |
| 名称 | 类型 | 是否必须 | 默认值 | 备注 | 其他信息 |
|---|---|---|---|---|---|
| message | string | 非必须 | |||
| data | number [] | 非必须 | item 类型: number | ||
| ├─ | 非必须 |
Path: /models/dclip_text/feature
Method: POST
接口描述:
Headers
| 参数名称 | 参数值 | 是否必须 | 示例 | 备注 |
|---|---|---|---|---|
| Content-Type | application/x-www-form-urlencoded | 是 | ||
| Query |
| 参数名称 | 是否必须 | 示例 | 备注 |
|---|---|---|---|
| text | 是 |
| 名称 | 类型 | 是否必须 | 默认值 | 备注 | 其他信息 |
|---|---|---|---|---|---|
| message | string | 非必须 | |||
| data | number [] | 非必须 | item 类型: number | ||
| ├─ | 非必须 |
Path: /images/labelsByDeepDanbooru
Method: POST
接口描述:
Headers
| 参数名称 | 参数值 | 是否必须 | 示例 | 备注 |
|---|---|---|---|---|
| Content-Type | multipart/form-data | 是 | ||
| Body |
| 参数名称 | 参数类型 | 是否必须 | 示例 | 备注 |
|---|---|---|---|---|
| image | file | 是 |
| 名称 | 类型 | 是否必须 | 默认值 | 备注 | 其他信息 |
|---|---|---|---|---|---|
| message | string | 非必须 | |||
| data | string [] | 非必须 | item 类型: string | ||
| ├─ | 非必须 |
Path: /models/illust2vec/feature
Method: POST
接口描述:
Headers
| 参数名称 | 参数值 | 是否必须 | 示例 | 备注 |
|---|---|---|---|---|
| Content-Type | multipart/form-data | 是 | ||
| Body |
| 参数名称 | 参数类型 | 是否必须 | 示例 | 备注 |
|---|---|---|---|---|
| image | file | 是 |
| 名称 | 类型 | 是否必须 | 默认值 | 备注 | 其他信息 |
|---|---|---|---|---|---|
| message | string | 非必须 | |||
| data | number [] | 非必须 | item 类型: number | ||
| ├─ | 非必须 |
本项目离不开以下开源项目
- DeepDanbooru
- sentence-transformers
- Milvus
- TensorFlow
- Keras
- Spring Boot
- SeaweedFS
- TF-serving
- Tendis
- Docker
