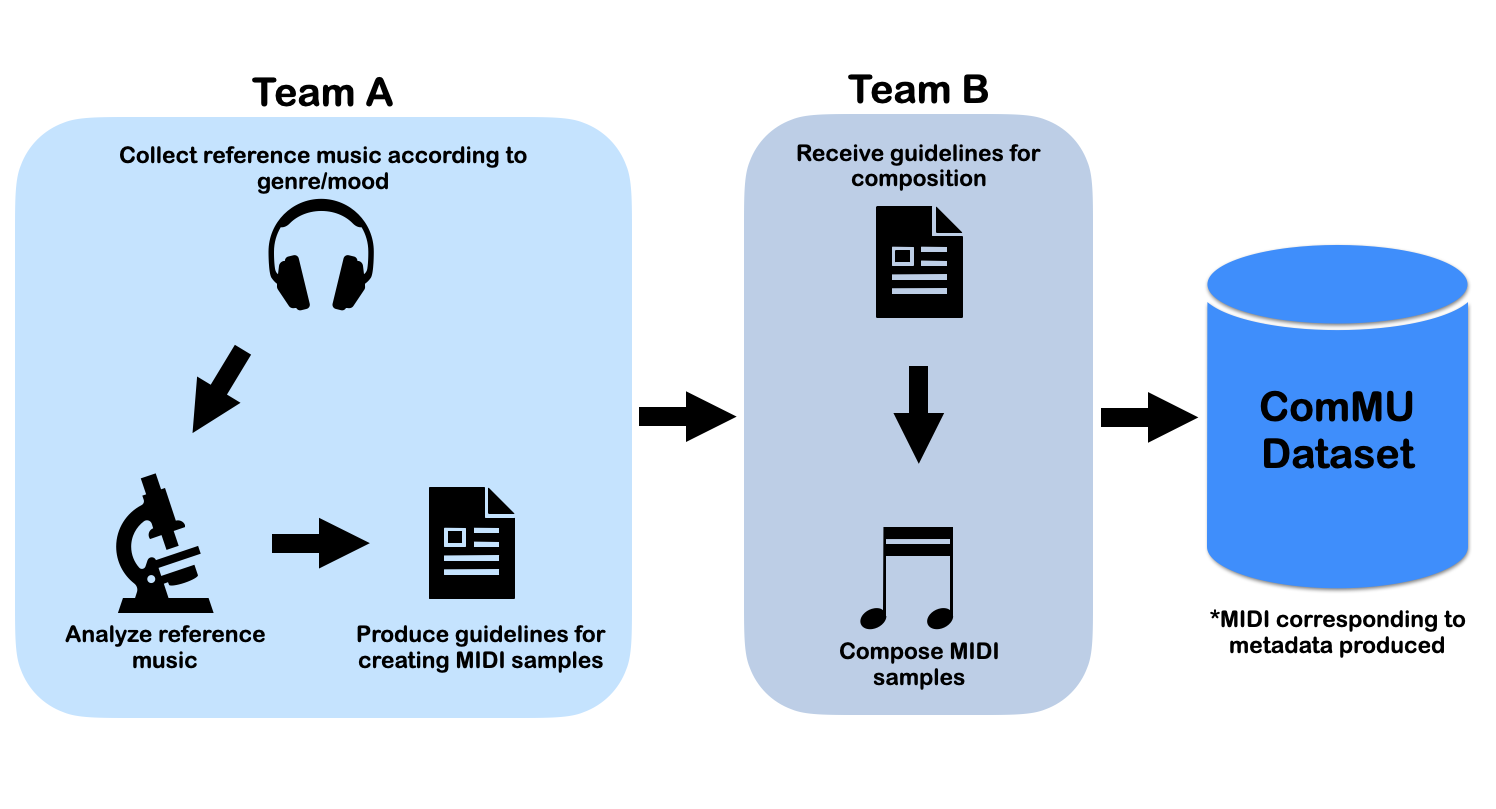
This is the repository of ComMU : Dataset for Combinational Music Generation. It is composed of midi dataset, and codes involving training & generation utilizing the autoregressive music generation model. The dataset contains 11,144 MIDI samples written and created by professional composers. They consist of short note sequences(4,8,16 bar), and are organized into 12 different metadata. they are as follows: BPM, Genre, Key, Track-instrument, Track-role, Time signature, Pitch range, Number of Measures, Chord progression, Min Velocity, Max Velocity, Rhythm. and additional document and dataset are showed below.
- Note : This Project requires python version
3.8.12. Set the virtual environment if needed.
- Clone this repository
- Install required packages
pip install -r requirements.txt
- download csv with meta information and zipped raw midi files.
- csv file consists of meta information of each midi file.
- unzip midifiles(
commu_midi.tar).and if the project tree looks like this, it is ready for preprocessing.$ cd ComMU-code $ tar -xvf ./dataset/commu_midi.tar -C ./dataset/. ├── commu_meta.csv └── commu_midi └── train └── raw └── midifiles(.mid) └── val └── raw └── midifiles(.mid)
-
ComMU dataset can be preprocessed by specifying the root directory and csv file path containing metadata.
$ python3 preprocess.py --root_dir ./dataset/commu_midi --csv_path ./dataset/commu_meta.csv -
After successful preprocessing, project tree would be like this,
. ├── commu_meta.csv └── commu_midi ├── train │ ├── raw │ ├── augmented_tmp │ ├── augmented │ └── npy_tmp ├── val │ ├── raw │ ├── augmented_tmp │ ├── augmented │ └── npy_tmp └── output_npy ├── input_train.npy ├── input_val.npy ├── target_train.npy └── target_val.npy -
Training input is related to
output_npydirectory. it contains input/target array splitted into training/validation. -
here is the additional explanation of train/val directory:
raw: splitted raw midi fileaugmented: augmented data by key_switch and bpm change.- file name looks like this, representing audio_key and bpm info :
commu11144_gmajor_70.mid
- file name looks like this, representing audio_key and bpm info :
augmented_tmp: contains temporary augmented data.npy_tmp: temporary numpy array containing Encoded Output. categorized into numbered subdirectories(ex) 0000~0015), and each directory has numpy array of each midi data.
$ python3 -m torch.distributed.launch --nproc_per_node=4 ./train.py --data_dir ./dataset/commu_midi/output_npy --work_dir {./working_direcoty}
- generation involves choice of metadata, regarding which type of music(midi file) we intend to generate. the example of command is showed below.
$ python3 generate.py \ --checkpoint_dir {./working_directory/checkpoint_best.pt} \ --output_dir {./output_dir} \ --bpm 70 \ --audio_key aminor \ --time_signature 4/4 \ --pitch_range mid_high \ --num_measures 8 \ --inst acoustic_piano \ --genre newage \ --min_velocity 60 \ --max_velocity 80 \ --track_role main_melody \ --rhythm standard \ --chord_progression Am-Am-Am-Am-Am-Am-Am-Am-G-G-G-G-G-G-G-G-F-F-F-F-F-F-F-F-E-E-E-E-E-E-E-E-Am-Am-Am-Am-Am-Am-Am-Am-G-G-G-G-G-G-G-G-F-F-F-F-F-F-F-F-E-E-E-E-E-E-E-E \ --num_generate 3
ComMU dataset is released under Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0). It is provided primarily for research purposes and is prohibited to be used for commercial purposes.