Logging
const { logging } = require('@proceed/machine');
const configObject = {
processID: 123,
fileName: 'processFileName',
moduleName: 'DISTRIBUTION',
consoleOnly: false
};
const logger = logging.getLogger(configObject);
// after 'config.init()' in core/module.js
logger.info('My log message!');Any component can now request a logger using the Logging class’ getLogger(configObject) function. This is done by specifying the type of logger needed in an object, and passing it to the getLogger(configObject) function as follows.
The Logger class implements multiple methods, which are trace, debug, info, warn, err and fatal. An additional general log function log(obj) exists, which does not correspond to
a log level, but rather receives an object containing the level, message and optionally additional
information, and then calls the according function.
logger.log( {
level: 'info',
moduleName: 'distribution',
msg: 'My log message!'
} );The logging function are async function, so if you need to wait until the log message is actually written to the log, you can use promises or await inside an async function.
| level | description |
|---|---|
| fatal | A severe error that will prevent the application from continuing. |
| error | An error in the application, possibly recoverable. |
| warn | An event that might possibly lead to an error. |
| info | An event for informational purposes. |
| debug | A general debugging event. |
| trace | A fine-grained debug message, typically capturing the flow through the application. |
From Alex BA:
The log rotation is the part of the logging module that limits the number of logs that are saved to the machines’s persistent memory. Generally, this is done by comparing the meta-data of log tables to values defined in the rotation’s configuration, and deciding based upon those comparisons, if a table should be rotated out (i.e. deleted or archived).
Usually, the rotation is initialized based on time, or on file size. PROCEED’s rotation configuration relates closely to log4j’s, with the significant difference that it is not possible to perform any tasks based on file size. Instead, the logs in a log table are counted, and a maximum value for this count can be set through the configuration, which replaces the size based rotation.
There are four configuration keys used to configure the log rotation. One for setting the rotation’s frequency, one for configuring the rotation of logs that are not related to a process executed by the engine, and two for process logs.
The parameter rotationInterval is used to define the interval at which the log rotation is triggered. maxStandardLogEntries is an integer value, which denotes the maximum number of log entries (i.e. persistently saved logs which have been made by calling a logger’s log functions, for example logger.info(...)) that are saved in the table used for storing logs that are not process related. Once this value is reached and the rotation is triggered, the table storing the logs will be deleted. New logs will then be written to a new table. This means that only a single table containing non-process related log entries will exist.
On the other hand, two configuration parameters exist for the rotation of process related logs.
maxLogEntries and maxProcessLogTables. The first parameter is used to set the maximum
number of log entries that may exist in a process related log table. Once this number is exceeded, a new table will be created, where subsequent logs will be stored.
Contrary to the procedure for rotating non-process related tables, the old table will not be deleted immediately.
Instead, the rotation process compares the number of tables existing for a particular process to the maxProcessLogTables parameter. As long as the number is smaller, no action is taken.
Once the maxProcessLogTables is exceeded at the time of log rotation, as many files will be
deleted, as are necessary to satisfy the condition that the number of tables for a process should be smaller than the aforementioned configuration parameter.
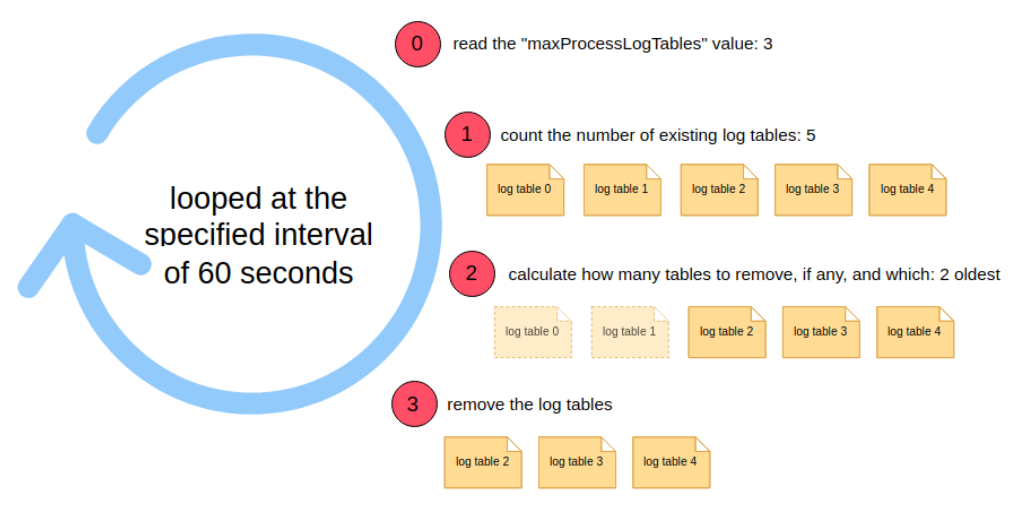
For example, the maxProcessLogTables key may be set to the value 3, with the log rotation being triggered once a minute, which is configured by setting rotationInterval to 60. For the purpose of this example, an average of two and a half log tables are said to be created every minute for a single process. In the first minute, 2 log tables are created before the log rotation is triggered. Then, the number of tables is compared to the maxProcessLogTables. As 2 is smaller than 3, no tables will be deleted. In the next minute, another 3 log tables are be created before the rotation is triggered. Again, the number of tables is compared to the
maxProcessLogTables. Now 5 tables exist. To satisfy the condition that the number of tables
has to be smaller or equal to maxProcessLogTables, the rotation rolls over (deletes) the two
tables that have been existing for the longest time. After the rotation is complete, only three
tables will exist.
The reason for allowing multiple tables for process related logs, but only one for logs that are not related to a process, is the assumption that a lot more logs will be made in the scope of process execution than there will be made for unrelated tasks. For example, a process activity’s start, end, termination, cancellation (and more) can be logged. As a business process consists of a multitude of activities, and can be executed numerous times, the number of logs that can accumulate will be vastly higher than logs made by other parts of PROCEED, such as logs made for HTTP requests and database tasks. Having multiple log tables instead of a single one makes it easier to find logs for specific process instances.
The last subsection mentions the existence of a table in which meta-data about the log tables is saved. This section aims to explain the existence of that table, which is needed for the log rotation to work.
An algorithm used to rotate a set of log tables has to have access to the following information:
- The number of tables (in this implementation, files) that exist for a certain process. This is imperative for deleting the oldest files once a certain number is reached.
- The number of logs contained in a log table, so that once a certain number is reached, a new table can be created.
- Every process-log table has its unique identifier, which is an integer-ID prepended to the table’s name. To be able to continue this ID, the latest one has to be saved. When a new table is created, the ID is increased by one and set as the new ID.
Looking at the Data module, it can be seen that it provides three functions:
read(key, options)write(key, value, options)delete(key, options)
For each of those functions to be usable, the key (name) of the table that is to be read, written to or deleted, has to be known. There is however, no function that returns a list of table-keys, where the keys match a given pattern (e.g. one that would match all tables used for storing process logs for a specific process-ID). This means that a list of all tables that would have been returned by such a function, has to be stored in a separate table, which is dedicated to keeping track of all created log tables.
This table is called the config_data table and stores all meta-data necessary for the log rotation. It tracks the number of logs that are not process-related, using the key standardLogs.
The second key processLogs, is used to identify a list of meta-data about each individual process. For each process, four values are stored. id is used to match the meta-data to a specific
process-ID. fileName is used to link the logs to the file that contains the process which we need to be able to access the correct logs via the REST endpoints. tables is a counter, keeping track of how many log-tables currently exist for the
given process-ID. The third value is currentLogs, which keeps track of the number of logs in
the most recent log-table. Strictly speaking, storing this value is not necessary. In theory, the
latest log-table can be read and its logs counted. As this would involve a lot more calculations
and resources (CPU, RAM), currentLogs is used as a solution that only requires reading the
meta-data table, increasing the counter by one, and storing the resulting data once a log entry
is made. The same reasoning is the basis for having the standardLog counter. Lastly, the
currentTableID is used to identify the table that logs are currently being written to.
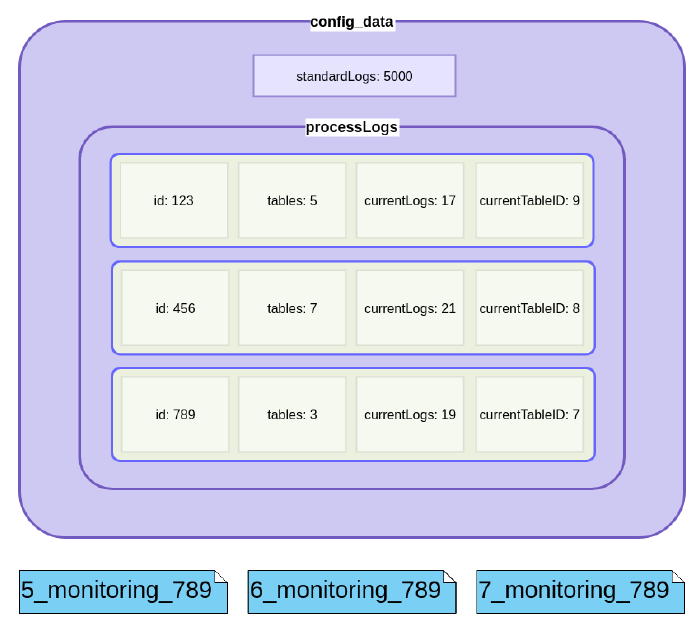
In this example, there currently are 5000 logs, which are not related to any business process. The process with the id 789 currently has three tables dedicated to its logs, and has had eight in total (IDs starting at 0), with five of them already having been rotated out, and three re- maining. The last information can be accessed through the value for tables, which is 3. The table that logs are currently being added to for process 789, is the table with the ID 7, as can be seen by currentTableID, which is 7. The tables with the IDs 5 and 6 have already reached the maximum number of logs allowed in a log table, while the table with the ID of 7 cur- rently contains 19 logs, which is the value stored in the currentLogs field. Once the table reaches the number of logs specified in the maxLogEntries key of the configuration, a new table named 8_monitoring_789 will be created. The values for tables will be increased by one and currentTableID will be set to 8. Additionally, currentLogs will be set to 0, as the new table will not yet contain any log entries.
Most, if not all existing implementations for log rotation provide the possibility to rotate logs based on time. With time based rotation, three approaches exist that could be taken when realizing it.
First, it is possible to specify the time of day that the log tables would be rolled over. The advantage of this approach is its simplicity. The time of day would be specified in the configu- ration, and the rotation then triggered in 24 hour intervals starting from the first time that the defined time of day occurs. It would not be necessary to check conditions for each table, such as is the case with size based rotation. At the given time, the tables would simply be rolled over. There is, however, a drawback to the simplicity. Having a set time for the rotation, where it is guaranteed that all tables will be rolled over, would mean that it is highly likely that tables containing relatively few logs will still be rotated out. For example, the rotation could be trig- gered each day at 12am. Deploying and executing a process at 11:58am would create a table used for all instances of that process. If the process instance takes two minutes to complete, a table containing a single process instance’s logs would be rolled over. In the event that instantiating the process at this time is a regular occurrence, each instance would create its own log table. Setting the maxProcessLogTables configuration to 10 would then mean that only the logs for ten process instances could exist at once, which might not be enough to debug a scarcely appearing error.
The second approach is a more configurable variation of the first one. Here, a fixed interval at which log tables will be rolled over is set. Instead of having them roll over at a set time at a 24 hour interval, it can be specified that logs are rotated out every five hours, starting at a defined time. Being able to set the rotation’s start time can solve the problem outlined above for some processes, but create it for others.
Both approaches are for example used to rotate logs made by the Java Virtual Machine when using IBM’s WebSphere Application Server [52].
The reason why both approaches work for Websphere, but not for PROCEED, is the fact that only a small number of log files exist, for which the rotation time and interval can be set individually by specifying the file that is to be configured. In the context of PROCEED, this is not feasible, as the number of log tables is dynamic, as new processes can be added to the system at any time. Specifying the rotation time for each process log table would entail too much work and might exceed the technical qualifications of someone tasked with modeling and deploying processes.
The problem above could be solved by allowing the possibility to specify frequency groups for processes, with each group having its own rotation times. For example, the groups "hourly" "daily" and "monthly" could exist, with the containing processes being executed as frequently as the names would suggest. A small business might have a process for receiving orders, which is triggered each hour. At the end of each day, a process describing a big shipment is executed, and at the end of each month, the inventory could be taken. When deploying the process, the group may then be supplied. Logs for the process group "hourly" could then be set to rotate once every three days, the "daily" group once every two weeks, and the "yearly" group at an interval of five years. Depending on the context the engine is run in, a small number of different groups could be specified upon first installing it. For example, processes may be instantiated at intervals of a second. The time, at which a group has last been rotated would be saved in a table containing meta-data about the rotation. Such a table already exists, and is described in detail in the next section.
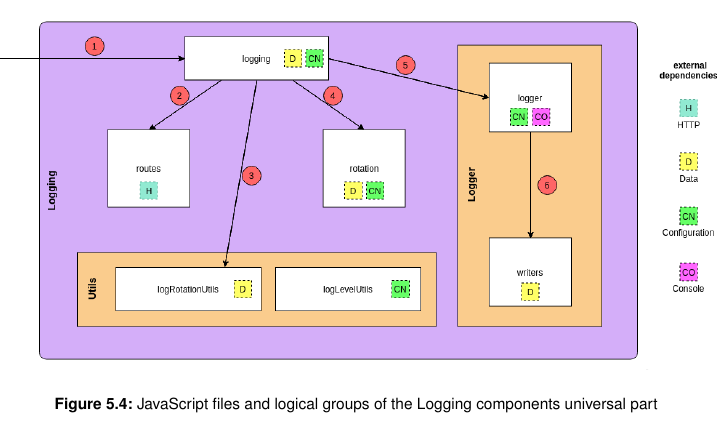
The illustration above shows an overview of the relatively complex structure of the universal
logging component. The following segment explains each code file using a simple example,
which is the component being initialized, a logger being requested by a different module, and
finally the logger being used to log a simple log.
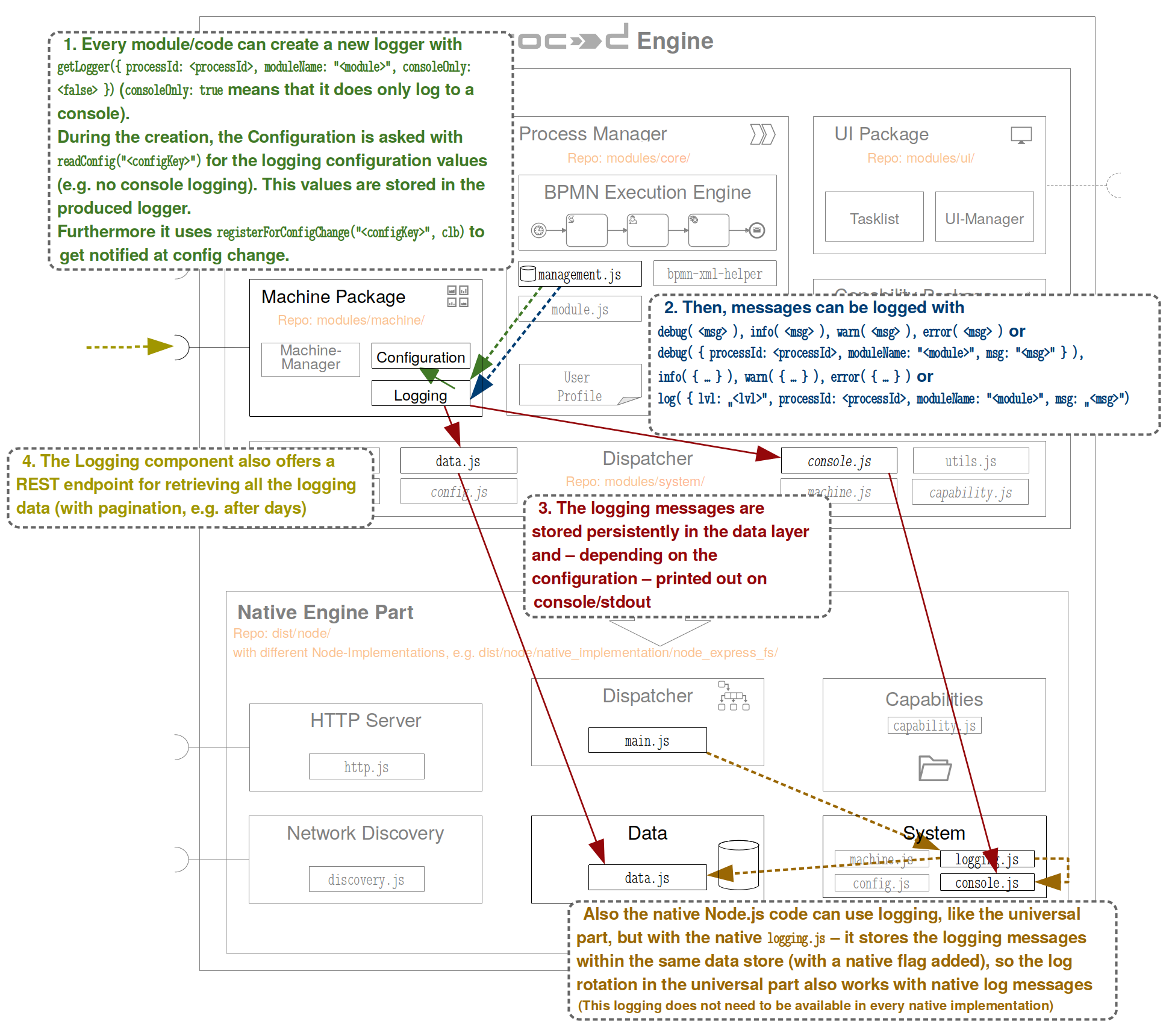
When PROCEED is started up, the Logging component is initialized through the logging.js(1). The file contains the Logging class, which is the entry point for both initializing the logging
as a whole, and for creating loggers. It has two pivotal functions: init() and getLogger(configObject).
Initializing the component entails calling the class’ init() method. It registers REST endpoints
for fetching stored logs (2) and checks if the config_data table exists, and creates it if necessary.
When this is done, it initializes the logRotationUtils (explained later on) (3), and starts the
log rotation (4).
When a new instance of the Logger class is created, it compiles list of all functions that are to be called by the individual log level methods. Which functions are added to the logger is based on the its configuration.


The _init function uses the Configuration component (see line 4) and the consoleOnly pa- rameter to decide whether or not do add a function, which prints logs to the console, to the list of functions executed by each log method. Then, the same is done for a writer function, which is used to store logs persistently. When any log method is called (e.g. processLogger.info()), it executes all functions con- tained in the functionsForWriter list For the purpose of this example, the forwardToConsole parameter, read by the Configuration component, is set to ’true’, and the consolePrinter is added to the list of functions, which means that all logs will be printed to the console if they meet the minimum log level. The writer functions themselves are managed in the writers.js, which exports a function returning the appropriate writer for the current logger configuration (6). If a general logger is created, the standardWriter function is returned, and if a process logger is requested, the splitWriter function is returned. The implementation for the standardWriter is simple. It uses the logLevelUtils, which contains utility functions related to log levels, such as log level comparison, to receive a func- tion, which acts as a guard to levels below a configured level. If the log call is not made with a high enough level, the guard doesn’t let the call through, and the log is not persistently saved. Should the log message pass the logGuard and is persistently written to the storage, an instance of the RotationUtils class is used to increase the counter for standard logs in the config_default.

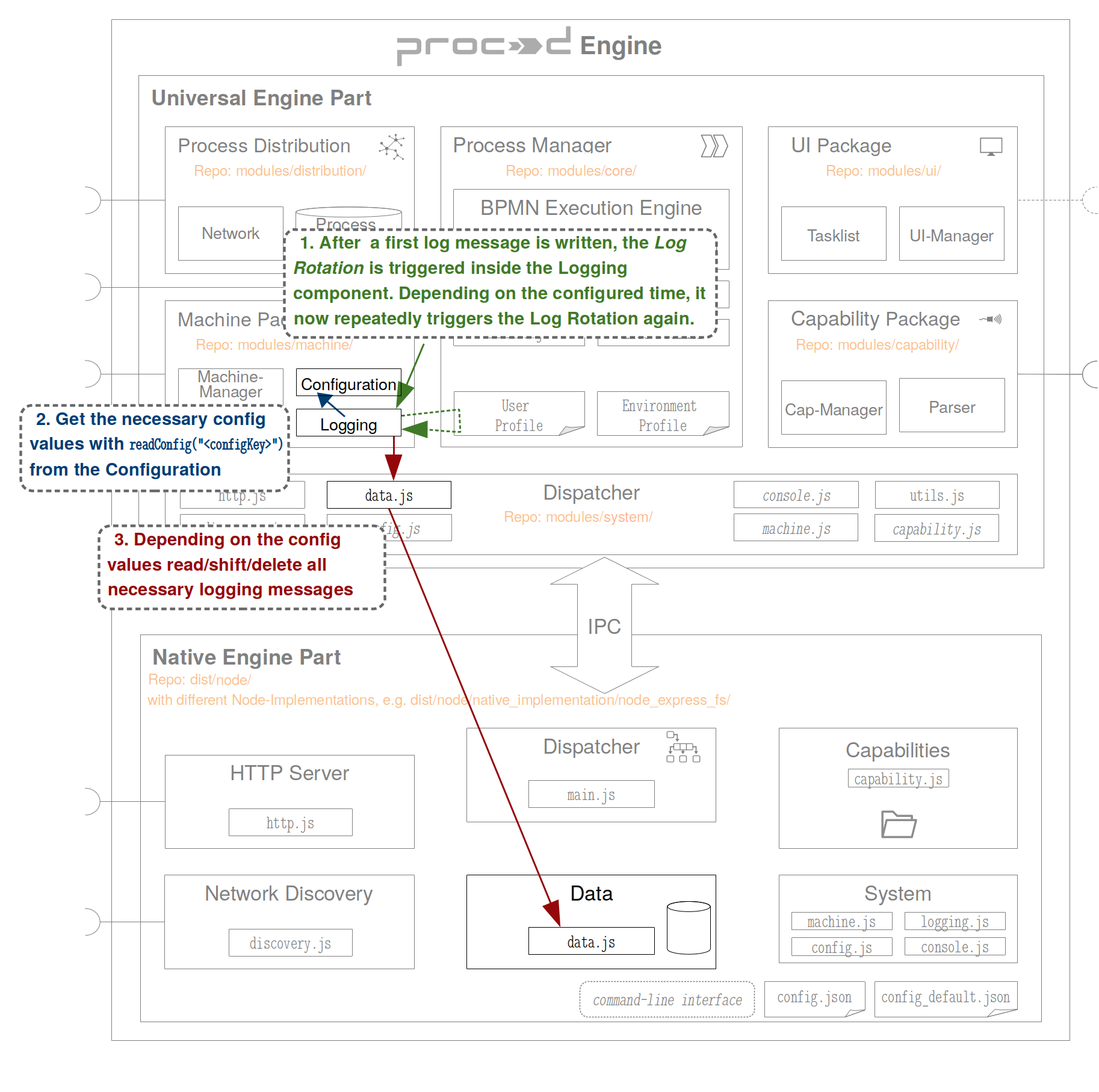
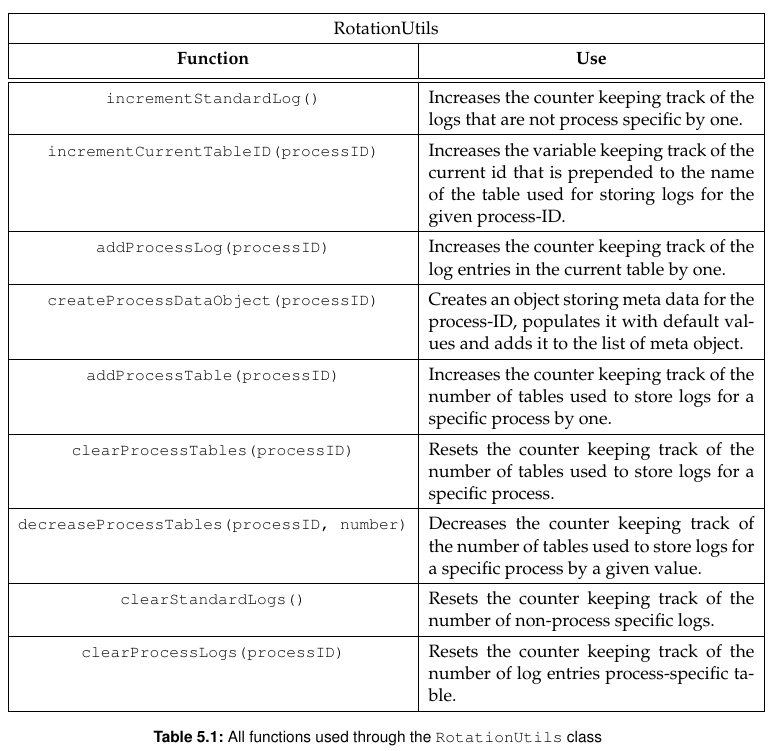
Before explaining the process for requesting a splitWriter, it makes sense to explain the RotationUtils class in more detail, as it is heavily used.
The class is situated in the logRotationUtils.js and serves the purpose of making changes to the config_data table. Any change made to that table is made through the RotationUtils, which accordingly implements functions for any change that can be made.
The splitWriter’s implementation is somewhat more complex than the standardWriter’s. The reason for that is the fact that depending on the process-ID passed upon logger instantia- tion, the splitWriter has to store logs in a different table. In addition to that, only one table exists to store standard logs, but multiple can exist to store process logs. This logic has to be included in the splitWriter, as it should store logs in a newly created table once the current one is full. To accomplish that, all necessary meta data stored for the provided process-ID is read by the outer function containing and returning the splitWriter. This includes the currentTableID, indicating which table logs should be added to, and currentLogs, which is the counter keep- ing track of the number of logs in that table.

When a process log is made, the number of currently existing logs is compared to the number of logs which may at most exist in the log table with the currentTableID. If there is room for more logs, the message is added to the log table (line 18), and the local and persistent log counter increased by one. If the maximum number of logs has been reached, currentTableID is increased by one both locally and in the meta data table (line 7 and 9), and the latter’s table counter is also updated to account for the new table that will be created (line 8). As logs will be written to a new empty table, logNumber is reset, once again both locally and in the config_data. Returning back to the example of creating and using a logger, once a writer function is returned, the proceed logger is ready to use. Any log function,such as the info, can now be called.

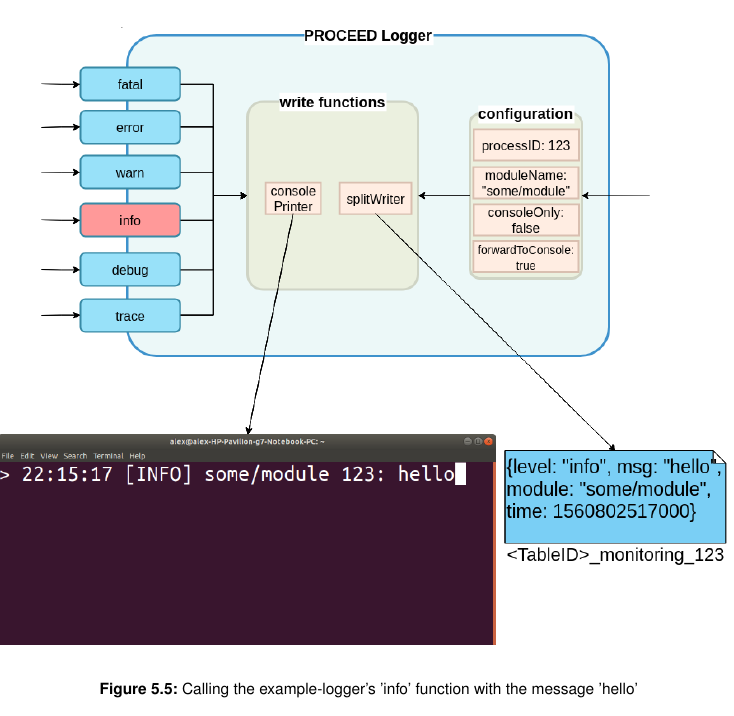
The info(msg) method’s implementation can be seen above. As the logger is initialized in an asynchronous way, it waits until the the logger has been set up so that no errors occur in the following code execution, prepares the log message and then calls all functions that have been configured to be executed once a log message is called. The handleLog(log, level) function is necessary, as logs can be made in the form of strings or objects. If a string is passed to the log method, it has to be wrapped in an object containing all necessary information. If an object is passed to the log method, additional data is added to it, such as the log level that was used to create the log, and a timestamp. Figure 5.4 illustrates the processLogger being called as follows: processLogger.info(’ hello’), with the object-call alternatives being processLogger.log({’info’, ’hello’}) or processLogger.info({msg: ’hello’}).