TesnorRT Survey
NVIDIA TensorRT is a high-performance deep learning inference library for production environments. It automatically optimizes trained neural networks for run-time performance, delivering up to 16x higher energy efficiency (performance per watt) on a Tesla P100 GPU compared to common CPU-only deep learning inference systems.
The newest version of TensorRT is TensorRT3. However, for the lack of the newest document, this survey will focus on TensorRT2.
TensorRT performs several important transformations and optimizations to the neural network graph.
First, layers with unused output are eliminated to avoid unnecessary computation. Next, where possible convolution, bias, and ReLU layers are fused to form a single layer. Figure 2 shows the result of this vertical layer fusion on the original network from Figure 1 (fused layers are labeled CBR in Figure 2). Layer fusion improves the efficiency of running TensorRT-optimized networks on the GPU.
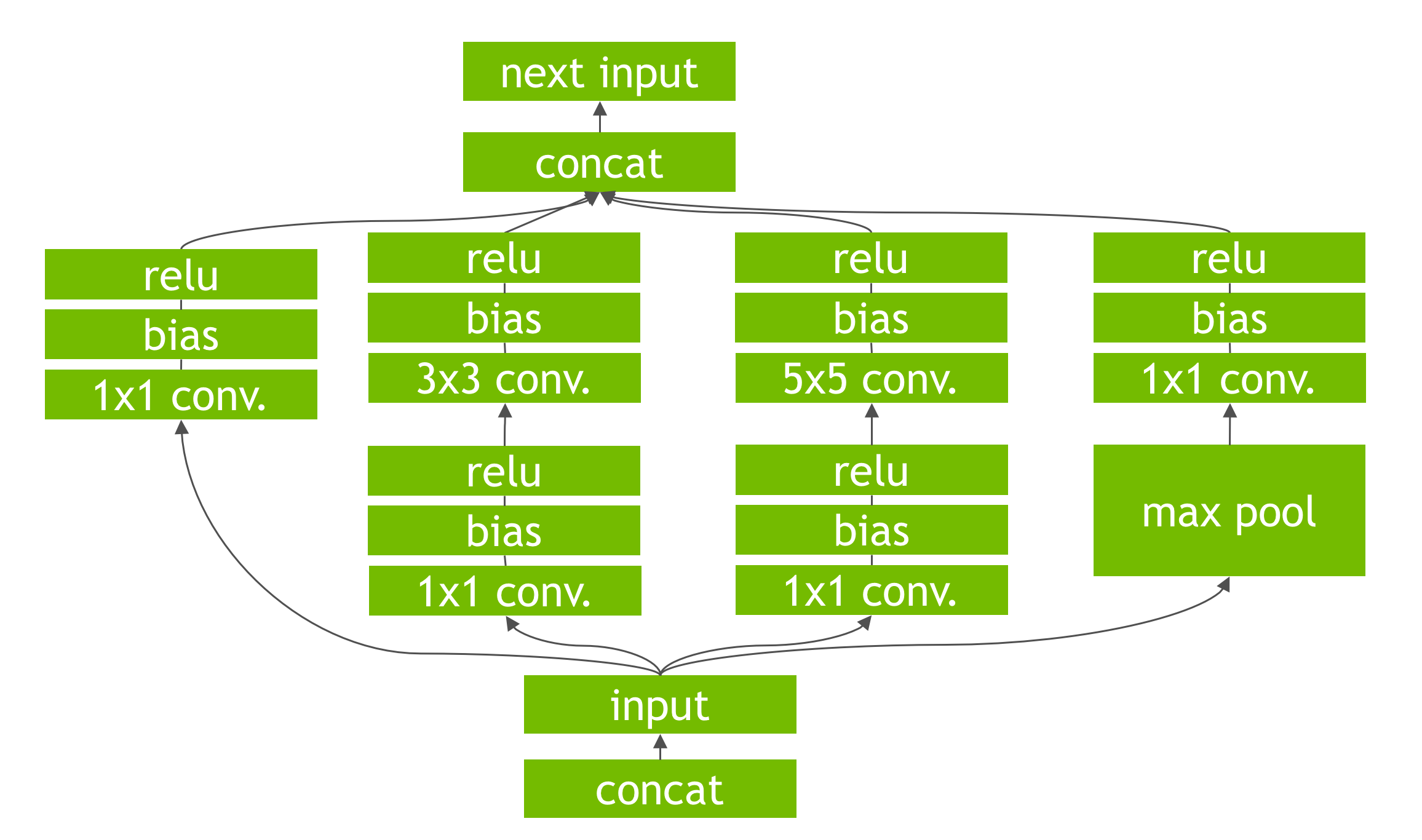
Figure 1: An example convolutional neural network with multiple convolutional and activation layers.

Figure 2: The result of vertical layer fusion on the network showed in Figure 1.
Another transformation is horizontal layer fusion, or layer aggregation, along with the required division of aggregated layers to their respective outputs, as Figure 3 shows. Horizontal layer fusion improves performance by combining layers that take the same source tensor and apply the same operations with similar parameters, resulting in a single larger layer for higher computational efficiency.

Figure 3: The result after the combination of 3 1×1 CBR layers from Figure 2 that take the same input into a single larger 1×1 CBR layer. Note that the output of this layer must be disaggregated to feed into the different subsequent layers from the original input graph.
There are two phases in the use of TensorRT: build and deployment.
In the build phase, TensorRT performs optimizations on the network configuration and generates an optimized plan(maybe a .a file) for computing the forward pass through the deep neural network.
In the deployment phase, TensorRT takes batches of input data, performs inference by executing the plan and returns batches of output data. With TensorRT you don’t need to install and run a deep learning framework for the deployment hardware.
TensorRT supports Caffe will, the optimized plan can be built through Caffe model files:
- A network architecture file (deploy.prototxt)
- Trained weights (net.caffemodel)
- A label file to provide a name for each output class
The following code shows how to convert a Caffe model to a TensorRT object:
IBuilder* builder = createInferBuilder(gLogger);
// parse the caffe model to populate the network, then set the outputs
INetworkDefinition* network = builder->createNetwork();
CaffeParser parser;
auto blob_name_to_tensor = parser.parse(“deploy.prototxt”,
trained_file.c_str(),
*network,
DataType::kFLOAT);
// specify which tensors are outputs
network->markOutput(*blob_name_to_tensor->find("prob"));
// Build the engine
builder->setMaxBatchSize(1);
builder->setMaxWorkspaceSize(1 << 30);
ICudaEngine* engine = builder->buildCudaEngine(*network);We can also use the TensorRT C++ API to define the network without the Caffe parser:
ITensor* in = network->addInput(“input”, DataType::kFloat, Dims3{…});
IPoolingLayer* pool = network->addPooling(in, PoolingType::kMAX, …);Following layers are supported by TensorRT2:
- Convolution: 2D
- Activation: ReLU, tanh and sigmoid
- Pooling: max and average
- ElementWise: sum, product or max of two tensors
- LRN: cross-channel only
- Fully-connected: with or without bias
- SoftMax: cross-channel only
- Deconvolution
The inference builder (IBuilder) buildCudaEngine method returns a pointer to a new inference engine runtime object (ICudaEngine). This runtime object is ready for immediate use; alternatively, its state can be serialized and saved to disk or to an object store for distribution. The serialized object code is called the Plan.
The following code showes the steps required to use the inference engine to process a batch of input data to generate a result:
// The execution context is responsible for launching the
// compute kernels
IExecutionContext *context = engine->createExecutionContext();
// In order to bind the buffers, we need to know the names of the
// input and output tensors.
int inputIndex = engine->getBindingIndex(INPUT_LAYER_NAME),
int outputIndex = engine->getBindingIndex(OUTPUT_LAYER_NAME);
// Allocate GPU memory for Input / Output data
void* buffers = malloc(engine->getNbBindings() * sizeof(void*));
cudaMalloc(&buffers[inputIndex], batchSize * size_of_single_input);
cudaMalloc(&buffers[outputIndex], batchSize * size_of_single_output);
// Use CUDA streams to manage the concurrency of copying and executing
cudaStream_t stream;
cudaStreamCreate(&stream);
// Copy Input Data to the GPU
cudaMemcpyAsync(buffers[inputIndex], input,
batchSize * size_of_single_input,
cudaMemcpyHostToDevice, stream);
// Launch an instance of the GIE compute kernel
context.enqueue(batchSize, buffers, stream, nullptr);
// Copy Output Data to the Host
cudaMemcpyAsync(output, buffers[outputIndex],
batchSize * size_of_single_output,
cudaMemcpyDeviceToHost, stream));
// It is possible to have multiple instances of the code above
// in flight on the GPU in different streams.
// The host can then sync on a given stream and use the results
cudaStreamSynchronize(stream);