Baselines of grid dispatching competition #709
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,7 @@ | ||
| ## Baselines for grid dispatching competition | ||
|
|
||
| Competition link: [国家电网调控AI创新大赛:电网运行组织智能安排](https://aistudio.baidu.com/aistudio/competition/detail/111) | ||
|
|
||
| We provide a distributed SAC baseline based on PARL with paddlepaddle or torch: | ||
| - [paddlepaddle baseline](paddle) | ||
| - [torch baseline](torch) | ||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,61 @@ | ||
| ## SAC baseline for grid dispatching competition | ||
zenghsh3 marked this conversation as resolved.
Show resolved
Hide resolved
|
||
|
|
||
| In this example, we provide a distributed SAC baseline based on PARL and paddlepaddle for the [grid dispatching competition](https://aistudio.baidu.com/aistudio/competition/detail/111) task. | ||
|
|
||
| ### Dependencies | ||
| * Linux | ||
| * python3.6+ | ||
| * paddlepaddle >= 2.1.0 | ||
| * parl >= 2.0.0 | ||
|
|
||
| ### Computing resource requirements | ||
| * 1 GPU + 6 CPUs | ||
|
|
||
| ### Training | ||
|
|
||
| 1. Download the pretrained model (trained with fixed first 288 timesteps data) in the current directory. (filename: `paddle_pretrain_model`) | ||
|
|
||
| [Baidu Pan](https://pan.baidu.com/s/1R-4EWIgNr2YogbJnMXk4Cg) (password: hwkb) | ||
|
|
||
| 2. Copy all files of `gridsim` (the competition package) to the current directory. | ||
| ```bash | ||
| # For example: | ||
| cp -r /XXX/gridsim/* . | ||
| ``` | ||
|
|
||
| 2. Update the data path for distributed training (Using an absoluate path). | ||
| ```bash | ||
| export PWD=`pwd` | ||
|
There was a problem hiding this comment. this line does not support the There was a problem hiding this comment. Added Linux dependency. |
||
| python yml_creator.py --dataset_path $PWD/data | ||
| ``` | ||
|
|
||
|
|
||
| 3. Set the environment variable of PARL and gridsim. | ||
| ```bash | ||
| export PARL_BACKEND=paddle | ||
| export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:./lib64 | ||
| ``` | ||
|
|
||
| 4. Start xparl cluster | ||
|
|
||
| ```bash | ||
| # You can change following `cpu_num` and `args.actor_num` in the train.py based on the CPU number of your machine. | ||
| # Note that you only need to start the cluster once. | ||
|
|
||
| xparl start --port 8010 --cpu_num 6 | ||
| ``` | ||
|
|
||
|
There was a problem hiding this comment. Note that you only need to start the cluster once. |
||
| 5. start training. | ||
|
|
||
| ```bash | ||
| python train.py --actor_num 6 | ||
| ``` | ||
|
|
||
| 6. Visualize the training curve and other information. | ||
| ``` | ||
| tensorboard --logdir . | ||
| ``` | ||
|
|
||
| ### Performance | ||
| The result after training one hour with 1 GPU and 6 CPUs. | ||
| 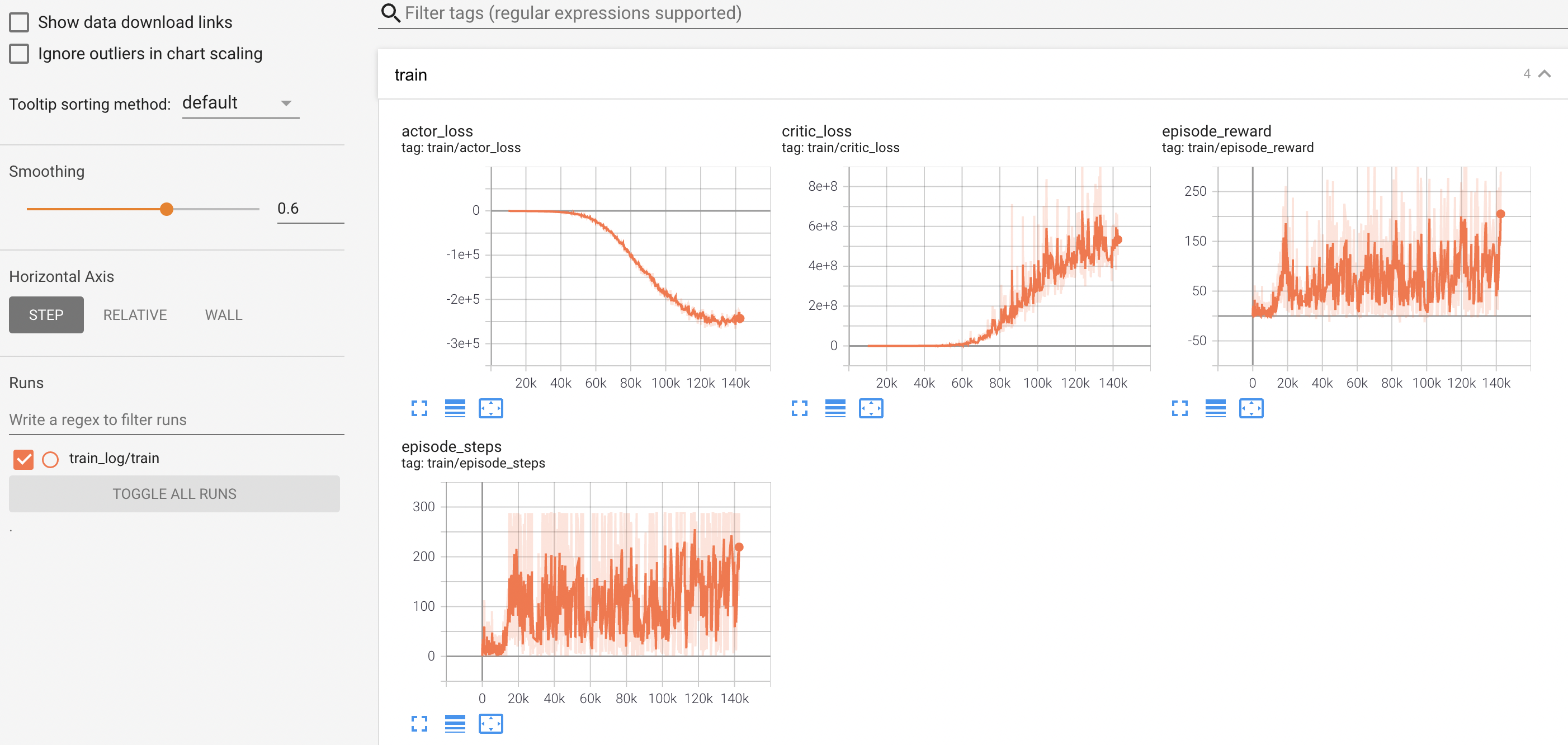 | ||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,153 @@ | ||
| # Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved. | ||
| # | ||
| # Licensed under the Apache License, Version 2.0 (the "License"); | ||
| # you may not use this file except in compliance with the License. | ||
| # You may obtain a copy of the License at | ||
| # | ||
| # http://www.apache.org/licenses/LICENSE-2.0 | ||
| # | ||
| # Unless required by applicable law or agreed to in writing, software | ||
| # distributed under the License is distributed on an "AS IS" BASIS, | ||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | ||
| # See the License for the specific language governing permissions and | ||
| # limitations under the License. | ||
|
|
||
| import gym | ||
| import numpy as np | ||
| from parl.utils import logger | ||
| from Environment.base_env import Environment | ||
| from utilize.settings import settings | ||
| from utilize.form_action import * | ||
|
|
||
|
|
||
| class MaxTimestepWrapper(gym.Wrapper): | ||
| def __init__(self, env, max_timestep=288): | ||
| logger.info("[env type]:{}".format(type(env))) | ||
| self.max_timestep = max_timestep | ||
| env.observation_space = None | ||
| env.reward_range = None | ||
| env.metadata = None | ||
| gym.Wrapper.__init__(self, env) | ||
|
|
||
| self.timestep = 0 | ||
|
|
||
| def step(self, action, **kwargs): | ||
| self.timestep += 1 | ||
| obs, reward, done, info = self.env.step(action, **kwargs) | ||
| if self.timestep >= self.max_timestep: | ||
| done = True | ||
| info["timeout"] = True | ||
| else: | ||
| info["timeout"] = False | ||
| return obs, reward, done, info | ||
|
|
||
| def reset(self, **kwargs): | ||
| self.timestep = 0 | ||
| return self.env.reset(**kwargs) | ||
|
|
||
|
|
||
| class ObsTransformerWrapper(gym.Wrapper): | ||
| def __init__(self, env): | ||
| logger.info("[env type]:{}".format(type(env))) | ||
| gym.Wrapper.__init__(self, env) | ||
|
|
||
| def _get_obs(self, obs): | ||
| # loads | ||
| loads = [] | ||
| loads.append(obs.load_p) | ||
| loads.append(obs.load_q) | ||
| loads.append(obs.load_v) | ||
| loads = np.concatenate(loads) | ||
|
|
||
| # prods | ||
| prods = [] | ||
| prods.append(obs.gen_p) | ||
| prods.append(obs.gen_q) | ||
| prods.append(obs.gen_v) | ||
| prods = np.concatenate(prods) | ||
|
|
||
| # rho | ||
| rho = np.array(obs.rho) - 1.0 | ||
|
|
||
| next_load = obs.nextstep_load_p | ||
|
|
||
| # action_space | ||
| action_space_low = obs.action_space['adjust_gen_p'].low.tolist() | ||
| action_space_high = obs.action_space['adjust_gen_p'].high.tolist() | ||
| action_space_low[settings.balanced_id] = 0.0 | ||
| action_space_high[settings.balanced_id] = 0.0 | ||
|
|
||
| features = np.concatenate([ | ||
| loads, prods, | ||
| rho.tolist(), next_load, action_space_low, action_space_high | ||
| ]) | ||
|
|
||
| return features | ||
|
|
||
| def step(self, action, **kwargs): | ||
| self.raw_obs, reward, done, info = self.env.step(action, **kwargs) | ||
| obs = self._get_obs(self.raw_obs) | ||
| return obs, reward, done, info | ||
|
|
||
| def reset(self, **kwargs): | ||
| self.raw_obs = self.env.reset(**kwargs) | ||
| obs = self._get_obs(self.raw_obs) | ||
| return obs | ||
|
|
||
|
|
||
| class RewardShapingWrapper(gym.Wrapper): | ||
| def __init__(self, env): | ||
| logger.info("[env type]:{}".format(type(env))) | ||
| gym.Wrapper.__init__(self, env) | ||
|
|
||
| def step(self, action, **kwargs): | ||
| obs, reward, done, info = self.env.step(action, **kwargs) | ||
|
|
||
| shaping_reward = 1.0 | ||
|
|
||
| info["origin_reward"] = reward | ||
|
|
||
| return obs, shaping_reward, done, info | ||
|
|
||
| def reset(self, **kwargs): | ||
| return self.env.reset(**kwargs) | ||
|
|
||
|
|
||
| class ActionWrapper(gym.Wrapper): | ||
| def __init__(self, env, raw_env): | ||
| logger.info("[env type]:{}".format(type(env))) | ||
| gym.Wrapper.__init__(self, env) | ||
| self.raw_env = raw_env | ||
| self.v_action = np.zeros(self.raw_env.settings.num_gen) | ||
|
|
||
| def step(self, action, **kwargs): | ||
| N = len(action) | ||
|
|
||
| gen_p_action_space = self.env.raw_obs.action_space['adjust_gen_p'] | ||
|
|
||
| low_bound = gen_p_action_space.low | ||
| high_bound = gen_p_action_space.high | ||
|
|
||
| mapped_action = low_bound + (action - (-1.0)) * ( | ||
|
There was a problem hiding this comment. Why don't we use the action_mapping wrapper here? There was a problem hiding this comment. The current wrapper cannot support it. (We fix it in #673) |
||
| (high_bound - low_bound) / 2.0) | ||
| mapped_action[self.raw_env.settings.balanced_id] = 0.0 | ||
| mapped_action = np.clip(mapped_action, low_bound, high_bound) | ||
|
|
||
| ret_action = form_action(mapped_action, self.v_action) | ||
| return self.env.step(ret_action, **kwargs) | ||
|
|
||
| def reset(self, **kwargs): | ||
| return self.env.reset(**kwargs) | ||
|
|
||
|
|
||
| def get_env(): | ||
| env = Environment(settings, "EPRIReward") | ||
| env.action_space = None | ||
| raw_env = env | ||
|
|
||
| env = MaxTimestepWrapper(env) | ||
| env = RewardShapingWrapper(env) | ||
| env = ObsTransformerWrapper(env) | ||
| env = ActionWrapper(env, raw_env) | ||
|
|
||
| return env | ||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,49 @@ | ||
| # Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved. | ||
| # | ||
| # Licensed under the Apache License, Version 2.0 (the "License"); | ||
| # you may not use this file except in compliance with the License. | ||
| # You may obtain a copy of the License at | ||
| # | ||
| # http://www.apache.org/licenses/LICENSE-2.0 | ||
| # | ||
| # Unless required by applicable law or agreed to in writing, software | ||
| # distributed under the License is distributed on an "AS IS" BASIS, | ||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | ||
| # See the License for the specific language governing permissions and | ||
| # limitations under the License. | ||
|
|
||
| import parl | ||
| import paddle | ||
| import numpy as np | ||
|
|
||
|
|
||
| class GridAgent(parl.Agent): | ||
| def __init__(self, algorithm): | ||
| super(GridAgent, self).__init__(algorithm) | ||
|
|
||
| self.alg.sync_target(decay=0) | ||
|
|
||
| def predict(self, obs): | ||
| obs = paddle.to_tensor(obs.reshape(1, -1), dtype='float32') | ||
| action = self.alg.predict(obs) | ||
| action_numpy = action.cpu().numpy()[0] | ||
| return action_numpy | ||
|
|
||
| def sample(self, obs): | ||
| obs = paddle.to_tensor(obs.reshape(1, -1), dtype='float32') | ||
| action, _ = self.alg.sample(obs) | ||
| action_numpy = action.cpu().numpy()[0] | ||
| return action_numpy | ||
|
|
||
| def learn(self, obs, action, reward, next_obs, terminal): | ||
| terminal = np.expand_dims(terminal, -1) | ||
| reward = np.expand_dims(reward, -1) | ||
|
|
||
| obs = paddle.to_tensor(obs, dtype='float32') | ||
| action = paddle.to_tensor(action, dtype='float32') | ||
| reward = paddle.to_tensor(reward, dtype='float32') | ||
| next_obs = paddle.to_tensor(next_obs, dtype='float32') | ||
| terminal = paddle.to_tensor(terminal, dtype='float32') | ||
| critic_loss, actor_loss = self.alg.learn(obs, action, reward, next_obs, | ||
| terminal) | ||
| return critic_loss.cpu().numpy()[0], actor_loss.cpu().numpy()[0] |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,89 @@ | ||
| # Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved. | ||
| # | ||
| # Licensed under the Apache License, Version 2.0 (the "License"); | ||
| # you may not use this file except in compliance with the License. | ||
| # You may obtain a copy of the License at | ||
| # | ||
| # http://www.apache.org/licenses/LICENSE-2.0 | ||
| # | ||
| # Unless required by applicable law or agreed to in writing, software | ||
| # distributed under the License is distributed on an "AS IS" BASIS, | ||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | ||
| # See the License for the specific language governing permissions and | ||
| # limitations under the License. | ||
|
|
||
| import parl | ||
| import paddle | ||
| import paddle.nn as nn | ||
| import paddle.nn.functional as F | ||
|
|
||
| # clamp bounds for Std of action_log | ||
| LOG_SIG_MAX = 2.0 | ||
| LOG_SIG_MIN = -20.0 | ||
|
|
||
|
|
||
| class GridModel(parl.Model): | ||
| def __init__(self, obs_dim, action_dim): | ||
| super(GridModel, self).__init__() | ||
| self.actor_model = Actor(obs_dim, action_dim) | ||
| self.critic_model = Critic(obs_dim, action_dim) | ||
|
|
||
| def policy(self, obs): | ||
| return self.actor_model(obs) | ||
|
|
||
| def value(self, obs, action): | ||
| return self.critic_model(obs, action) | ||
|
|
||
| def get_actor_params(self): | ||
| return self.actor_model.parameters() | ||
|
|
||
| def get_critic_params(self): | ||
| return self.critic_model.parameters() | ||
|
|
||
|
|
||
| class Actor(parl.Model): | ||
| def __init__(self, obs_dim, action_dim): | ||
| super(Actor, self).__init__() | ||
|
|
||
| self.l1 = nn.Linear(obs_dim, 512) | ||
| self.l2 = nn.Linear(512, 256) | ||
| self.mean_linear = nn.Linear(256, action_dim) | ||
| self.std_linear = nn.Linear(256, action_dim) | ||
|
|
||
| def forward(self, obs): | ||
| x = F.relu(self.l1(obs)) | ||
| x = F.relu(self.l2(x)) | ||
|
|
||
| act_mean = self.mean_linear(x) | ||
| act_std = self.std_linear(x) | ||
| act_log_std = paddle.clip(act_std, min=LOG_SIG_MIN, max=LOG_SIG_MAX) | ||
| return act_mean, act_log_std | ||
|
|
||
|
|
||
| class Critic(parl.Model): | ||
| def __init__(self, obs_dim, action_dim): | ||
| super(Critic, self).__init__() | ||
|
|
||
| # Q1 network | ||
| self.l1 = nn.Linear(obs_dim + action_dim, 512) | ||
| self.l2 = nn.Linear(512, 256) | ||
| self.l3 = nn.Linear(256, 1) | ||
|
|
||
| # Q2 network | ||
| self.l4 = nn.Linear(obs_dim + action_dim, 512) | ||
| self.l5 = nn.Linear(512, 256) | ||
| self.l6 = nn.Linear(256, 1) | ||
|
|
||
| def forward(self, obs, action): | ||
| x = paddle.concat([obs, action], 1) | ||
|
|
||
| # Q1 | ||
| q1 = F.relu(self.l1(x)) | ||
| q1 = F.relu(self.l2(q1)) | ||
| q1 = self.l3(q1) | ||
|
|
||
| # Q2 | ||
| q2 = F.relu(self.l4(x)) | ||
| q2 = F.relu(self.l5(q2)) | ||
| q2 = self.l6(q2) | ||
| return q1, q2 |
Oops, something went wrong.
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
We can write in Chinese. The participants only come from China.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Some of the participants are from Portugal.